As data scientists, we have been let to believe that our task is to get the best model that will optimally fit our data, and that every effort is worth it. This is, after all, how Kaggle masters are made, and what defines the champions of data science.
This may be the case in some situation where the data is incredibly stable, and the objectives do not change over time, but business usually does not give us this luxury. Time is essential, and change is our constant.
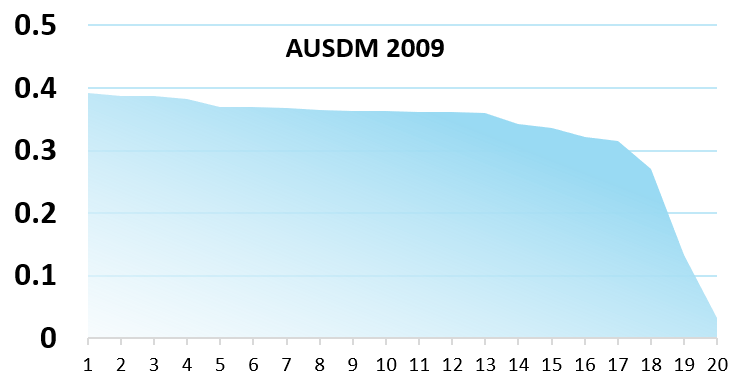
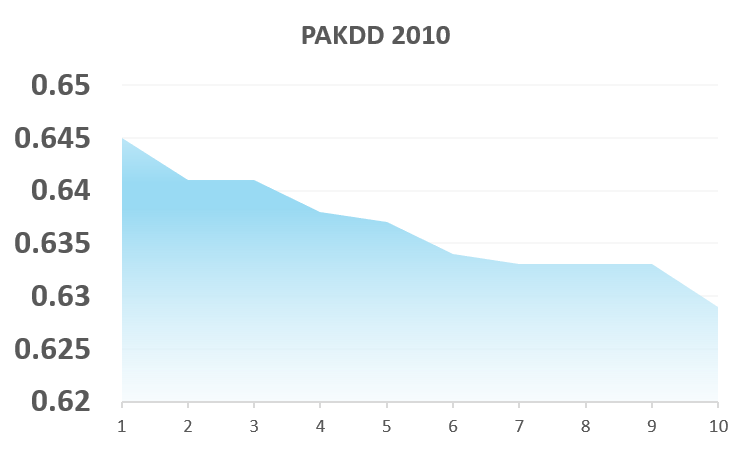
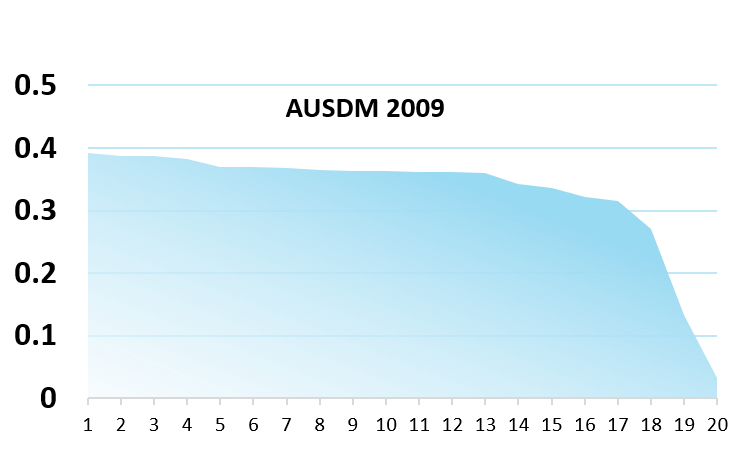
And even if time was an illusion (and lunch time doubly so, apparently), the effort / impact relationship is usually not that big, as illustrated in the comparative results of international competitions (where the winners often put weeks or months of efforts to get just a few points of AUC more than teams who put hours or days)
Let’s assume we are working on a churn problem for a telecom company. Market dynamics change quickly, as we detect a pattern of customer churn based on the available offers at the time of data collection. Our customers leave because at the time of observation they are facing a specific set of competitive offerings in terms of price, options, etc. This pattern will change with every new bundles, every campaign of ours, or our competition. And in Telecom, this is often.
It means also that once we detect a pattern, customers will start churning immediately, usually following a Negative Binomial distribution. if you’re lucky, it will look like the white line (customers with detectable patterns will churn heavily in the next 3-5 weeks), and if you’re unlucky (hint: most of us are), they will start canceling their contracts very quickly.
