Data Quality tools for text mining
With these tools you can detect & correct errors in textual information.
A typical example is the “Address Fields” inside your customer database. These addresses are manually encoded and contains a large number of errors (miss-spelling) that can potentially:
- Degrades the quality of your predictive models (For example, This was a major concern at the PAKDD2010). Most of the time, TIMi is able to automatically devliver high quality models even in the presence of errors inside the data but, in this case (i.e. wrong addresses), a bad data quality means, at the end of the day,less efficient marketing campaigns (and thus less ROI!).
- Hinder the quality of your reports (Dashboards, OLAP reporting, etc.).
Amongst the available tools available inside TIMi to improve text quality, you’ll find:
- Automated spelling mistakes correction.
- A state-of-the-art phonetic encoder: The Metaphone 3 encoder.
This encoder is not used to “clean” the data (in opposition to the previous one) but it rather allows you to “bypass” data quality issues when performing (for example) table-joins. This encoder is used, for example, inside Google Refine (The data quality tool from Google).
The typical usage of a phonetic encoder is the following: you have 2 tables that contains different piece of information about the same individuals. You want to create one unified view of these 2 tables (i.e. you want to join the 2 table into one). You must use the individual’s names to join 2 rows (from the 2 tables) together but these names contains Miss Spellings (i.e. the primary keys are individual’s names). To bypass these spelling errors, you can join the 2 tables using the phonetic encoding of the names (rather than simply using the plain names). You thus need an phonetic encoder that is able to understand how names written in English, Dutch, French, German, Spanish are pronounced. The Metaphone 3 encoder is one of the very few phonetic encoder that is able to “understand” a very wide variety of languages automatically (other encoders are limited to one language only). It’s thus the perfect encoder for such a task.
Restructuring text for modeling tasks
The objective here is to create predictive models based on unstructured data (i.e. based on text).
Typical usage scenariis include building models for:
- Churn/Cross-Selling/Up-Selling modeling: We’ll complement the customer profiles by adding some fields (usually around 10.000 new fields) coming from text analytics. The main objective here is to increase the quality of the predictive models (to get more ROI out of it). For example, we can easily build high-accuracy Predictive Models that looks at a text database containing the calls made to your “hot line”. If these texts contain words like “disconnections”, “noisy”, “unreachable”, etc. it can be a good indicator of churn (for a telecom operator).
- Document classification: We’ll automatically assign tags to documents to say, for example: This document is talking about Nuclear Fusion (i.e. This document receives the tag “Nuclear Fusion”) or this one is talking about Nuclear Fission (i.e. This document receives the tag “Nuclear Fission”). Based on these tags, you can implement (typically with Anatella) a business-logic that re-route documents to specific destinations. A good business-example would be: Automatic rerouting of “Patent Application Documents related to Nuclear Fussion” to the department handling all patents related to “Nuclear Fussion” (for the patent office in EU or US). This precise example is interesting because it’s very difficult to find a human that is able to correctly re-route the documents because this person should be, at the same time, a specialist in many different fields (fields such as Nuclear Science, Agriculture, Retail, Telecom, Banks, etc.)
To be able to create predictive models based on text, classical analytical tools are forcing you to define “Dictionnaries”. These “Dictionnaries” contain a limited list of words pertaining to the field of interest. Each of these word/concept directly translates to a new variable added to the analytical dataset used for modeling (i.e. to the dataset injected into TIMi). Typically, you can’t have more than a few hundreds different words or concept because classical modeling tools are limited in the number of variables that they can handle.
In opposition, TIMi supports a practically unlimited number of variables. This allows us to use a radically different approach in text mining. Instead of limiting the construction of the analytical dataset to a few hundred words/concepts, we’ll create an analytical dataset that contains ALL the words/concepts visible inside the text corpus to analyze (and even more, if desired)(To be more precise, we are using the Bag-of-Word principle on the set of all stemmed words of the text corpus. Our stemmer supports a wide variety of languages). This approach has several advantages over the classical approach (used in classical tools):
- We don’t need to create “Dictionnaries” because TIMi will automatically select for us the optimal set of words and concepts that are the best to predict the given target. Since we are using an optimal selection, rather than a hand-made approximative selection, the preditive models delivered by TIMi are more accurate (and thus generates more ROI).
