NEVER WAIT ANYMORE
FOR A DATA TRANSFORMATION
FAST SORTING
FOR A TELECOM
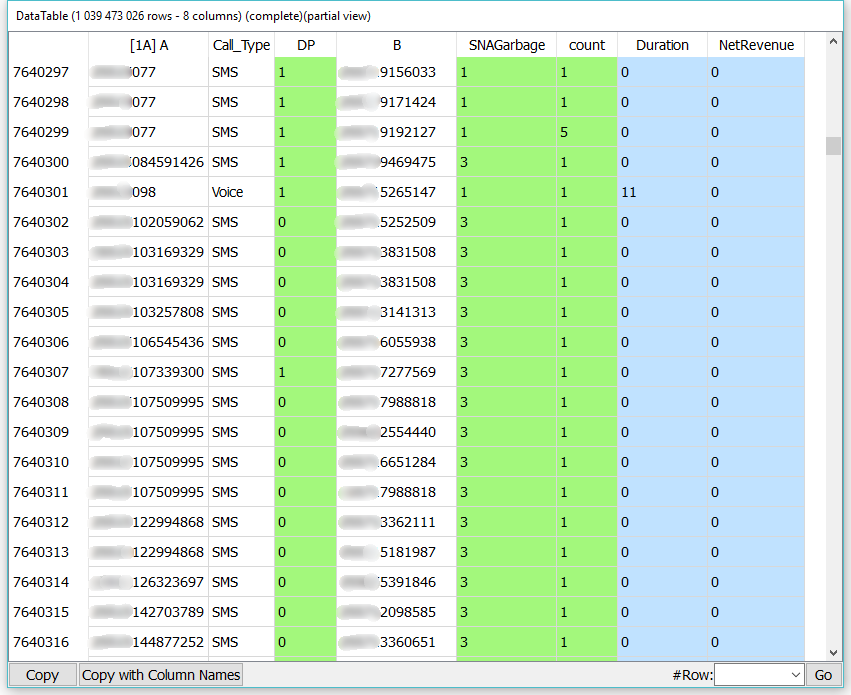
Anatella sorts a large CDR (Call Data Record) table with 1 billion rows and 8 columns. This 171 GB CDR table (as text file) is sorted in 99 seconds using less than 300MB of RAM.

CALCULATION OF AGGREGATES
FOR A SUPERMARKET
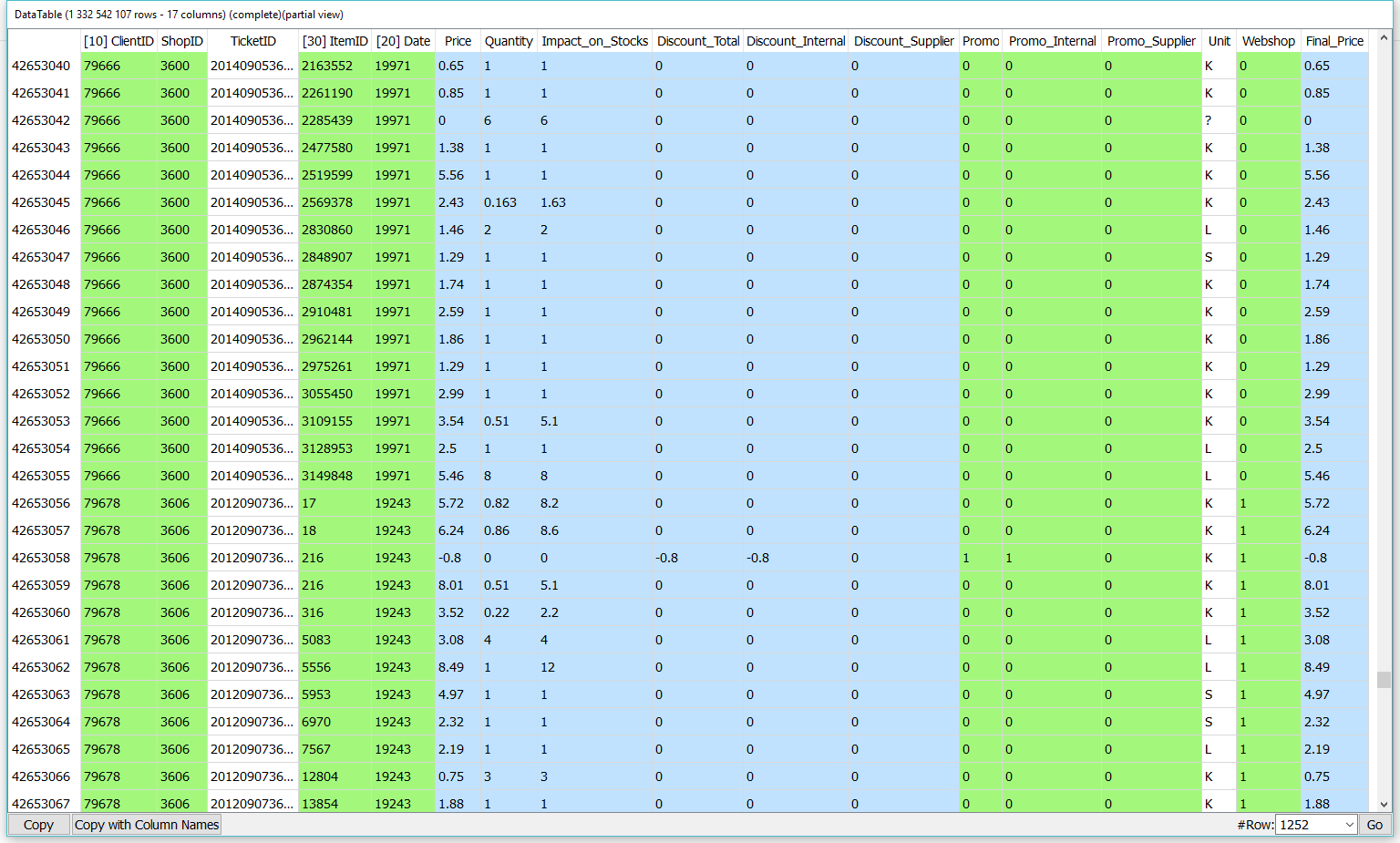
From the ticket table (1.3 billion lines and 17 columns), Anatella calculates the following aggregate: the percentage of purchase through the web. This KPI is computed in 70 seconds using less than 50MB of RAM.


UNMATCHED SPEED
FOR PREDICTIVE MODELING
BUILDING A
HEALTHCARE MODEL
