
¿Cual es el mejor procesador para un cientifico de datos?
Una pregunta recurrente en muchos blogs de ciencia de datos es «¿qué portátil recomiendan para hacer ciencia de datos?». La pregunta es muy interesante, porque tiene varias respuestas y depende de tu necesidad.
Por ejemplo, si planeas usar soluciones en la nube (porque no tienes otra opción) no importa cuál equipo elijas porque los servidores remotos harán todo el trabajo. Sin embargo, al momento de elegir un servidor en alquiler, es importante revisar las características técnicas del servidor, y este articulo puede ayudarte en el proceso de selección.
Ahora, si quieres realizar procesamiento de imágenes o de vídeos, necesitas básicamente un buen GPU (o acceso a una nube de GPU: es una de las situaciones en la cual la nube SI hace mucho sentido y podrás tener un alto impacto en el tiempo de computo).
Ahora, si vas a trabajar en R y Python – ya que es el estándar en estos días – simplemente busca un PC con una CPU rápida, y alta capacidad de RAM. Python y R son «mono-hilos» (y aunque existen librerías multi-hilo, la mayoría de las operaciones no se distribuyen).
Python es particularmente lento, pero al menos si tienes una máquina potente no te vas a deprimir por ello. Tiene unos frameworks de cálculo en paralelo, pero la ley de Amdahl no juega a nuestro favor, y el impacto para la mayoría de los casos son limitados.
R suele ser más veloz (¡solo si está bien programado!) Y puede correr el paralelo con openR o doParallel. Pero en lo general, será mono-hilo. Entonces busca el procesador más veloz en frecuencia «Single Core».
Sin embargo, para ambos lenguajes, algunos algoritmos como xgBoost pueden usar varios núcleos, y si la mayor parte de tu trabajo es ajustar algoritmos (y no preparar datos), tener varios núcleos vale la pena.
Si piensas hacer ciencia de datos con Anatella, porque sabes lo fácil que es procesar miles de millones de registros en un solo PC / servidor, entonces querrás algo intermedio, aquí la respuesta no es sencilla.
Anatella por defecto usa un solo núcleo cuando corre un grafo, pero se pueden optimizar para correr en entorno multihilo. En general, no es necesario: Anatella corre tan rápido que no vale la pena invertir tiempo en optimización; sin embargo, cuando se incrementa el volumen de datos, o cuando la velocidad es esencial en un proceso, es común ajustar los parámetros y empezar a distribuir los subprocesos. En este caso, es importante tener varios núcleos, y tener una puntuación «multiproceso» alto. Sin embargo, más de 32 núcleos no valen la pena (por la ley de Amdahl).
Existe un gran recurso para comparar CPU en CpuBenchmark. Si bien facilita ver el rendimiento de una CPU en particular, averiguar cuál es la mejor según múltiples criterios no es lo más fácil. Así que, ¡vamos a usar Anatella para averiguar lo que quiere Anatella!
Para elegir correctamente una CPU, debes considerar dos dimensiones:
1- la velocidad de un solo hilo, porque la mayoría de las cosas no se pueden distribuir, y la velocidad mono-hilo es la única forma de aumentar la velocidad en los cuellos de botella como ordenamiento y agregados, y
2- la velocidad multi-hilo , porque cuando tenemos grandes volúmenes de datos, es necesario ejecutar varios procesos juntos. Timi Modeler también hace un amplio uso de multi-threading.
Por eso me pareció importante guardar las siguientes páginas para construir nuestro análisis.
