Built for Machine Learning
Predictive Analytics projects are characterized by the large size of the manipulated tables. It’s very common to have an analytical datasets that contains several thousands of columns/variables. Anatella was built from scratch with this in mind.
A text mining project with Anatella
- High column count: Inside this text mining project, we created from scratch (from raw data) an analytical dataset with more than 33K columns/variables and more than 200K rows (0.95 GB .gel_anatella file or 12.6 GB as text file).
- Large Dataset: In this specific example, the initial text corpus is relatively small: 1.5 GB. This is why, in this video, everything is almost instantaneous. We used the TIMi Model Factory to automatically create our (text mining) predictive model (40 minutes to create a model on a learning dataset with 33K variables and 200K rows in Performance/Slow Mode).
- Access to open source eccosystems: We used the R engine to quickly plot a few charts to investigate the target.
- Meta-data-free: More details on this subject here. This is illustrated at:
- Time-tag 10:18: We added a new variable at the very beginning of the dataflow: This invalidates the meta-data of all the tables flowing through the graph. But this has no consequences what so ever and we could continue to work as if nothing important happened.
- Time-tag 18:31: We re-connected the data flow in a completely different way.
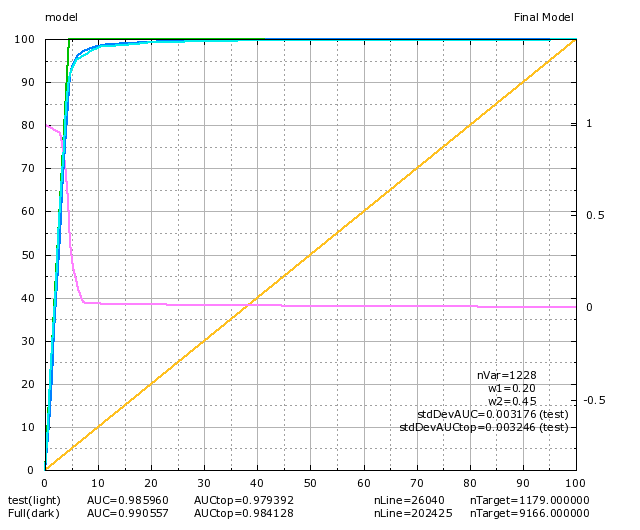
Final results
The final model was composed of more than 1200 variables.
It does not overfit and delivers extremely precise predictions: