TIMi Top winner at the PAKDD 2010 cup
The objective of the 14th Pacific-Asia Knowledge Discovery and Data Mining conference (PAKDD 2010) is Re-Calibration of a Credit Risk Assessment System Based on Biased Data.
There were 3 datasets used for the Challenge. They were collected during period from 2006 to 2009, and came from a private label credit card operation of a Brazilian credit company and its partner shops.
The prediction targets to detect are the “bad” clients. A client is labeled as “bad” (target variable=1) if he/she made 60 days delay in any payment of the bills contracted along the first year after the credit has been granted. In short, the clients that do not pay their debt are labeled as “bad”.
The datasets that are available to the participants were:
- Modelling (50,000 samples). This is the only dataset where we have the “target” information (we know the “bad” clients). There are 26.08% of “bad” clients
- Leaderboard (20,000 samples). This dataset was used on the internet web-site of the competition to give instantaneous feedback about the accuracy of the different models developed by the different teams. The real-time LeaderBoard stimulates the competitors’ daily participation because everybody can see how the other teams are performing.
- Prediction (20,000 samples). This is the only dataset that was used to obtain the final ranking of the competition.
The datasets consist of 52 explanatory variables of several types.
The important aspect to emphasize is that the Modelling and Leaderboard datasets include only “approved customers”. This “approval” was computed using an old predictive model that is already in use in the bank. As a consequence, only a part of the “market” is monitored.
However, for the purpose of monitoring the decision support system’s performance and collecting data for future model re-calibration, some clients have received the credit they had applied for, even if the current decision system classified them as “bad” clients. The Prediction dataset is the only one that contains “approved” and “non-approved” customers. The percentage of targets in the Prediction dataset is thus expected to be higher than inside the Modelling and Leaderboard datasets. There is thus a large sampling bias between the data sets.
This competition thus focuses on the credit scoring model’s generalization capacity from partial biased data sets available for modeling.
The performance of the predictive model (that is used to compute the final ranking of the teams) is measured using area under the receiver operating characteristic curve (AUC) on the Prediction data set of 20,000 further accounts.
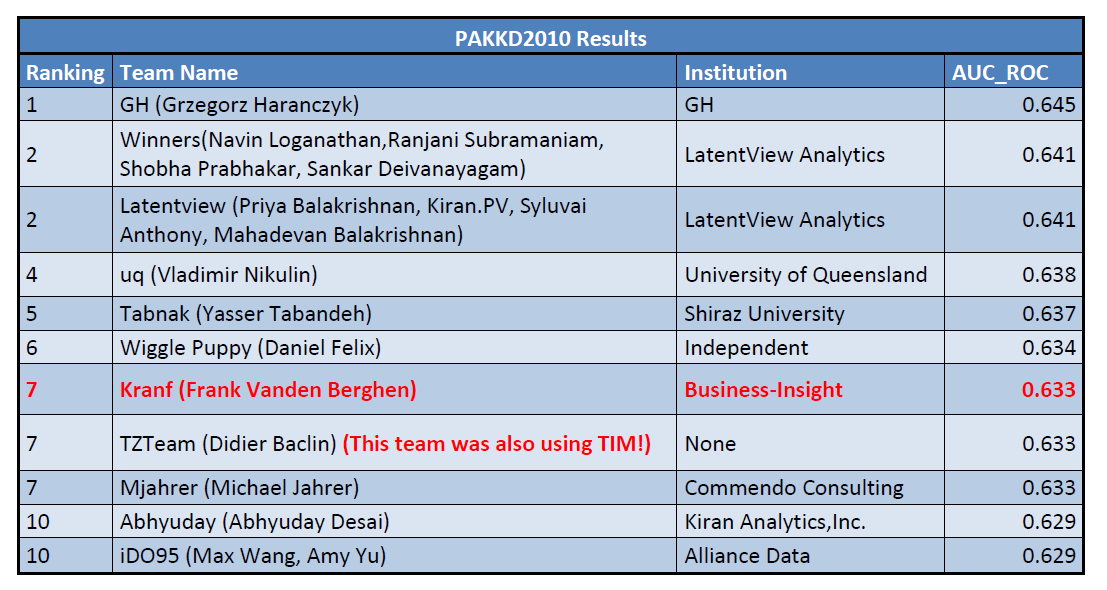
The final ranking is:
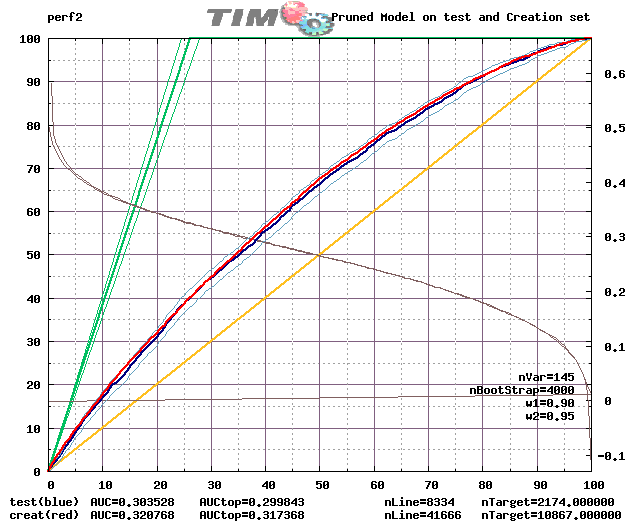
