
¿Les impresiona la precision de los modelos de IA?
Hace poco vi un interesante video de Eric Siegel, en el que habla de la Falacia de la Precisión. Este es un tema del que hablo a menudo y que toqué (aunque no tan claramente como él) en otro post hace unos años, cuando escribí sobre las curvas de clasificación, ROC y Lift (ganancia). Siegel acuñó muy bien el término y me motivó a escribir este pequeño post, y un término que utilizaré con frecuencia a partir de ahora.
En la comunidad de la ciencia de datos, tenemos una mala tendencia a exagerar la calidad de nuestros modelos, a menudo no conscientemente. Simplemente estamos entrenados para utilizar los KPI equivocados, y la población en general los entiende aún peor que nosotros.
Cuando aprendí las técnicas de clasificación a finales de los 90 y principios del 2000, el KPI que todos utilizábamos era la tabla de clasificación, expresada en porcentaje, y nadie parecía tener problemas con ella.
Luego tomó el relevo el ROC, que ya es una gran mejora, pues expresa el componente dinámico de una tabla de clasificación. La clasificación asume un corte constante en términos de probabilidad, a menudo el 50% o un punto «óptimo» establecido para maximizar la tasa de aciertos, o la precisión.
Pero esto da una confianza muy engañosa.
Tomemos este sencillo ejemplo de un modelo de predicción muy bueno
.
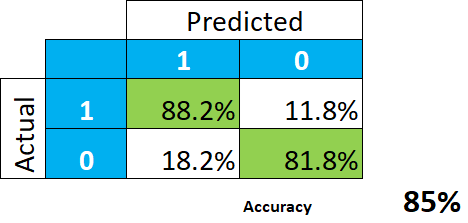
En efecto, esto parece maravilloso. La conclusión es que el modelo nos da un 85% de aciertos (la media entre 88,2 y 81,8), o sea, de precisión, y no debemos esperar muchos errores de clasificación.
¿o si?
A menudo, la data es realmente desequilibrada, y la probabilidad apriori está al 1 o 2%. Pongamos un ejemplo, digamos que la probabilidad de declararo una renta alta, que está en torno al 6%. Por supuesto, la curva ROC sería tan buena como la tabla de clasificación, o incluso mejor:
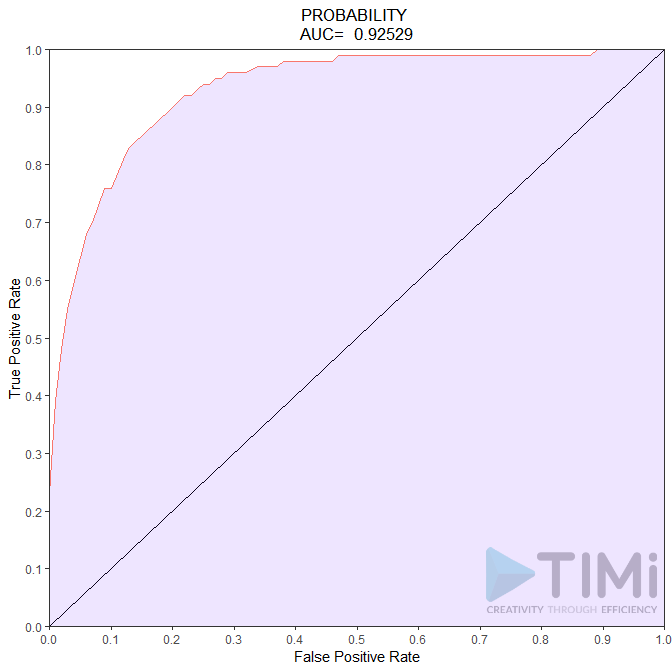
Entonces, ¿qué concluimos ahora? Tenemos un modelo increíble, con una calidad del 85 al 92,5%. Nada puede ir mal, y lo que un no científico de datos entenderá es que todos los contribuyentes serán identificados, con quizás un 7,5-15% de error. No es el caso, y esta mala (¡asusta!) interpretación es culpa nuestra.
Veamos cómo se clasifican realmente los datos, en números absolutos. Y en lugar de centrarnos en cuántos de los VERDADEROS positivos y negativos se clasifican en porcentage, observemos lo que el modelo nos dice que es un positivo..:
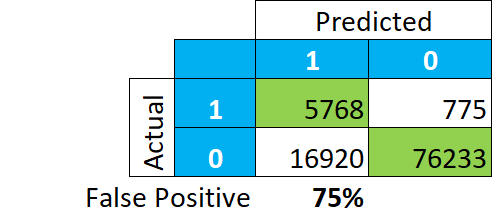
Esto pinta una historia completamente diferente. Entre nuestra clasificación de «VERDADEROS», el 75% de los registros son en realidad «FALSOS» (16.920/(5.768+16.920)). Esto significa que si miramos a los contribuyentes de este grupo, no encontraremos el 85-92% de los contribuyentes reales, sino sólo el 25.
La curva GAIN nos permite entender mejor lo que está pasando:
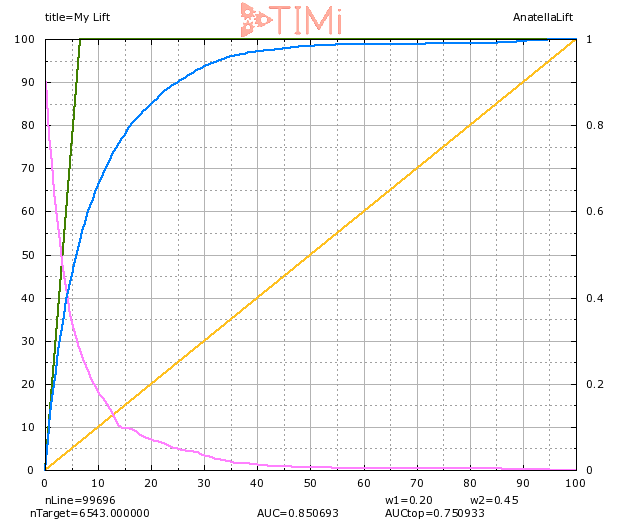
Cuando seleccionamos el 20% de la población (en el eje de las X), vemos efectivamente que se identifica el 85% de los objetivos. Pero también vemos que seleccionamos una muestra aproximadamente 3 veces mayor que nuestro grupo apriori (visible en la línea verde:6% en el eje X), por lo que podemos esperar que MUCHOS registros de este grupo sean realmente negativos. Con el 20% de la población seleccionada, la probabilidad de que el registro menos probable sea verdadero es de alrededor del 6-7% (véase la curva azul claro).
Seamos realistas por un momento: en realidad no clasificamos las cosas. Y si lo hacemos, admitamos que somos pésimos en ello. Lo que podemos hacer correctamente -como se muestra aquí- se llama clasificación. Los modelos de clasificación son una herramienta increíble para priorizar y ordenar registros, ayudan a tomar decisiones que generan millones o euros en muchas industrias. Pero no estamos ni siquiera cerca del punto en el que un algoritmo nos dirá con un bajo margen de error quién es un mal pagador, quién es un futuro mal estudiante o quién es un futuro mal empleado. Nos orientará en la dirección correcta, pero a menos que la probabilidad real de que ocurra un registro sea >0,99, es peligroso, e irresponsable, decir que lo «clasificamos».
Deja de tener miedo a la verdad: este es un GRAN modelo, si tomas el 2% de la población con probabilidad más alta, tendrás un 70% de positivos reales (¡en lugar del 6%!), la «lift» es de 6,5 al 10% de la población. No es necesario generar una falsa expectativa y hablar de esas tasas del 85%+ .


