NEVER WAIT ANYMORE
FOR A DATA TRANSFORMATION
Anatella’s high performances are reached thanks to continued efforts to get clean code in C and assembly. Anatella handles tables with dozens of billions of rows and thousands of columns on ordinary laptops.
Example 1 – Sorting a large table
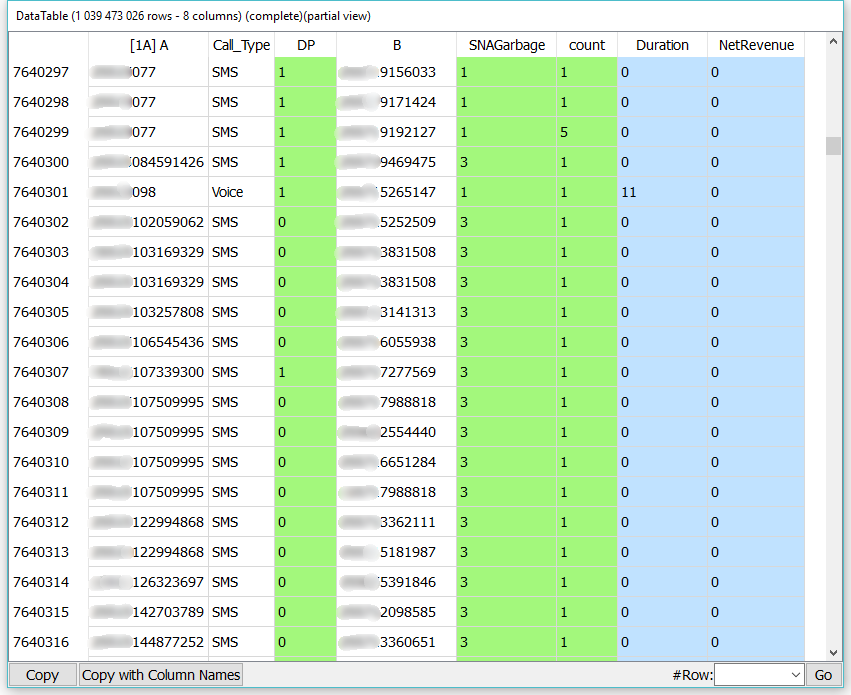
Let’s sort a large CDR (Call Data Record) table from a Telecom with 6 million subscribers. The CDR table has 1 billion rows and 8 columns. When the CDR table is saved as a text-file, it weights 171 GB. See hereby an extract of the CDR table.
We’ll ask Anatella to sort the CDR table on the A (calling number) column. Before the sort, the CDR table is saved on the disk into 42 different (.gel_anatella) files (one file per day). To do the sort, we’ll use this Anatella-data-transformation graph on a laptop:

Anatella computes the complete sorted CDR table (1 billion rows) in 99 seconds using less than 300 MB of RAM. A similar sort runs for 5 hours when executed on a well-know, leader database.
Example 2 – Aggregating large tables
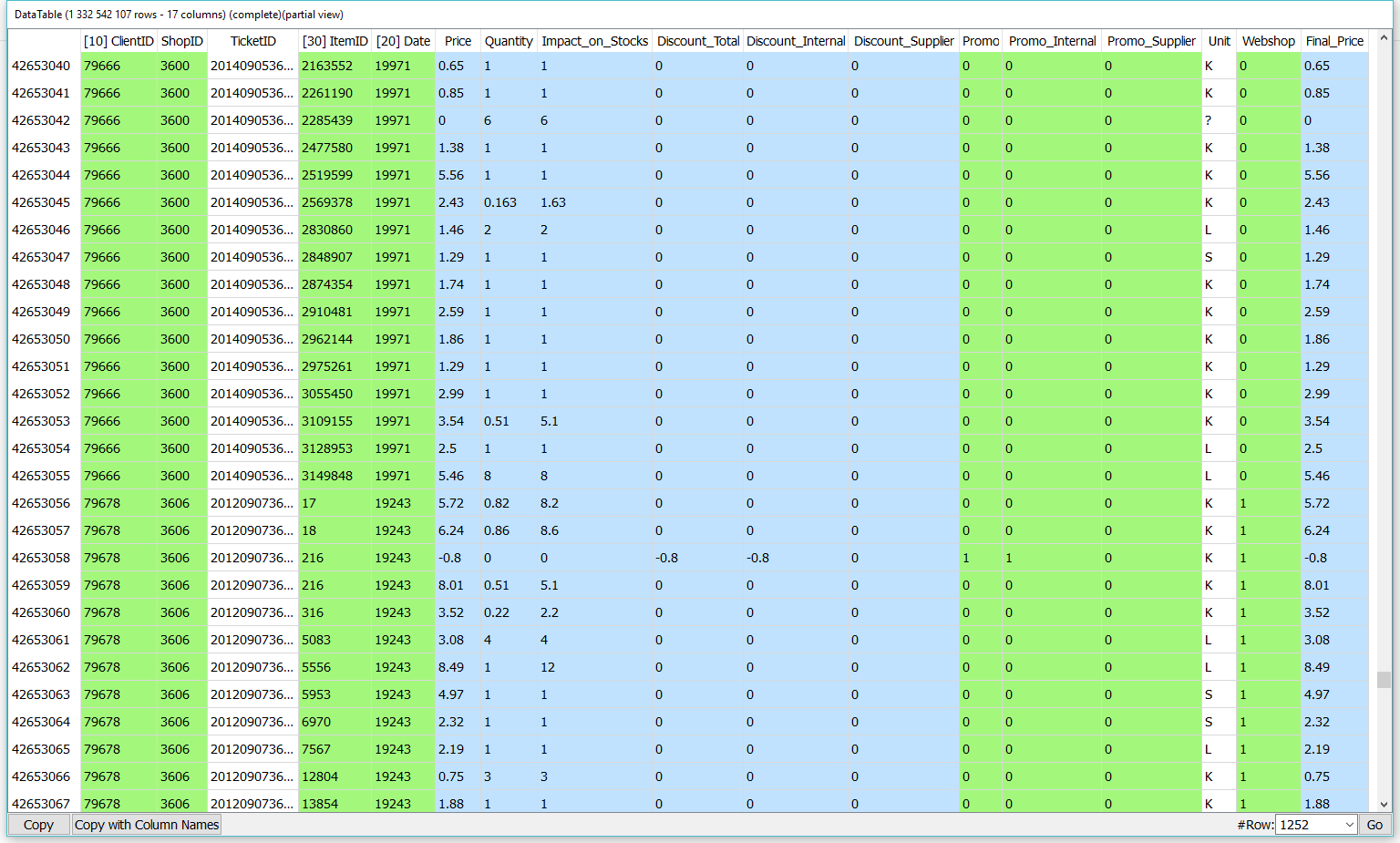
Let’s aggregate a large ticket table from a retailer with 1 million customers. The ticket table has 1.3 billion rows, 17 columns and represents all the sales from 2 years at the finest grain as possible. See hereby a small extract of the ticket table.
Using Anatella, we first transform the 450 GB SAS file .sas7bdat file in a more compact 23GB .cgel_anatella file. Then we ask Anatella to use this .cgel_anatella file to compute the total number of Web purchases. To compute the aggregate, we use this Anatella-data-transformation graph:

Anatella computes the requested aggregates on the (1 billion rows) ticket table in 70 seconds using less than 150 MB of RAM.
Notice
All examples mentionned on this page were running on this laptop:
