Data quality
With Anatella, you can easily perform any data quality and data cleaning tasks. In opposition to other tools, the Anatella data cleaning procedures are optimized to work on large datasets (several billion rows). You can (non-limitative list):
Check the validity of character fields
For example, check for the right formats using powerful regular expressions. You can use the following Anatella operator to perform this task.
Check the validity of numeric fields
For example: you can compute means, number of unique values, look for the highest & lowest number, count the number of missings, etc.
Check for missing values
You can use the following Anatella operator to perform this task:
Check dates
For example: is it the right format, is it in range? You can use the following Anatella operators to perform this task:
Remove duplicates
Anatella contains a “box” to remove duplicates. You can use the following Anatella operator to perform this task:
Check consistency
Insure consistency between a set of keys between different datasources. You can use the following Anatella operators to perform this task:
Compare 2 datasets
Compare a selection of the character fields & numeric fields inside the 2 dataset using this operator:


Complex test
Design any complex test that you want using the powerful R, Python or Javascript engine included in Anatella.
Fix misspelled words
The Anatella spelling-correction operator will detect and correct misspelled words.
Fuzzy Join
Join tables based on a fuzzy match between “approximately” equal Keys using these operators:
- Key is Numeric:
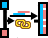 or
or 
- Key is a string:
 or
or  or
or 
If you have a composite key (i.e. a key composed of several columns) with complex matching rules, you can easily edit the JS code of the ![]() FuzzyJoin action to define you own complex rules.
FuzzyJoin action to define you own complex rules.
Perform Complex Text-Mining Tasks
Some examples:
- Automatic language detection (using the
 box ),
box ), - Phonetic Encoding using the Metaphone 3 algorithm (wit the box),
- translate text from any language (using the
 googleTanslate box),
googleTanslate box), - Validate postal addresses (using either the google geocoding API or the Geocode farm geocoding API, with the
 geocode and revergeocode box),
geocode and revergeocode box), - Use the rosette API (using the
 box)
box)
Create Text-Mining Predictive Models for Business-Defined Entity Extraction
Use a predictive model to pin-point the location of the entity that you want to extract. This is done is 4 steps:
- Identify a set of candidates for the entities that you want to extract. For example, if you want to extract a specific price in your document, design a box the identifies all the numbers in the document
- Extract the “context” around each candidate using the
 extractSurroundingLines box) and structure this context using the
extractSurroundingLines box) and structure this context using the  BagOfWord box) to obtain a learning&scoring dataset.
BagOfWord box) to obtain a learning&scoring dataset. - Create a predictive model (with “TIMi Modeler”) that detects the required entities
- Use your predictive model to detect the “right” entities.