Puedes bajar el script (los html ya están incluidos), ejecutalo para ver esta gráfica donde puedes observar los 175 mejores procesadores, evaluados en dos dimensiones (el X para el score de “SingleThread Rating” y el Y para el score de “MultiThread Rating”):
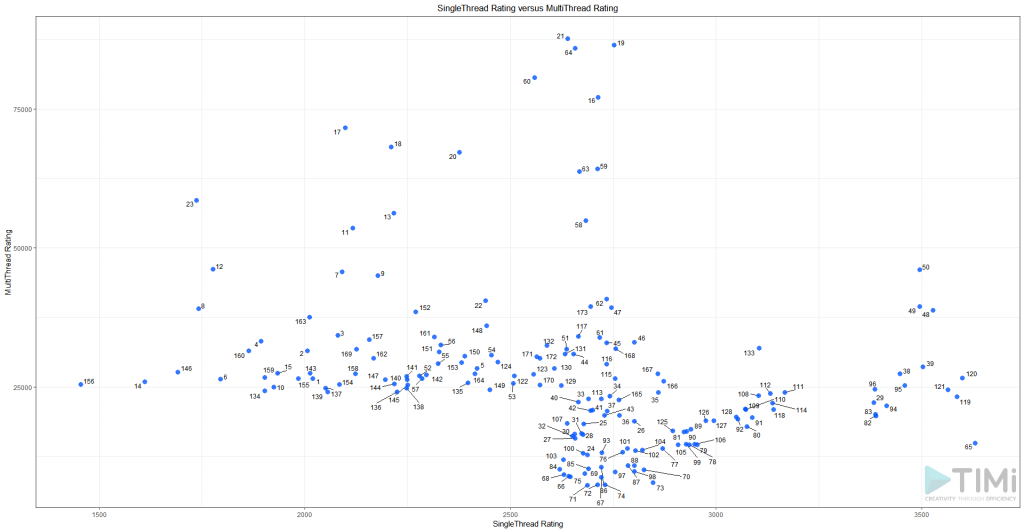
De esto surge algo interesante: parece haber un punto de corte en 3000 para la velocidad de un solo hilo. Como este KPI es nuestro principal cuello de botella, vamos a filtrar los que tienen menos de 2000, y añadir algunas opciones en nuestro gráfico:
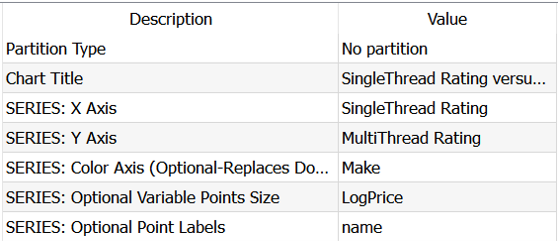
Queremos ver mejor a AMD frente a Intel, así que trazaremos el color como «Marca» y para hacernos una idea del precio, pondremos el «log(Precio)» como tamaño de la burbuja. Adicional, asignaremos el «nombre» en el gráfico: ahora que hay menos puntos, no tiene sentido visualizar una tabla al lado.
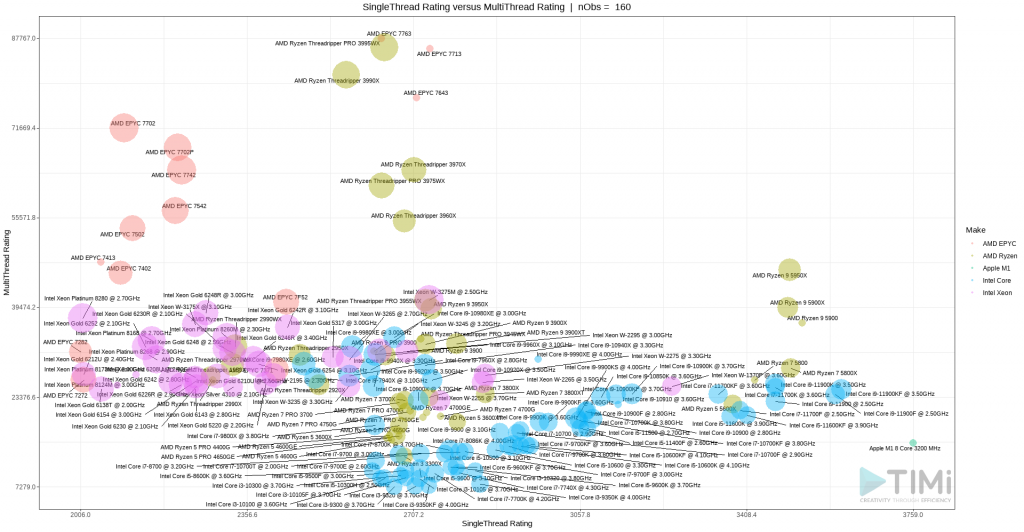
La gráfica sigue bastante cargada, pero ya podemos observar unos grupos de interés: los AMD EPYC y AMD Ryzen Thread Rippers tienen un performance increíble en multithread, lo que permite tener los mejores servidores web y tener muy buen performance para algunos juegos. Pero son bastante malos en single thread, razón por la cual se tienen que rechazar para lo que nos interesa. Pongamos el foco en todos los con un score superior a 2000.
