TIMI IS FAST
Using code intensive tools means less time to focus on your data and ultimately,
less meaningful insights and value generated. Inside TIMi, everything is designed to make your more efficient: the interfaces are intuitive and the tools are powerfull. With TIMi, discovering the knowledge hidden in your data becomes fast and easy.
FAST & EASY
DATA TRANSFORMATION
Anatella’s high performances are reached thanks to continued efforts to get clean code in C and assembly. Anatella handles tables with dozens of billions of rows and thousands of columns on ordinary laptops.
Example 1 – Sorting a large table
Let’s sort a large CDR (Call Data Record) table from a Telecom with 6 million subscribers. The CDR table has 1 billion rows and 8 columns. When the CDR table is saved as a text-file, it weights 171 GB. See hereby an extract of the CDR table.
We’ll ask Anatella to sort the CDR table on the A (calling number) column. Before the sort, the CDR table is saved on the disk into 42 different (.gel_anatella) files (one file per day).
Anatella computes the complete sorted CDR table (1 billion rows) in 99 seconds using less than 300 MB of RAM. A similar sort runs for 5 hours when executed on a well-know, leader database.
Discover Anatella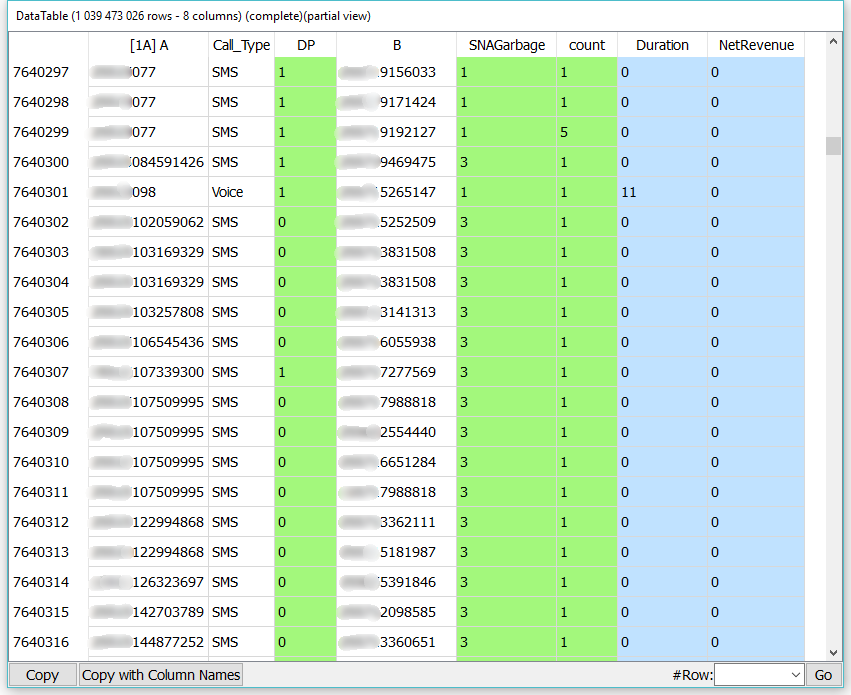
Example 2 – Aggregating large tables
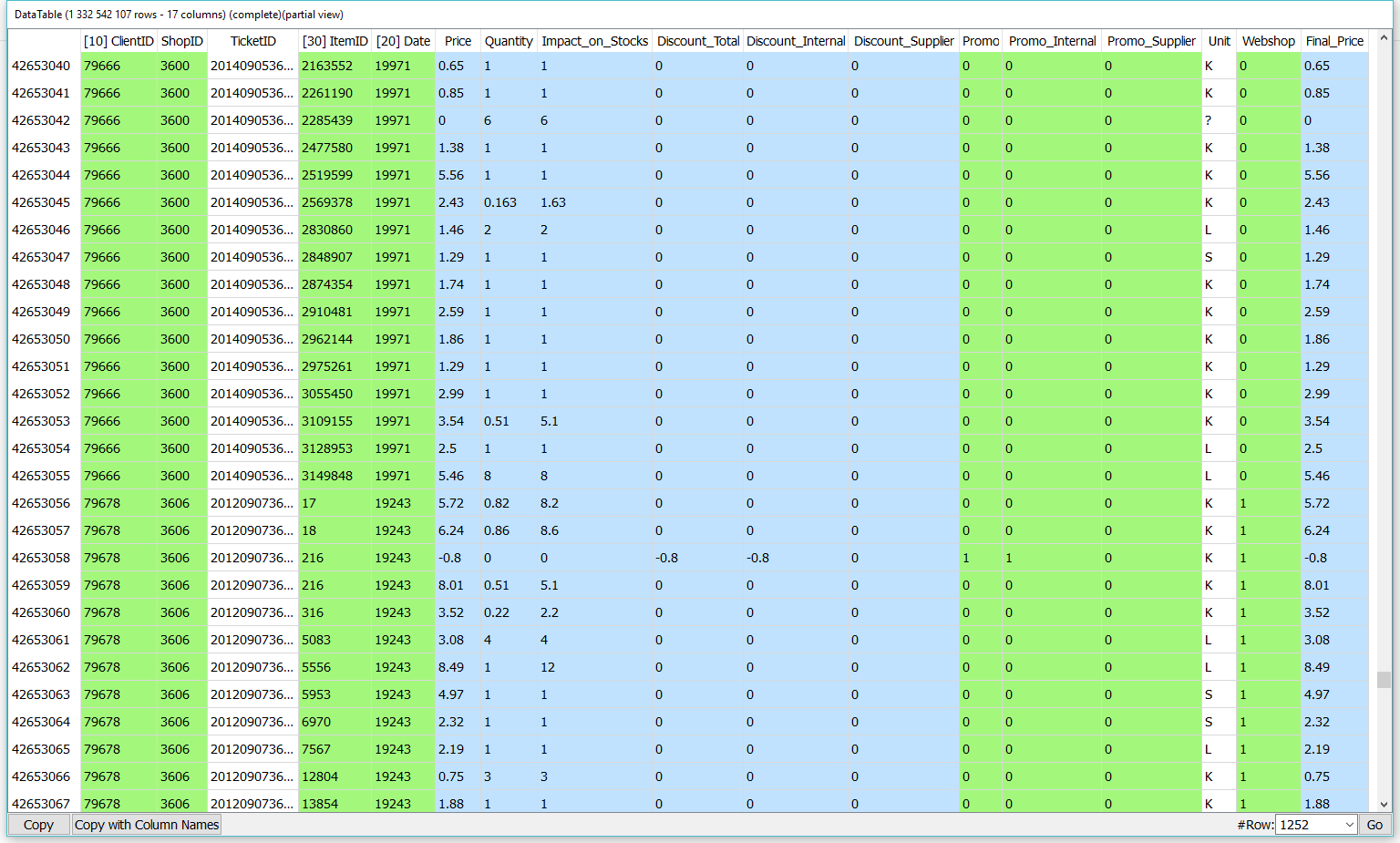
Let’s aggregate a large ticket table from a retailer with 1 million customers. The ticket table has 1.3 billion rows, 17 columns and represents all the sales from 2 years at the finest grain as possible. See hereby a small extract of the ticket table.
