TIMi Top winner at the KDD2009 cup
We took part to the world-famous datamining competition: the “KDD2009 cup”.
The rules of such competitions are always more or less the same and are very simple: for example: you receive some data collected in 2006 and 2007 and you must predict what will happen in 2008. The organizers of the competition are comparing your predictions with the real events of 2008 (they are the only one to know what happened in 2008). The team with the less prediction errors gets the first place.
This year, there were 2 different challenges for the KDD cup, each using a different datasets. The first dataset/challenge had no or very little interest outside the academic and university world because this dataset contains 15000 columns (do you know many companies that possess such a large dataset? I know none).
The second dataset was a “standard dataset” usually found in enterprise (with around 300 columns). This second dataset was only used inside the KDD competition for the “small challenge” (which is named this way because this last dataset is smaller than the first one) also called the “second challenge”. The second dataset was used to create predictions for the Orange Telecom operator (“Orange” is the number 1 of the French Telecom). The final ranking is based on the average quality (AUC) of 3 predictive models. The 3 predictive models to built are one Churn model, one Upselling Model and one “Propensity-to-buy” (appetency) model.
The KDD cup has draw a lot of attention this year because the task to fulfill (for the second challenge) is a very common task inside the telecom industry and represents accurately the kind of tasks that are encountered in “real life” (in opposition to the purely “abstracts” tasks that are commonly proposed in the university world). The competition was a real struggle because everybody wanted to demonstrate his superiority on “real world tasks”.
Final results
The final results of the competition are here: http://www.kddcup-orange.com/winners.php?page=slow. You will notice that, on this page, the results obtained with the “small dataset” are mixed with the results of the “large dataset”. I extracted the result obtained on the “small dataset” only and put them inside an excel file “KDD_results_small.xls” in attachement. Here is an graphical illustration of the scores for the best performers on the “small dataset” only:
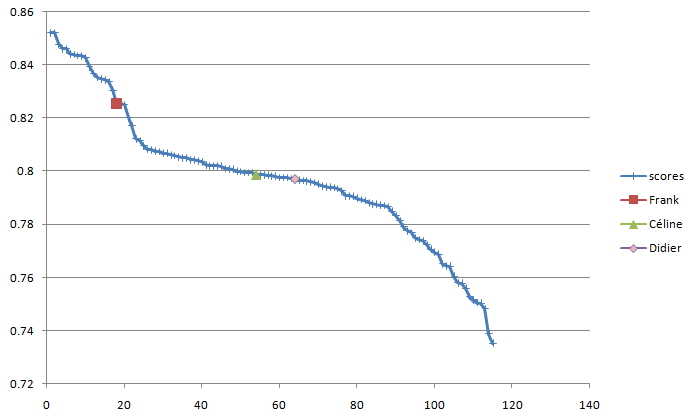
Using Modeler, We obtained the 18th rank (on a total of over 1200 companies that took part in the competition) with a best score of 0.825 (see the chart above). Two other teams (Céline&Didier) participated to the competition using a very old beta-version of TIM and obtained the rank 54 and 64.
To summarize: for the “small dataset” challenge (higher means better):

Datamining softwares are all about speed: if your software is faster, you can make more computations, use better parameter settings and, at the end, obtain better predictions. This is why the winner of the KDD this year is IBM (they were not using SPSS!): they don’t have a good datamining software but they were using a large number of PC’s and a very large crew: more than 15 people working full-time during 1 month, exclusively on this.
The companies that are inside the TOP20 of the KDD2009 ranking are all using (except us) techniques that are extremely costly in terms of computing time and in terms of “man power”. This is unrealistic. In real situations, in banks, in Telco, in insurance, you don’t have such computing power or so much “man power”. In opposition, we only used our own personal laptop to obtain all the results (…and I only worked on the competition with TIMi
during the evenings). At the end, the results obtained are quite spectacular, especially when you take into account the very small computing power that was used.
This rank places the TIMi company as the best datamining company in Europe.
Additionnal notes
- The small dataset is the most interesting dataset for this challenge because it allows to get a score of 85.21 while the large dataset only gives you a score of 84.93. …and, of course, this is on the small dataset that the we obtained the best results! The small dataset is also the dataset that resemble the most to “real-life” dataset usually available in enterprises.
- The results obtained on the large dataset were all obtained in 5 days. Given more time (and more CPU power!), we could have obtained higher scores.
- You can notice that there is a strong difference of performance between the TOP20 and the rest of the competitors: you can easily see that in the excel file in attachment.