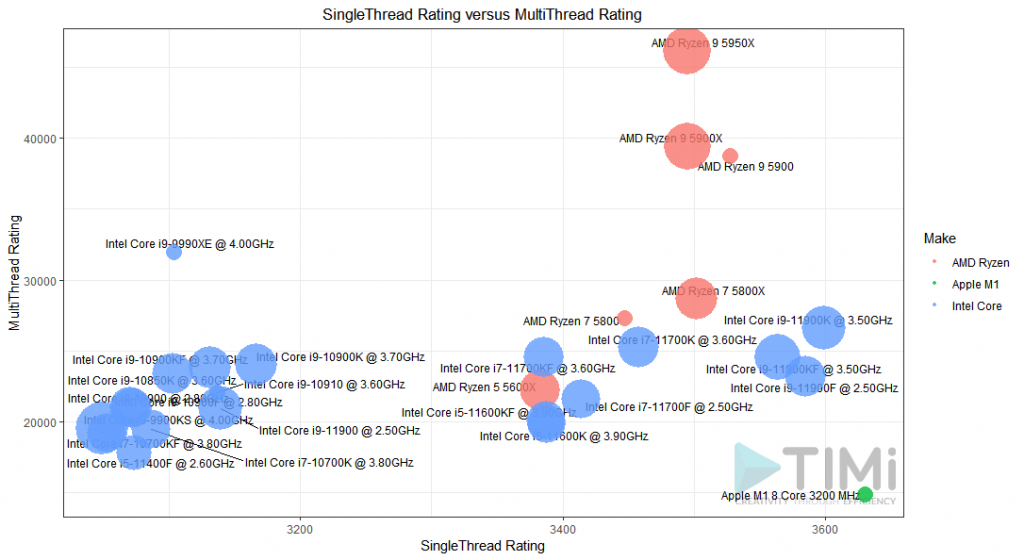
¡Y tenemos un ganador! El AMD Ryzen 9 5900 es sin duda la mejor relación calidad-precio. Mientras que los tres nuevos Intel i9-11900K , i9-11900KF e i9-11900F son ligeramente mejores en cuanto a velocidad mono-hilo, la velocidad en varios hilos del Ryzen 9 los supera.
Si el presupuesto no es limitante, ¡el mejor procesador es el AMD Ryzen 9 5950x ! Está dentro de los mejores en velocidad «mono hilo», y también alcanza muy buenos resultados en el cálculo distribuido. Con sus 32 núcleos, hasta los procesos más complejos podrán correr a una gran velocidad, y Anatella será capaz de procesar miles de millones de registros en condiciones óptimas. Nunca pensé que vería el día, pero sí: ¡vamos AMD!
Para proyectos de ciencia de datos «single thread» con R & Python, puede parecer que el Mac Book sea su mejor amigo. Pero ¡cuidado! Si piensas usar rutinas de álgebra (o prácticamente cualquiera librería interesante de ambos entornos), van a depender de la eficiencia en instrucciones vectorizadas, que solo están disponibles en procesador Intel o compatible (AMD). El procesador M1 no es optimizado para SSE3 y eso castiga su tiempo de cálculo, a pesar de una frecuencia superior. Sería interesante hacer una comparación específica, pero para ciencia de datos, estos nuevos procesadores i9-11900 de Intel son probablemente los que necesitan.
Nota: Los gráficos fueron generados con datos de mayo del 2021. Las cosas cambian rápidamente, ¡puedes obtener resultados ligeramente diferentes cuando ejecutes el script con datos en vivo!
¿Como capturamos la data?
Este pequeño script combina técnicas de web scraping y text mining con Anatella. La primera parte del script obtiene las partes de la tabla que nos interesan, es decir, la url, el nombre y el rendimiento, tanto de la gama alta como del rendimiento de Single Thread. Cómo están ordenados, nos quedamos con los 100 mejores de cada uno, los anexamos, eliminamos los duplicados y listo.

El segundo paso es descargar todas las URL que se han extraído. Para ello, utilizamos la acción MultipleDownAndUpload, que requiere una URL y una ruta local como parámetros:
El último paso es el más complicado: extraer toda la información que queremos del texto. Tu mejor amigo aquí es la acción extractRegExpPosition. Extrae el valor asociado a una etiqueta en alguna parte del texto, y asigna un nombre específico, lo cual permite rellenar la tabla para el gráfico, y guardarla en Excel.



