A simplified infrastructure and an unified platform
No more cumbersome infrastructure that are always “down” because of some unreliable servers. Thanks to a unique infrastructure approach, TIMi is optimized to provide you with:
- …the highest reliability (to securely deploy all your analytical solutions in production)
- …the ultimate “playground”, so that your data scientists can have fun exploring your data and test the craziest ideas. The incredible computing power offered by TIMi allows to test even the most insane ideas!
- …the highest horizontal scalability (e.g. near-zero incompressible time)
With TIMi, no down-time: You can play with your data all day long! That’s not even working anymore! 😉
Exploration and Production phases
All “Advanced Analytics” architecture/infrastructure must take into account that any advanced analytic project has always two phases:
- Phase 1: The “Exploration phase”
What are the characteristics of the “Exploration Phase”?- The Analysts/Data Scientists are developing a new KPI, a new predictive Model or, in general, creating new results through the analysis of data.
- The Analysts/Data Scientists typically run very heavy data transformations, very heavy computations, searching for the “golden egg”. On a “standard” infrastructure where all the computations are “centralized” on a central database or a central hadoop cluster, these heavy data transformations might disrupt the work of other analyst or, even worse, jeopardize the global stability of the whole IT infrastructure of the company (This is why, in most companies, the Data Scientists are not the “friends” of the IT people).
- It doesn’t matter so much if one “heavy” computation fails (e.g. because of a bad parameterization).
- The duration of the “Exploration phase” is, typically, from a few hours to a few weeks.
- Phase 2: The “Production phase”
The “Production phase” comes after the “Exploration phase” and usually lasts for years. There are usually no really “heavy” computations during the “Production phase”. The main concerns of the “Production phase” is the stability: All processes must run smoothly, without ever failing.
A first, really “Cheap” Infrastructure.
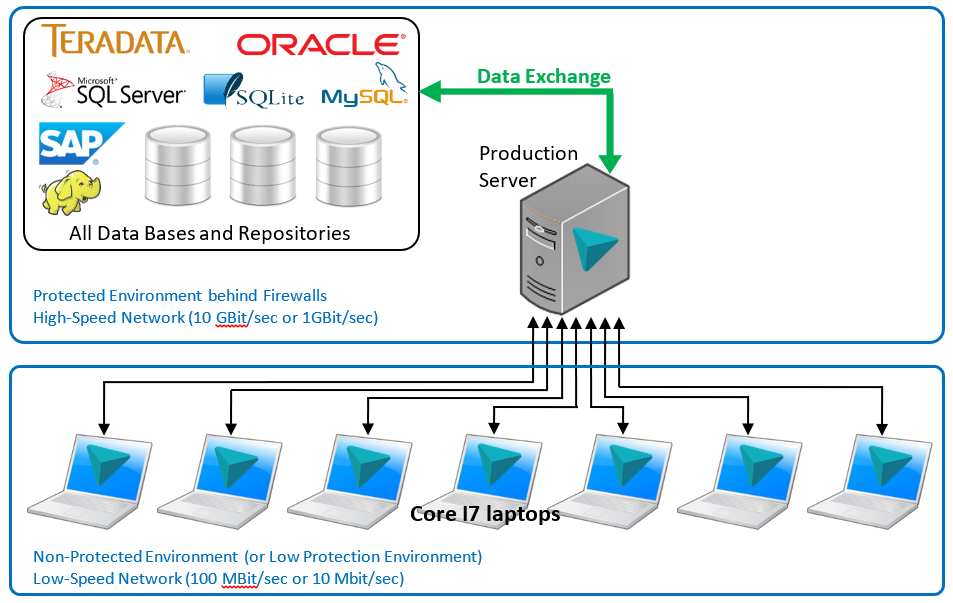
This infrastructure is very simple: One production server (that contains both your data lake and the analytic scripts that are in production) and a few laptops (one laptop per analyst). Despite its simplicity, this infrastructure is already able to handle relatively large datasets. (such as the entre clinical history of a country of 40 million people, or the phone records of 20 million customers).
