Failure is one of my favorite topics, because not enough people talk about it, yet every data scientist had to deal with it. We try to hide that how we failed was really our coming of age, as if we were expected to have absorbed all past experiences by magic.
And this is what awaits aspiring data scientists. I have made so many mistakes in the last 20 years I can’t even count them.
Failure is the inability to see tangible results after considerable efforts, or even worse having a negative impact on a business. And if there is anything certain, with 53-90% of project failures, it’s that if you haven’t failed yet, you will. Failure can be bad, especially if you over-promise. Besides losing a client or even your job, you actually generate potential huge losses, or the belief that “it just doesn’t work” and set organization on delaying or even rejecting using ML/AI during years. Well managed, however, failures will fuel innovation, improve processes, and make teams much more reactive, because organizations will quickly learn how to avoid them.
When reading on the topic, it struck me that many of the posts show that failure is not our fault: bad management, bad data, bad integration, bad understanding, bad everything that does not depend on us. And I think all those are very well documented in many posts (just google “why predictive models fail” and you’ll find good reading material so I won’t repeat it here).
I haven’t found any quantitative data measuring failures, not since Rexer’s study in 2012, and I do realize this is really getting old. If you have better sources, please say so in the comments!

I put two items in red, because those are decreasing as data science gains in maturity, and today’s scientists are much better prepared than we were 10 years ago. We make “better” models, and we definitely explain better (although I still see way too many reporting unrealistic expectation with on ROC or – even worse – classification table. Read this post to understand why I don’t like either). We will explore how to avoid “bad models”, but let’s first explore some common ways to screw up even if the model could actually be perfect.
Scale your efforts:
The first item, too much effort, is still probably the most common. And this is almost unforgivable (yet, understandable).
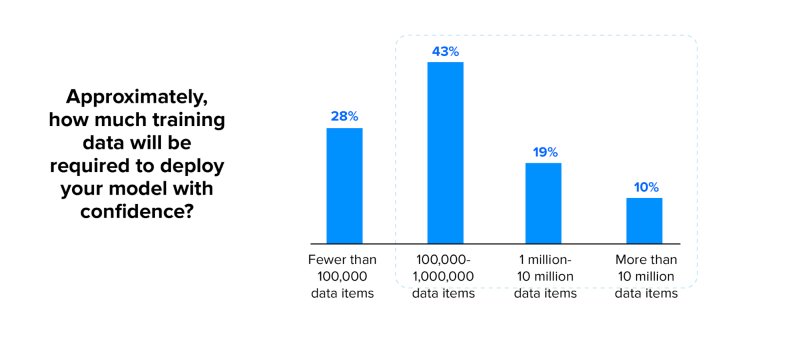
How does it happen? If we look at the report of KDNugget of 2021, 71% of projects require less than 1.000.000 rows, which is really not much. With such small amount of data, we are tempted to really overthink our features, and create some models that are just not realistic in production.
Production data, however, can be much larger and you need to make sure the data can be processed in a timely manner.
For example, you may want to create 15.000 features on your data, with a lot of ratios of weekly averages and trends of many additional product categories. And for 100.000 rows, the 2 hours of computation time were perfectly acceptable. But it’s unlikely that your systems in production will be able to handle it on 100.000.000 transactions (unless you use anatella, of course, then everything is possible 😆). Or they will pull the plug because they just received a bill of 30K form AWS because of your brilliant idea to use deeplearning for everything. Measuring effort and scaling to production properly is essential.
Ask the right question:
it’s easy to blame “the business” for not asking the right question, yet refining it by systematic validation of “what do you mean by this” is part of our job. A few examples:
- you need to build a response model to a campaign (seems straightforward enough). You line of questioning should go towards “how many people buy without the campaign? Is there a flag for the number of previous contacts? Were previous campaigns based on a “business” criteria? (see selection bias, below)
- You build a decision model that will affect how doctors proceed with diagnostic. You can’t just expect them to accept whatever came out of an algorithm without working hands in hands with field experts, and very carefully set the limitations of you model, and quality assessment of recommendations
- You build a model that will help set discount policy, do you expect salespeople to surrender their decision power and “gut feeling” when dealing with clients? How will you manage implementation?
Not all those questions have to do with how will will prepare the data, but they will let you know what variables should be in, and which ones should NOT be included. And they will certainly help you control adoption of your models.
Control basic Modeling errors:
Then, your model can be bad. And this will usually NOT be because of bad hyperparameters, or because the algorithm chosen inappropriate, like trying to sort out a multi-class problem on hundreds of categories, or using ElasticNet with Recoding to Targets on 300 observations, or a p-value based selection with millions of observations, or because we “overfit” due to bad parameters. But you already know all that, so I won’t waste time on the obvious.