Using Anatella, we first transform the 450 GB SAS file .sas7bdat file in a more compact 23GB .cgel_anatella file. Then we ask Anatella to use this .cgel_anatella file to compute the total number of Web purchases. Anatella computes the requested aggregates on the (1 billion rows) ticket table in 70 seconds using less than 150 MB of RAM.

FAST & AUTOMATED
MACHINE LEARNING
Timi modeler is 100% multithreaded, vectorized and cache-optimized.
It produces predictive models significantly faster and with more accuracy than most off-the-shelves tools.
Example 1 – Speed
As the key ingredient of a good model is proper feature engineering, speed is a data scientist’s best friend: as you get results faster, you can test more ideas, and have more impacts in organizations.
Using a single PC with Timi modeler, a healthcare institution built a high-performance model on 6 million rows, 24.000 variables in only 4 hours (individual risk of heart attack within 6 months).
With Timi modeler, an energy company built a fraud prediction model in only 20 minutes with 18.000.000 rows and over 200 columns.
Discover Timi modeler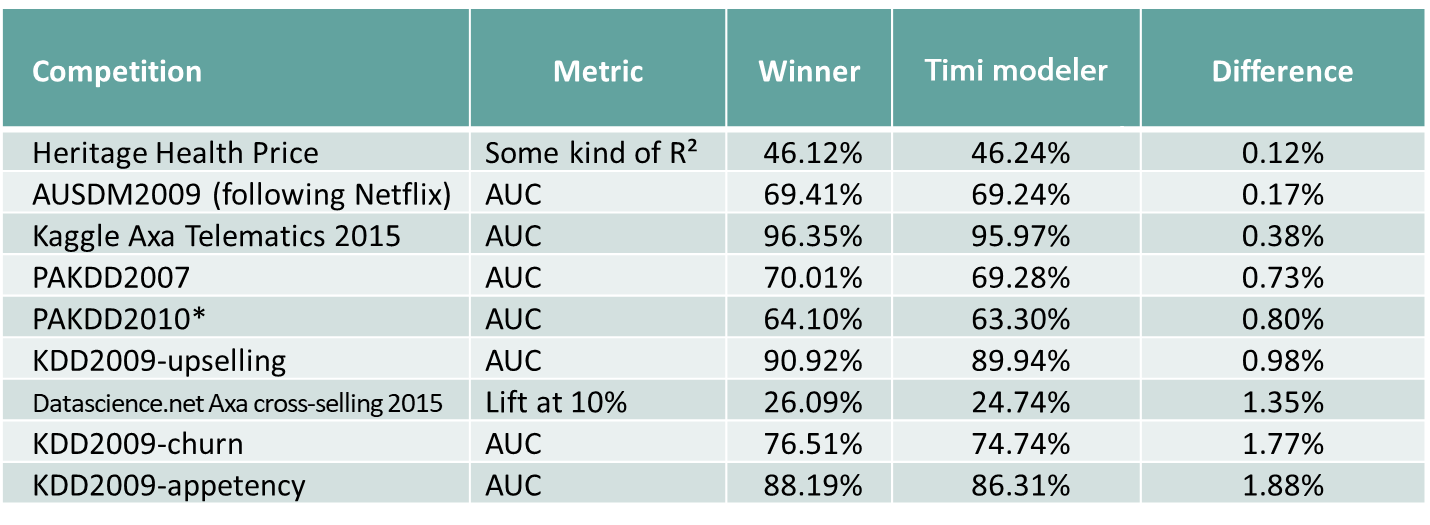
Example 2 – Accuracy
Speed alone is of course irrelevant without precision. Since 2007, Timi modeler’s automated machine learning engine produces predictive models that are significantly more accurate than other off-the-shelves tools. This fact is demonstrated by our outstanding results at various world-level data mining competitions (KDD Cups) and by real industrial benchmarks.
Read moreNotice
The examples mentionned on this page were running on this laptop:

Testimonials
“The optimal solution to extract advanced Social Network Algorithms metrics out of gigantic social data graphs.”
“We reduced by 10% the churn on the customer-segment with the highest churn rate.”
“TIMi framework includes a very flexible ETL tool that swiftly handles terabyte-size datasets on an ordinary desktop computer.”