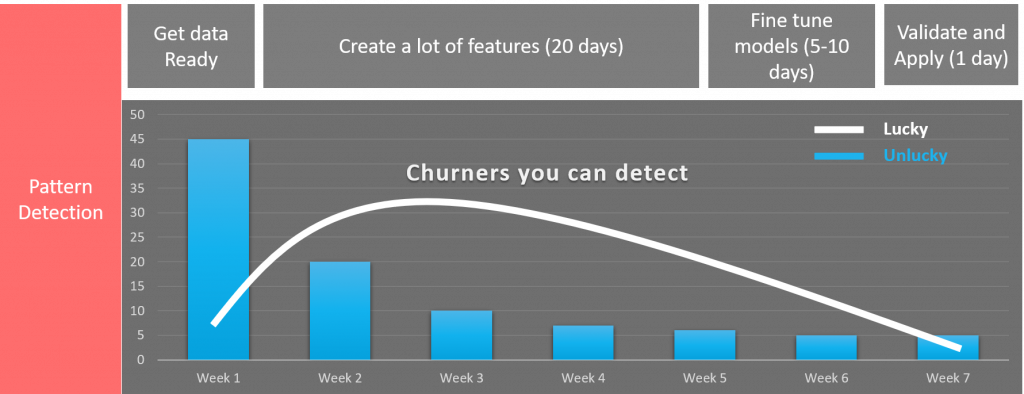
Churning pattterns
So, time is essential (and lunch time, doubly so). Let’s make a few assumptions and say we get all the data ready in a day or two, and that a retention campaign will have a 60% success (which is very high) on a good model, 20% on a fair model (which is comparatively ridiculously low, just to prove a point). Let’s assume there are 10.000 churners detected, and we are “unlucky”.
Let’s first build a “fair” model: we apply features from previous models and quickly build a Lasso regression with a decent AUC, we can get this baby out in about 3 days. On week 1, we lose 45% of all churners, after 3 days let’s say 25% are gone. We can retain 20% of the remaining 75% of the total base, or 1.500 customers (0.2*7.500).
Or, let’s imagine that we take the road of the perfect model: we invest 20 days in creating new features, spend 10 days fine tuning parameters and testing out all possible algorithms before we combine them to have the best model in the world, and just like that, 30 days have passed. We are at week 5. 85% of the churners are gone, threw away the prepaid chip and left without remorse or even a breakup message. We can still retain 15%, with 60% success, so 900 people (0.6*1500). If each customer has a CLTV of $1.000, we just lost $ 600.000 thanks to our super duper model, although we will only report that we saved the $ 900.000 thanks to a successful retention campaign. Nobody is fired! But it would be very optimistic to call this a success!
What if the quality difference looks like what happens in reality, and you have 57% success instead of 60? With the “OK” model, you keep 0.57*7500*$1000=$ 4.275.000.
And this is assuming that there is no model decay!
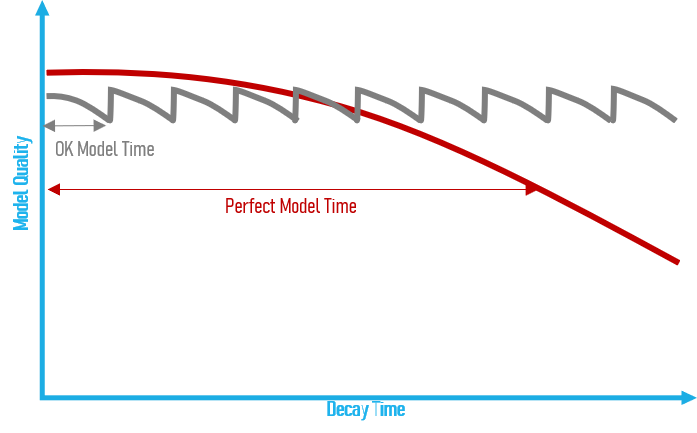
As time passes, models naturally deteriorate because the situation has changed, patterns are different, even the target definition could change slightly. As we spend time refining a model, it becomes more and more irrelevant, to the point that by the time it gets into production, its actual impact on the market might be inferior to the quick model we could have developed in a fraction of the time. By the time the model goes into production, it might have decayed to .55, and yield only yield $825.000. You just lost $3.450.000, and you don’t even know it.
So, is there no place for a “perfect” model? In many situations, variables will not change over time: the physics in a nuclear reactor will not change, the relative position of my eye and nose will not change in the next decade, how a cancer cell looks like in a radiography is not going to change. In all these case, it is definitely worth investing months to get a perfect model, if there is a reward (lives saved, for example).
In commercial operation, however, things change too fast and the decay effect kicks in from the start, and every day that goes by is money lost by companies. We need put a quick model into production and start acting on it, while we keep on working and refining it. We improve the question. We capture more recent data to make sure the patterns are not shifting with competition’s reaction to our retention campaigns (or even shifting patterns do to our own actions!). We build new features that will be fed into our “quick models” (parameters will change, but the features often stay relevant!). And we make sure our model is not over-fitting the data!
To do this, we need algorithms that are robust enough to give us trustable, interpretable models. We need to make sure we can assess overfitting in a very short time, get results in a very short time (and low cost!), and control decay as much as possible with systematic drift reports. And that’s why we invested years of R&D in Timi Modeler.