Of the utility of the test dataset
Let’s assume that we want to create a ranking (or a “list of candidates”) for a marketing campaign using predictive technique.
Let’s give a practical and real example. Let’s assume that we are end of 2009 and you are selling a “GPS device” (like Garmin or TomTom). You have a copy of your customer database from 2008 (this is your “learning dataset”).
To create your predictive model, you “flagged” inside your 2008-dataset all the customers that bought a GPS device in 2009 and simply run TIMi to obtain your predictive model.
The generated predictive model will detects all the “flagged” people (i.e. the “future buyers”)(In technical terms, the “flagged” people are named the “targets to predict” or, in short, the “targets”).
If you are using another Analytical tool to create your predictive model, it can be a lot more complex, but with TIMi , it’s done with 1-mouse-click. Here is an illustration:
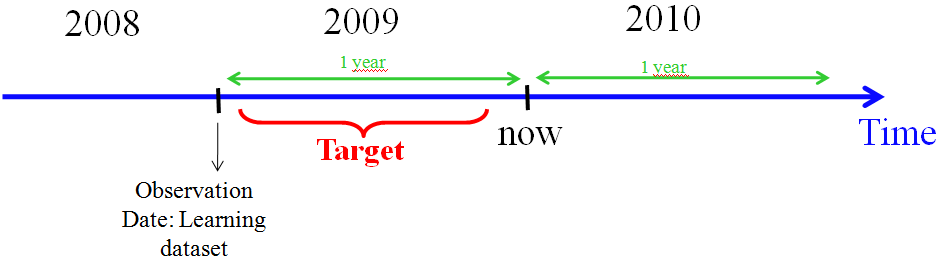
TIMi will analyze the database containing the customers of 2008 and it will find all the common features that are shared by all the customers that “are inside the target” (i.e. that will buy your product soon) (i.e. that bought your product in 2009). These “common features” are defining your predictive model. In essence, the predictive model searches for the exact “profile” of your buyers.
We will obtain a predictive model that can be summarized as: “If you have a company car and you recently bought some home cinema equipment, then you have a great chance to buy a GPS device next year”. For this example, we assumed that your “learning dataset” is a dataset that contains the following columns:
- Do you have a company car?
- Did you recently bought some home cinema equipment?
- Etc.
To see if our predictive model is able to correctly detect the buyers of 2009, we can apply our predictive model on our learning dataset (our database of 2008) and look at the lift-curve: a high lift curve means that our predictive model is able to pin-point correctly the buyers of 2009. The name of this particular lift curve is “lift curve on the learning dataset”.
The objective of our predictive model is to predict who will buy your product in 2010 (I remember you that we are end of 2009). To create our ranking, we can simply apply our predictive model onto the most recent snapshot of your customer-database (from 2009)(this snapshot is commonly named the “Apply” or “Scoring” Dataset): our predictive model will detect who are the individuals that will buy your product in 2010.
Here is an illustration:
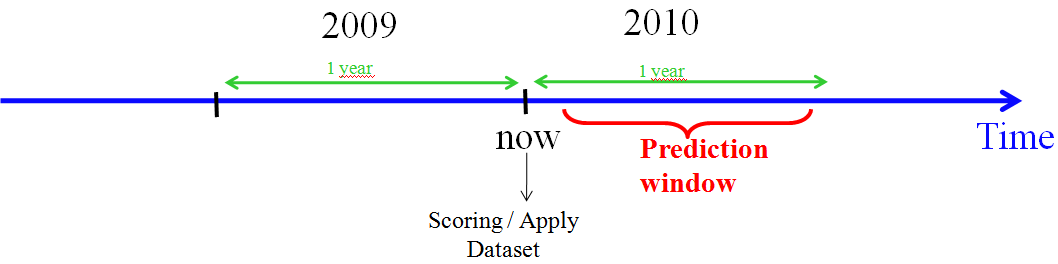
There is a big danger with this approach: our predictive model is most certainly able to pin-point the future buyers inside our learning dataset (inside your customer-database from 2008). However, there is no guarantee that our predictive model will correctly detect the future buyers inside the Apply dataset (inside your most recent snapshot of your customer-database from 2009) because these are 2 different databases, containing different persons (the “learning dataset” and the “apply dataset” are not the same!).
How can we know if our predictive model will correctly work on our “Apply dataset” that contains unknown and completely new individuals? The solution is simple: use a TEST dataset.
How to create a TEST dataset? You simply remove out of your “Learning dataset” 30% of the total number of individuals. We keep these 30% “on the side” (this is actually our TEST dataset) and we don’t use them to create our predictive model.
Thereafter, to estimate the accuracy of our predictive model on unknown and completely new individuals, we simply use our predictive model on our TEST dataset: if our predictive model is able to correctly “find” your buyers inside the TEST dataset, it means that our predictive model is really good and also works on previously unknown and unseen individuals!
The accuracy of our predictive model is represented by the lift curve of our predictive model when we apply our predictive model on our TEST dataset. The name of this lift curve is “lift curve on the TEST dataset”.
One very important rule
When comparing the accuracy of 2 different predictive models to know which predictive model is the best one (the one with the highest accuracy & the highest ROI), you must compare ONLY the “lift curves computed on the TEST dataset (and if possible, use always the same TEST dataset).
Another important rule
To compare the accuracy of 2 different predictive models, the lift curves on the learning dataset are meaningless. It’s very easy to obtain very good lift curves on the learning dataset. Any Analytical CRM tool can have 100% accuracy on the learning dataset. In opposition, it’s very difficult to obtain good accuracy on the TEST dataset. This is why most Analytical CRM tool are purely and simply hiding in sub-sub-menus their lift curves on the TEST dataset… The ROI of your marketing campaigns only depends on the accuracy (and thus on the lift curve) of your predictive models on the test dataset.
You must be very careful when you compare different predictive models created with different Analytical CRM tools: only look at the lift curves computed on the test dataset because the lift curves on any other datasets than the test dataset are meaningless.
The lifts obtained with TIMi (on the test dataset) are systematically better (they are higher) than the lifts obtained with any other commercially available analytical CRM software (it’s very common to have an improvement from 10% to 20% at X=10%). This is demonstrated by our outstanding results at various datamining competitions.
This means that, when you are using TIMi, all your marketing campaigns will have substantially higher ROI (from 10% to 20% added ROI compared to another Predictive-Analytical-CRM-Tool (and from 300% to 500% more ROI compared to a segmentation-based-Analytical-CRM-tool).