There are others, more pernicious ways to have good looking models that do not deliver. Let’s focus on 2 methodological errors, and 4 hidden caveat behind appealing models.
1. obsession for a perfect model
This seems counter intuitive, but in many cases the perfect model is the enemy of a good model. There are of course situations in which months of refinements are worth it: cancer detection from images, and other situations in which the type of data and the target definition is unlikely to change. In other situations, it is usually not worth it.
Let’s have a look to some (old) data of predictive modeling competition: we see that the difference between the top 10 models is really marginal. The R2 variation on the AUSDM 2009 is pretty much flat, and the AUC of the PAKDD 2010 that varies between 0.63 and 0.645 has basically the significance of changing the random seed in many datasets.
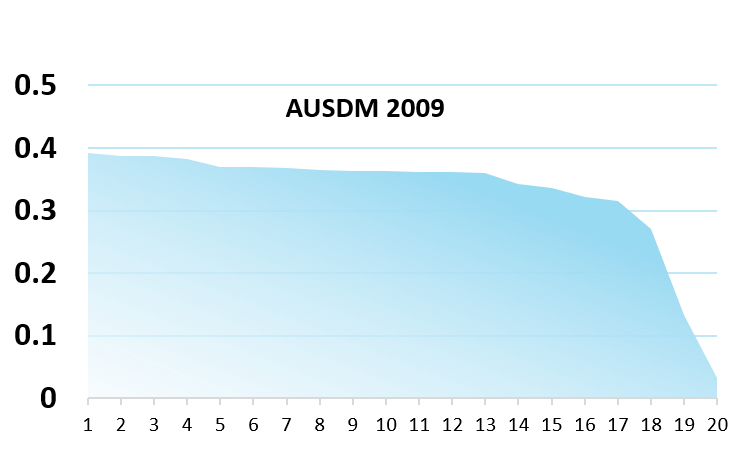
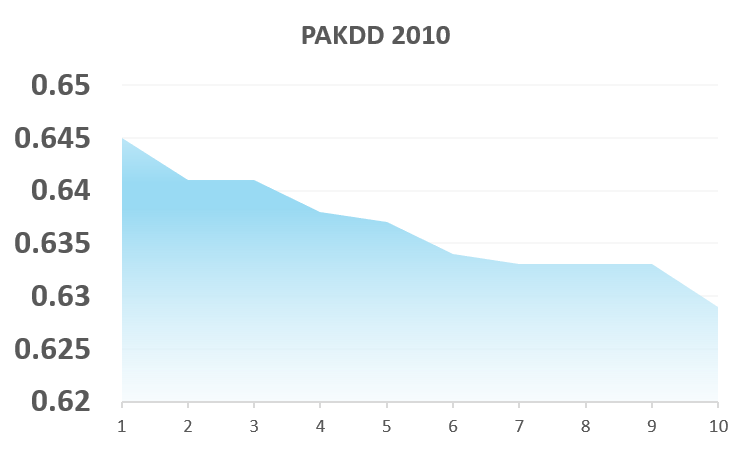
Knowing the difference may not be very large, you can read here to understand why a perfect model can actually be counter productive.
2. Models gone wild!
This is pretty much unforgivable, yet very common. We create a model without thinking of what could go wrong in the future. Either a deep learning model for ForEx that ends up fitting weird quadratic or exponential functions, or a pricing model that set the price of Steven’s good book from 4 USD to 809 USD. Definitely models that may not cost much (because nobody will believe them) but make you look, well … not smart.

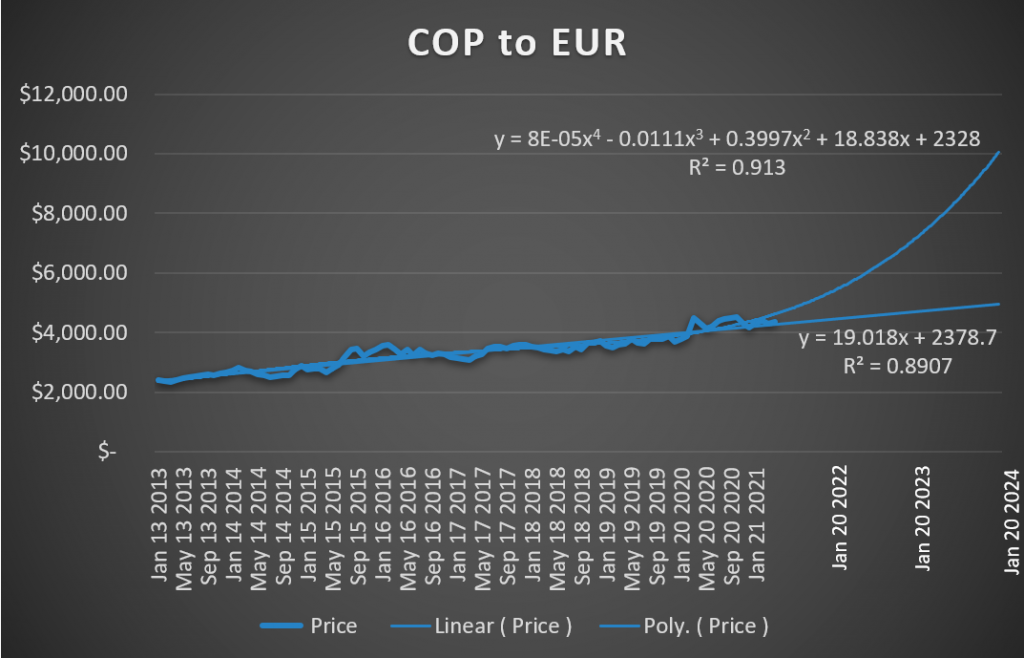
Attractive models that only teased us but never delivered!
