Customer-Life-Time-Value forecasting
This kind of predictive model is actually a more advanced form of churn model.
Basically, in a churn model, we are computing the probability that a given customer moves from the “normal customer state” to the “churned customer state”. Let?s illustrate this with a small graph:
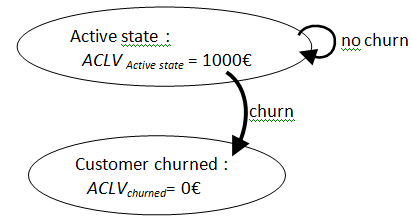
The “
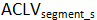 ” means “Average Customer life-time value” of all the customers inside the segment_s: this value must be given by the business analyst or the marketing team.
” means “Average Customer life-time value” of all the customers inside the segment_s: this value must be given by the business analyst or the marketing team.
The forecasting of the CLV(Customer-Lifetime-Value) of an individual “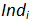 ” that is currently inside the “active state” segment is:
” that is currently inside the “active state” segment is:
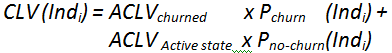

…where
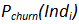 is the probability of churn in the next 3 months for the individual ““.
is the probability of churn in the next 3 months for the individual ““.This probability is computed using a predictive model (that is typically built with TIMi).
Here is another chart that explains the more general case:
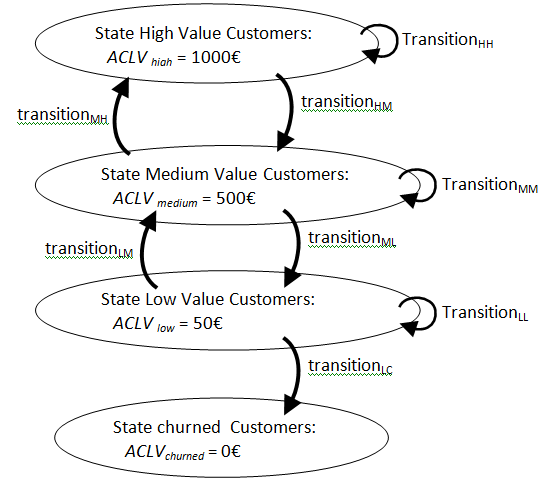
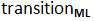 , you must create a predictive model that estimate the probability that a customer inside the state “Medium-value-customer” switches to the state “Low-value-customer” in the next 3 months. As you can see, the creation of the whole system that is used to forecast the real CLV (3 months in advance) of a customer is a very time-consuming process because it involves creating many (many!) different models (one for each transition). Hopefully, with TIMi, creating a predictive model is quite fast. This is why TIMi is the optimal solution when building a system to predict the real CLV of a customer.
, you must create a predictive model that estimate the probability that a customer inside the state “Medium-value-customer” switches to the state “Low-value-customer” in the next 3 months. As you can see, the creation of the whole system that is used to forecast the real CLV (3 months in advance) of a customer is a very time-consuming process because it involves creating many (many!) different models (one for each transition). Hopefully, with TIMi, creating a predictive model is quite fast. This is why TIMi is the optimal solution when building a system to predict the real CLV of a customer.
Once all the different predictive models are computed, there exists inside our analytical ETL tool (Anatella) a small box that directly predict the CLV of each customer. This box is quite simple: For example, the predicted CLV (in a 3 month window) of an individual “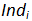 ” currently inside the state “Low-value-customer” state is:
” currently inside the state “Low-value-customer” state is:
 ” currently inside the state “Low-value-customer” state is:
” currently inside the state “Low-value-customer” state is:
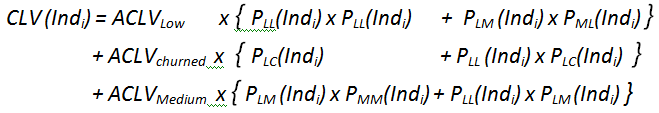
Datamining vendors are often searching to add new functionalities inside their tool instead of improving the functionalities already provided. Indeed, its very difficult to improve prediction accuracy (i.e. to obtain a higher lift on the TEST SET) and it is a lot easier to provide a new (barely working) functionality like this “CLV estimation system”.