TIMi Top winner at the AUSDM 2009 cup
The goal of the AusDM 2009 Analytic Challenge was to encourage the discovery of new algorithms for ensembling or ‘blending’ sets of expert predictions. Ensembling is the process of combining multiple sets of expert predictions so as to result in a single prediction of higher accuracy than those of any of the individual experts.
From previous data mining competitions such as the Netflix Prize, it has become apparent that for many predictive analytics problems, the best approach for maximizing prediction accuracy is to generate a large number of individual predictions using different algorithms and/or data, and ensembling these sub-results for a final prediction.
The AusDM 2009 challenge organizers provided sets of predictions obtained from the two leading teams in the Netflix Prize competition; Belkor’s Pragmatic Chaos, and The Ensemble. The objective of the Netflix competition is to guess which rating a user will give to a specific movie. The ratings are in a “star” scale: from “1 star” to “5 stars”. The final objective for the Netflix company is to use these “guesses” (or predictions) inside a recommander system to “suggest” movies to potential netflix customers.
There were three datasets provided:
- a small dataset with 30,000 sets of predictions from 200 experts (different algorithms or variations)
- a medium dataset with 40,000 sets of predictions from 250 experts
- a large dataset with 100,000 sets predictions from 1151 experts
Only the medium and large datasets were used inside the competition. Each of the three datasets were evenly divided into a “Test” subset
containing only the individual expert predictions and a “training” subset containing both the expert predictions and the actual values for training. The training values were obtained from the Netflix Prize dataset by the organizers of the AusDM Challenge.
There were 4 different tasks in the AUSDM 2009 competition:
- RMSE Large (training dataset of 1,151 vars and 50000 rows) and RMSE medium (training dataset of 250 vars and 50000 rows): These are two continuous prediction problems: The objective is to predict exactly the rating (the number of “star” given to a movie multiplied by 1000: this gives 1000,2000,3000,4000 or 5000) of the movie.
- AUC Large and AUC Medium: These are two binary prediction problems: The objective is to predict exactly if the rating is “5 stars” or “1 star”.
We used TIM without any special treatments on the dataset obtained from the AusDM 2009 website.
Final standings
Our final rank is shown here (see “Kranf” entry) (Inside the different tables, the organization committee is using the terms “Gini” and “AUC” indifferently):
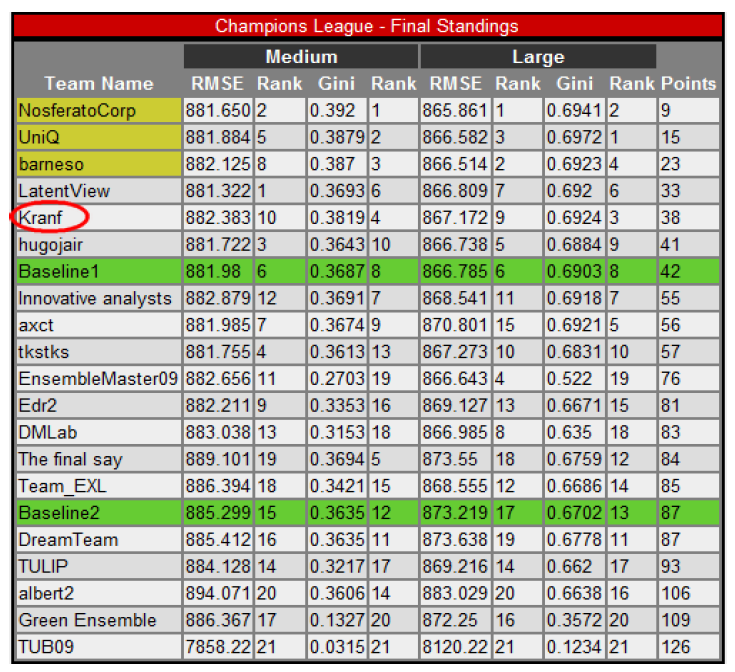
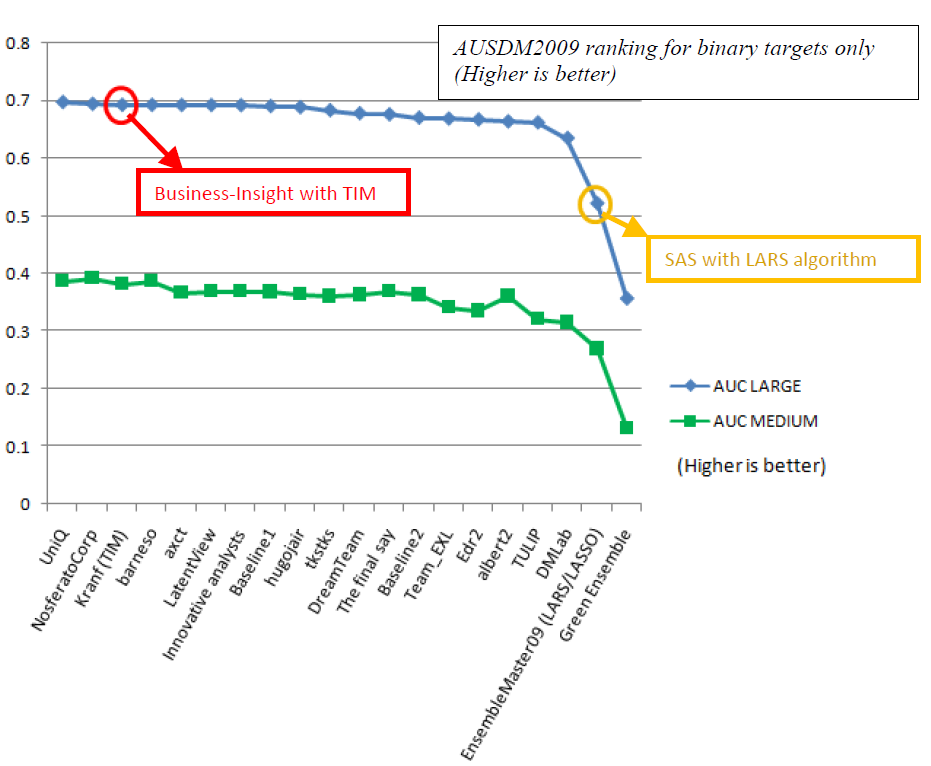
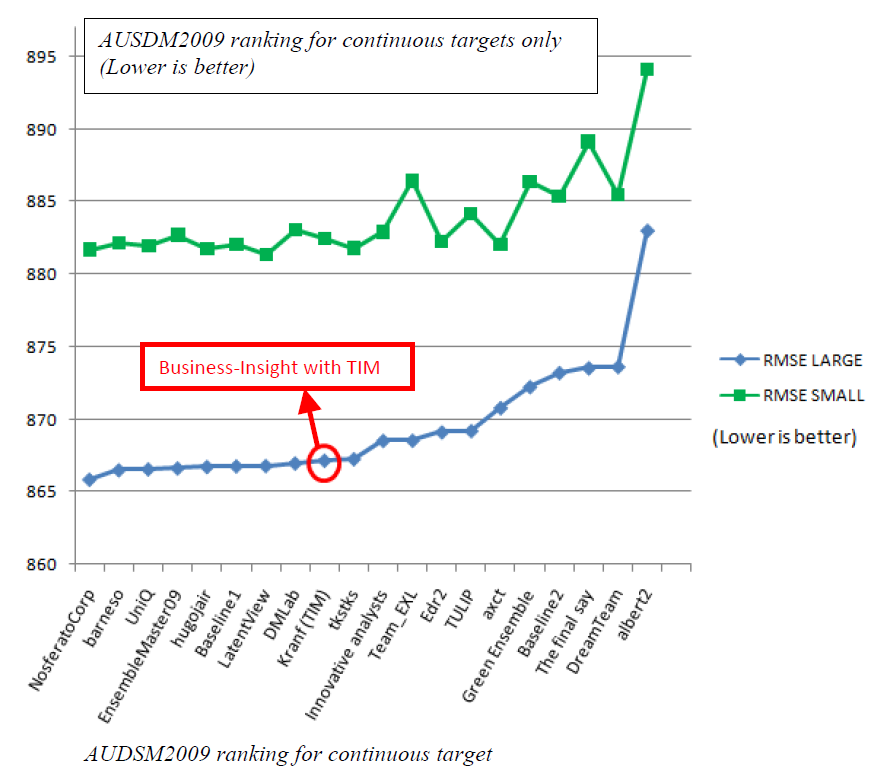
We did perform best on the binary prediction problems: on these problems our ranking at the competition is 3 (on the large dataset) and 4 (on the small dataset). Our global ranking is 5.