Let’s now see how good looking models can hide an ugly truth. Those models will have an amazing ROC, and might even look very stable on test and back test, and yet yield zero return. How is it possible? Well, I can think of four ways (and there are probably much more)
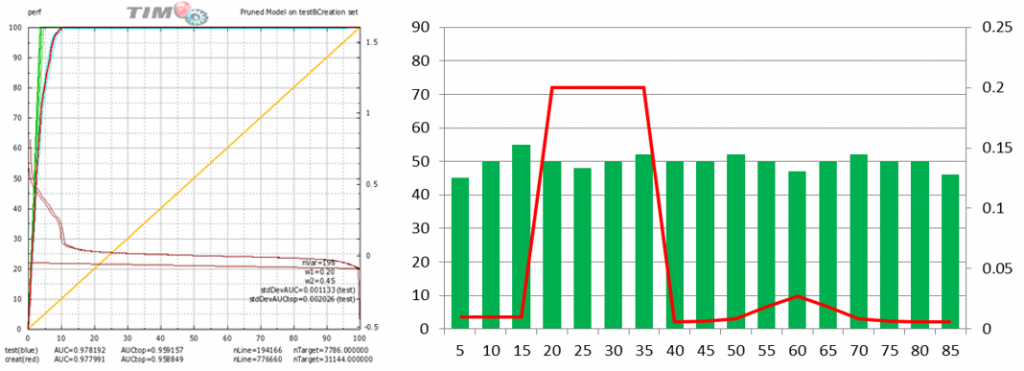
1. Selection Bias
This one is very common, and you should be extra careful. when one or two variables show a “box” pattern, and you have a very high AUC, it usually means something is very wrong. Basically, your model is reproducing a previous model, or a manual selection criteria. Your dataset is dirty and you need to either remove those variables, or change your learning sample selection, or change your target definition. This is an error that can cost you, because you may have campaigns with zero return, and not understand why a perfect model can fail!
2. Too Generic Models
This is a tricky one. In many situation, we are interested in building predictive models for a large number of targets, and we may see models that look very nice, but end up being all too similar. This is not obvious to detect, because they may look like they all have different features, but then our scores are “too” correlated.
This occurs because the pattern is not specific to the purchase of an actual item, but simply to the action of purchasing “something”. This usually occurs when the data is not formatted properly, and specific patterns are dominated by generic patterns. Try refining the question, or add a hierarchy, for example P(x=xi|purchase=1).
What is the cost of this error? irrelevant prediction, impossibility to optimize offers and very low yield of a campaign.
3. Leakage from the future
This is a very classic one: we included a variable that was a consequence of the event we try to predict. For example, paying an invoice is not a good predictor of purchase, although it will not be rejected as being “too good”:many pay the invoice late, or at least outside of the observation period, but the variable is ridiculous nonetheless (and I have observed errors like this on more than one occasion). Just make sure you double check the logic of every variable that looks good in your model. Yet another argument to avoid black boxes.
The risk here is high. You should get fired if this goes into production, because one meeting to review the variables with someone who half understands the business will make this go away.
4. A drink with Captain Obvious
Some variables are just plain silly. For example, you may be trying to predict that a customer is a “good customer” because he makes at least 36 transactions per year, and – oh surprise – the number of transaction might appear as a predictive variable, with the probability going up a LOT as the number of transaction yields to 35. Cheers, Captain Obvious! you’ve been of great help!
Hopefully, some of the information in this post will help you avoid some of the traps in predictive modeling. If you have questions, suggestions, reactions, don’t hesitate to comment.