R, Python & Hadoop Integration
In addition to its own unique features, Anatella integrates all open source eccosystems under one roof.
With Anatella, we created a “global framework” that is characterized by these keywords:
(1) 100% Open
(2) Mix & Combine everything seamlessly & transparently
(3) User-friendly visual representation
(4) Easily Extensible
(5) Reduced support and maintenance costs
(6) Unique code-revision system
(7) the R/Python/JS engine included into Anatella is the Fastest currently available: High-throughput data flows
(8) Abstraction layer
100% Open
In addition to its own unique features&algorithms, Anatella supports all the open source eccosystems. This means that you’ll have at your disposition all the features and all the algorithms from all the best eccosystems (R, Python, Hadoop), directly accessible.
Why settle for a specific language or library? Anatella can seamlessly integrate, inside the same data transformation graph, any piece of code programmed in either R, Python, Javascript or Hadoop.
Mix & Combine Everything
Inside the same Anatella-data-transformation-graph, you can:
- have “little boxes” that use “behind the scene” code in R, Python, Javascript and C.
- access transparently your Hadoop HDFS drive “as-if” it were a local disk
Even better: Maybe you need a specific library only available inside a specific version of R/Python that is different from the common version installed on your server? No worries neither! With Anatella, you can assemble easily and visually together any language, library and version. It’s the ultimate flexibility
User-friendly
Thanks to the user-friendly visual representation of the data transformation, you can quickly understand “what’s going on” inside your Anatella-data-transformation-graph without reading thousands of line of R/Python/JavaScript code.
This has direct & positive consequences on the support & maintenance costs of an analytical solution created with TIMi: i.e. see the “support & maintenance” cost paragraph here below for more information about this subject.
Easily Extensible
If you ever need to create a new “little box”, you can do so in 2 mouse-clicks.
But, the ability to create a new “box” is only a small part of the solution. As you already know, when handling code, only 10% of the time is devoted to the actual creation of the code and 90% of the time is devoted on fixing and supporting the new code. This is why Anatella offers 3 unique functionalities that allows you to easily support and maintain you code: see next paragraph.
Reduced support and maintenance costs
The cost to support and maintain an analytical solution created with TIMi is lower than with any other analytical solution.
This is possible thanks to:
- The user-friendly visual representation of your data-transformations. I don’t count anymore the companies that lost their whole analytical system because:
- The only expert coder that understood the dozens of thousands of lines of R/python code included inside their analytical system decided to leave them.
- their analytical system was developed by a third-party consultancy company that “obfuscated” the code to be sure to push them in a “lock-in” situation where they can send arbitrarily large invoices, just to keep the analytical system up&running.
When using Anatella, such situation are unlikely to occur because, within Anatella, all data-transformations are easy to understand, even by a non-expert, thanks to the user-friendly visual representation.
- The unique debugging capabilities from Anatella: Click anywhere in an Anatella graph and you instantaneously see the data “flowing through” this point. No other solution offers that. This instantaneous data preview is made possible through the unique “cache system” from Anatella.
- To “debug” the scripts written in JavaScript: Anatella is the only ETL tool available on the market to offer you a direct access to a complete & powerful “debugger” with an interface similar to the famous MS Visual Studio debugger: You can add “break points” to your code, add some “watch” on variables, see the “stack”,… It’s great!
- A unique “Revision control utility” that manages the different versions of your scripts&code: see next paragraph for more information about this subject.
Unique code-revision system
Anatella integrates a unique code-revision control system that allows to evolve easily your analytical system.
Let’s assume that a business-user, named Mr.X, asked you (as an expert coder) to create a new “little box” to use inside Anatella. Mr.X is very happy with the new “little box” that your created for him and he uses it extensively everywhere. One day, Mr.X finds an error inside your “little box” and you quickly produce a “fix” that removes the bug. What happens to the hundreds of Anatella-graphs that are already using your “little box”? Will they get also “fixed”? Thanks to the advanced code-revision system included in Anatella, we can safely answer: Yes! This is a unique functionality. Without this functionality, tracking all the places where somebody used the erroneous old code would be a nightmare.
Thanks to the same code-revision system, you can also produce “upgraded” versions of all your “little boxes”. Each time you improve a “box”, your improvements are automatically propagated to all the places where your “box” is used. This means that Anatella is a framework that allows you to iteratively & progressively improve your analytic system. Maybe, your first few boxes will lack sophistication but this doesn’t matter: With Anatella, you can constantly & easily “evolve” your analytic system “to boldly go where not dataminer has gone before”.
High-throughput data flows
Anatella provides a high-throughput data flow, even inside a multi-language graph (i.e. a graph that mixes R, Python and Hadoop).
With Anatella, you can assemble easily and visually together any language, library and version. It’s the ultimate flexibility and it doesn’t even arrive at a cost: Anatella has one of the fastest (maybe the fastest) R/Python engine.
Furthermore, in some common occasions (e.g. when scoring a database) Anatella is even able to automagically parallelize you R/Python code to use all your CPU’s in parallel, to reach very high throughput.
During the opening session of the “Microsoft Machine Learning & Data Science Summit” on Sept 26, 2016 in Atlanta, Microsoft show-cased their latest technical prowess: They managed to score a database at a speed of one-million row per second, using a R-evolution cluster composed of an undisclosed number of PC’s on Azure (the global theme of the Summit was about “machine learning and cloud computation in Azure”). The predictive model used for scoring in the demonstration is a typical “fraud detection model” in R. This is a screenshot extracted of the presentation that shows the scoring speed (of one-million row per second) achieved by the Microsoft Azure Cluster composed of machines using R-evolution:
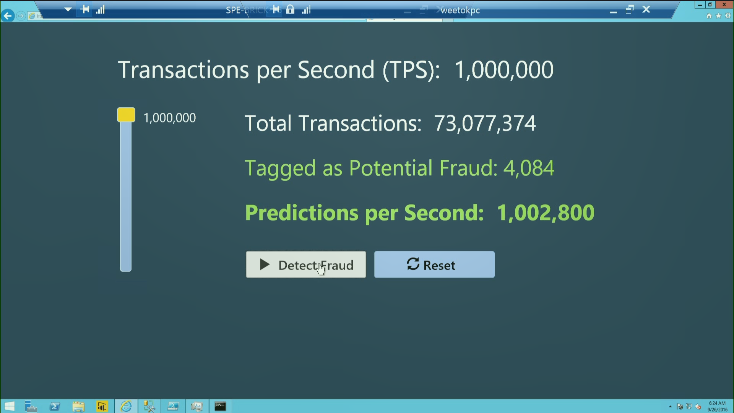
What happens if we use Anatella to score (also using the R engine), a 10 million-row database on one standard 2K€ laptop from 2015? Do we manage to “match” the Azure cluster and perform the scoring in 10 seconds? No, we beat the cluster and we score the 10-millions-rows in 8.7 seconds (in other words, this is scoring at a rate of 1.15 million rows per second). If we use a TIMi model (rather than a R model), it’s even faster (7 seconds).
How can the R engine included in Anatella be faster than a large Azure cluster? This is because of the unique way Anatella interacts with the R engine: Anatella directly writes inside the R memory space the data that it manipulates. Anatella executes thus a 100% in-RAM “memory copy” to pass the data to the R engine (at a speed of, typically, more than 10 GByte/sec). This ensures a very high data throughput. The same mechanism is also used to interact with the Python engine, ensuring a very high data throughput when using Python.
Abstraction Layer
In addition to all the above functionalities, Anatella also offers a unique Abstraction Layer around your code that has several advantages.
More about the ''Abstraction Layer''