During the “exploration phase”, the Analysts typically run very heavy data transformations, searching for the “golden egg” in your data. On a standard, centralized infrastructure, these *heavy* data transformations might disrupt the work of other analysts or, even worse, put in danger the global stability of the whole IT infrastructure of the company. This disastrous situation will never happen with the proposed solution here above: Indeed, each of the Data Scientists is using its own CPU without consuming any resource from the production servers (or from other Analysts). This infrastructure is only made possible by the very high-computing power delivered by TIMi on a common server.
Most companies are starting with such an infrastructure (because it’s really cheap: just one “Core I7” production server and a few laptops) and progressively “builds up” step-by-step to the “Final” infrastructure given below, as their analytical maturity grows.
The “Final” TIMi Infrastructure.
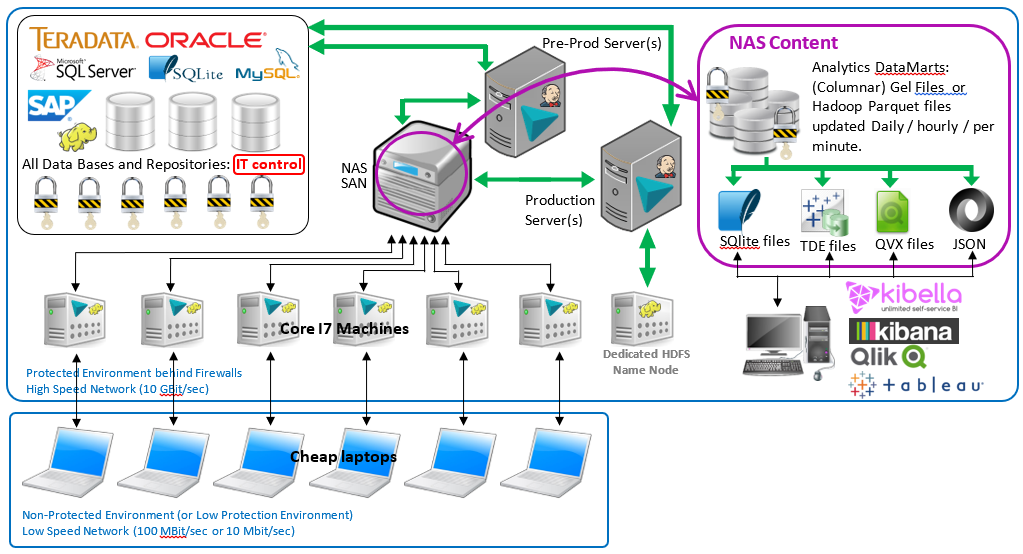
This infrastructure includes:
- A dedicated NAS/SAN for the data lake storage. Use RAID6 inside your NAS/SAN to have a system resilient to 2 simultaneous crashes.
- A pre-production server, to test all your Anatella graphs before putting them in “real” production on the production server
- A daily importation of your legacy data sources (such as SAP, Oracle, etc) to “feed” your data lake.
- A daily/hourly update of all your dashboards: Anatella allows a high-speed and automated publication of any data located inside your data lake to all common report/BI solution, such as Tableau, Qlik, Kibella, Kibana, etc.
- A secured environment: your data never leaves your premisses
- An unlimited scalability in terms of computing power: if you have more data scientists, just add more PC’s.
- An unlimited scalability in terms of storage: The proprietary file formats offered by TIMi (i.e. the .gel_anatella files and the .cgel_anatella files) are compressing your data so efficiently that it’s very unlikely that disk space will ever be an issue. But, if that’s the case, you can still store your “old & cold” data directly on HDFS, for truly unlimited data storage.
- No “locked in” situation: Anatella is designed to work with almost any other technologies. Prepare your data, and export it to Tableau, Qlik, SQLite or any database of your choosing for global deployment. Exporting to any standard format from Anatella is just 2 clicks of the mouse.
This final infrastructure is a “dream come true” for all data scientist!
Near unlimited power, near unlimited storage, near unlimited Fun! 😉