- We gain a large amount of man-hours because it’s not required anymore to create “Dictionnaries”. “Dictionnaries” are context-sensitive: For each different tasks/predictive target, you need to re-create a new dictionnary (i.e. you need to select manually the columns included inside the analytical dataset rather than let TIMi automatically select them for you). Creating new Dictionnaries is a lengthy boring task, easily prone to errors.
Example
Here is an example where we built a set of predictive models to automatically assign the flags “SPORT NEWS”, “CULTURAL NEWS”, “FINANCIAL NEWS”, “NATIONAL NEWS”, “FOREIGN NEWS” to unknown news messages arriving at at newspaper. We have one predictive model per flag. Here is an extract of the MSWord auto-generated report obtained when creating the predictive model used to assign the flag “FOREIGN_NEWS”:
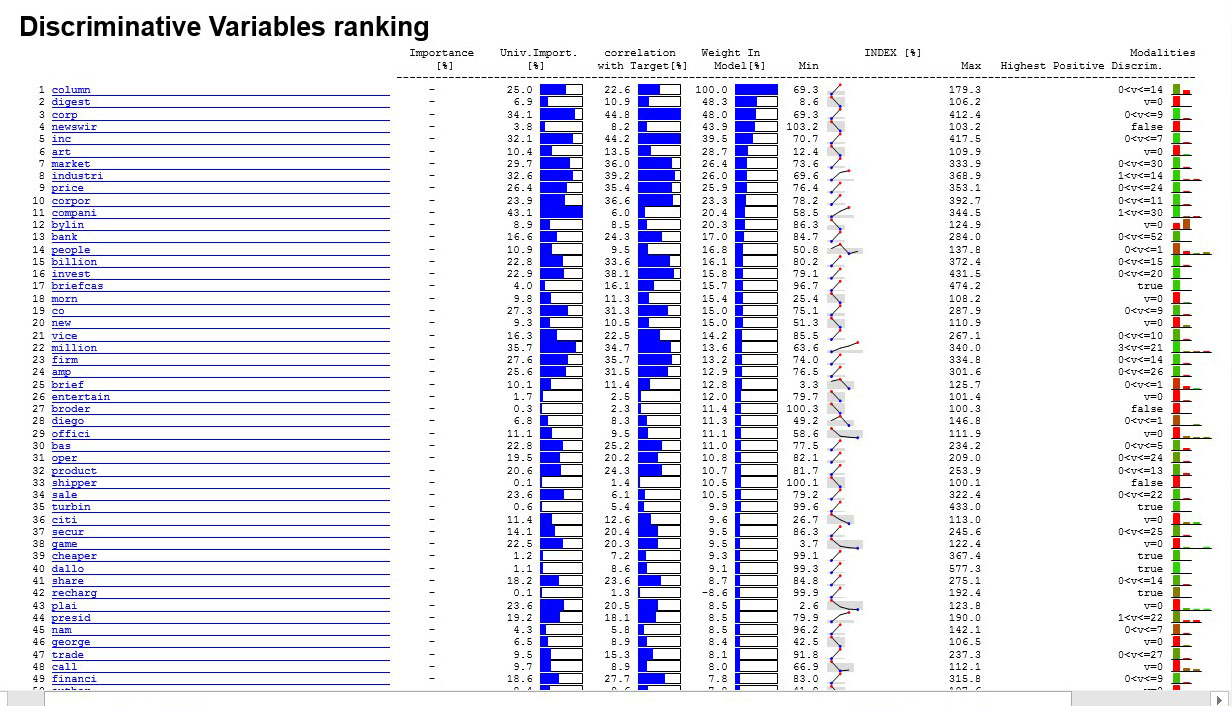


About this model:
- This model was built on an analytical dataset containing 13199 different words/concepts (i.e. We are not using a “limited Dictionnary”).
- This model actually uses 356 (out of the 13199) words/concepts to make its prediction/tagging.
- The accuracy of this model is extremely high (AUC>97%).
- The running-time to build this model was less than a minute.
- The above report shows us that some of the important words/concepts used to make a prediction about the “FOREIGN_NEWS” tag are: market, industri, compani, corpor. This illustrates how the Stemmer included into TIMi works: These words/concepts used inside the predictive model are the roots of the words: marketing, markets, industrial, indusialisation, companies, coporate. The TIMi stemmer supports the danish, dutch, english, finish, french, german, hungarian, italian, norwegian, portugeuse, romanian, russian, spanish, swedish, turkish languages.