This is the lift that we obtained using TIMi:
Some remarks:
- We obtained the 7th place amongst a total of 94 teams that participated to the PAKDD 2010 world-competition.
- There are 2 users of TIMi inside the TOP 10 winners of the competition.
- Only one person (Frank Vanden Berghen) did work on the PAKDD competition and only for 1 day. Frank was using TIMi.
- Given more time, we could have “cleaned” the dataset better.In particular, it seems that one of the most important variables for prediction is the “location”. Many columns encode the “location” inside the competition datasets: “professional_borough”, “professionnal_city”, “residential_borough”, “residential_city”. Unfortunately, these variables are extremely noisy.
For example here are all the different sppling of the same city: ACHOEIRO DE ITAPEMIRIM, CACHOEIRO DE ITAPEMIRIM, CACHOEIRO D EITAPEMIRIM, CACHOEIRO D ITAPEMIRIM, CACHOEIRO DE ITAPEMIRIM, CACHOEIRO DE ITAMPEMIRIM, CACHOEIRO DE ITAPEMIRIM, CACHOEIRO DE ITPEMIRIM, CACHOEIRO ITAPEMIRIM, CACHOEIROIRA ITAPEMIRIM. We had no time to manually correct all the spelling mistakes inside these 4 variables. We have now added a new automated text-mining spelling-correction operator inside our ETL tool (Anatella) to easily cope (in a matter of minute) with such situation for the next competition.
- The competition-winning-team managed to obtain a slightly higher score than TIMi because:a. They did a better job cleaning the data (it takes time!).
b. They did work on the competition for more than 2 months.
c. More importantly: they managed to find extra-variables linked to the “location”: area, population in 2005, density in 2005, GDP, GDP per capita PPP, Human Development Index (HDI), literacy rate, infant mortality, life expectancy. These extra-variables are important because, as we have noticed ourselves the “location” concept is a very important one. - Another Team was also using TIMi as their predictive datamining tool: The “TZTeam”. The “TZTeam” is composed of only one individual: Didier Baclin. He did a very fine job on the competition despite the fact that he worked on it for less than 2 hours (from a personal communication)! The comments from Didier Baclin about the TIM software are:a. …a great piece of data analysis software…
b. TIM is a very fast and easy to use software which can be used on massive datasets to model binary or continuous outcomes just like in this PAKDD competition.
c. TIM … is fast and easy to use which makes it a great tool for exploring modeling possibilities.
d. TIM allows the use for several variable selection techniques…
e. It was easy to score the …. dataset thanks to TIMi’s built in scoring module.
This competition once again demonstrates the superior accuracy of TIMi for datamining.