Some comments about the competition
- The organization committee was very efficient. Many thanks!
- The old engine of TIM (and RANK) was previously based only on the LASSO algorithm. On this dataset, the LARS/LASSO algorithm as implemented inside the SAS software behaved very poorly. The low-quality SAS implementation might be the cause of this low ranking. This poor behavior is illustrated by the “EnsembleMaster09” team that used the LASSO algorithm on the “large AUC” task and obtained a very poor accuracy: they were “the last but one” with an AUC of 52% (we obtained an AUC of 69% with TIM) (see the attachment “lasso.png” for the exact rankings on the LARGE AUC task).
- For the RMSE challenge, we used only one simply, straight-forward “continuous” predictive model. Instead of one continuous predictive model, we could have used 5 “binary” predictive models. In this case, the final prediction is simply the results of a continuous model applied on a dataset containing only 5 columns that are the predictions obtained from the 5 “binary” predictive models. This should have given better results than one “big” continuous predictive model. We didn’t try this approach by lack of time and because we had no idea that our final ranking at the competition would be so high. If we had known in advance our final ranking, we would have invested a little bit more time in the competition on these continuous predictive models.
- All the competitors that obtained a better ranking than us were using “ensembling” techniques: their “final” predictive model is indeed a mixture (an ensemble) of many different predictive models. This technique is:
a. prohibitively slow because it requires to build thousands of different models.
b. not applicable in a real-world industrial context because of the complexity of the deployment of these “meta-models”.
c. somewhat disturbing because the columns of the competition dataset are already the output of many different predictive models built using “ensemble techniques”. If we start using “ensemble techniques” to combine the output of predictive models built using “ensemble techniques”, we can push this logic even further and do the following:
– build many predictive models using ensemble technique (in the same way that the AUSDM2009 competition dataset was generated) (iteration 1)
– build many predictive models using ensemble technique to accurately combine all the models build in iteration 1 (as the first competitors of the AUSDM2009 competition did) (iteration 2)
– build many predictive models using ensemble technique to accurately combine all the models build in iteration 2 (iteration 3)
– build many predictive models using ensemble technique to accurately combine all the models build in iteration 3 (iteration 4)
– …
There are no limits to the number of iterations that you can do, using ensemble technique. The question to ask is: “Does this really worth it? Does the additional accuracy in AUC or RMSE justify using such cumbersome technique?”. Indeed, if you are using TIM to create your predictive models, the prediction accuracy of the “simple” predictive models delivered by TIM is already so high that I personally think that it does not worth the trouble of using “ensemble techniques”. This is not true if you are using another datamining tool. Anyway, the TIM software directly offers you “out of the box” all the required tool to do “ensemble technique”, if you really want to go in this direction.
We spent less than one-half-man-hour (and around 6 computing hours) on these 4 tasks and, thanks to TIM, we are now in the “top winners” of the competition. We are very pleased by the efficiency of TIM, both in terms of computing speed and accuracy.