Using a single PC with Modeler, a healthcare institution built a high-performance model on 6 million rows, 24.000 variables in only 4 hours (individual risk of heart attack within 6 months).
BUILDING A
FRAUD PREDICTION MODEL
With Modeler, an energy company built a fraud prediction model in only 20 minutes with 18.000.000 rows and over 200 columns.
HIGHLY ACCURATE MODELS
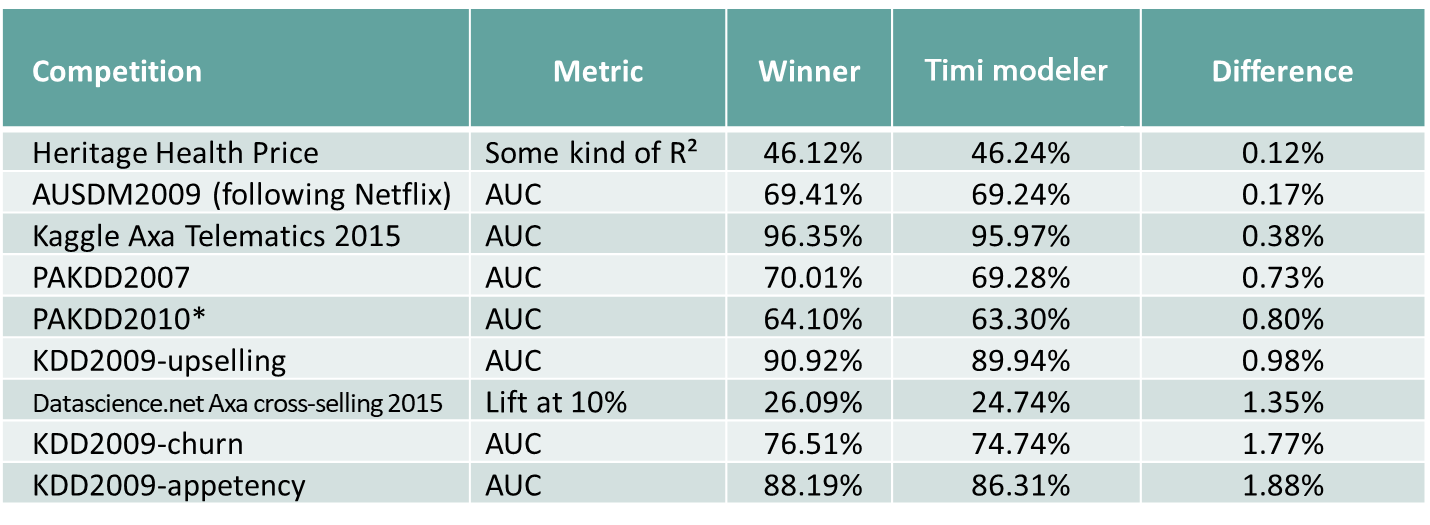
Speed of course would be irrelevant without precision. Since 2007, Modeler produces predictive models that are significantly more accurate than other off-the-shelves tools. This fact is demonstrated by our outstanding results at various world-level data mining competitions (KDD Cups) and by real industrial benchmarks.
NOTICE
All examples mentionned on this page are running on this laptop:
