Fuzzy matching entre tablas:
Tableau Prep Builder vs Anatella
Si está manipulando datos con fines de análisis o visualización, es probable que se ya haya tenido que enfrentarse con este problema. Necesita crear una combinación entre 2 bases de datos, pero las entradas del campo de referencia no son las mismas. Diferencias ortográficas, terminologías diferentes, … las razones son muchas y variadas. Me encontré con este problema durante la investigación que estoy realizando para visualizar los flujos de migración. Tuve que resolverlo utilizando una solución ETL (Extract – Transform – Load) que gestiona el fuzzy matching. A continuación le voy a explicar cómo lo hice.
Resumen
- Introducción
- Problema
- Solución 1 con Tableau Prep Builder (spoiler: no funciona)
- Solución 2 con Anatella (spoiler: funciona)
- Conclusión

Introducción
Como parte de un proyecto personal sobre la visualización de los flujos migratorios en Europa, obtuve cifras de la Unión Europea (la base de datos tiene 242500 líneas). La base de datos detalla el número de migrantes según su país de origen y su país de destino. Así que, por un lado, tiene unos 200 países de origen y, por otro, unos 30 países de destino. Por lo tanto, me pareció apropiado visualizar estos flujos a un nivel de granularidad superior: la región de origen.
Podría haber hecho grupos de países directamente en Tableau, pero con 200 entradas resulta bastante tedioso (y no necesariamente libre de errores). Preferí buscar una base de datos de los diferentes países y la región “oficial” a la que están adscritos. La encontré en el sitio web de la Organización Mundial del Comercio (World Trade Organisation).
Problema
El problema es que el nombre de un país no es exactamente una constante. He aquí algunos ejemplos:
- “Cabo Verde” en la lengua nacional del país, “Cap Verde” en inglés.
- “Antigua and Barbuda” en un archivo, “Antigua & Brabuba” en el otro.
- “Bahamas” y “Las Bahamas”.
- “Central African Republic” y “Central African Rep.”
- “Cook Islands (NZ)” y “Cook Islands”.
- “Ivory Coast” y “Cote d’Ivoire”
Antes de que los fanáticos de “buscar y reemplazar” en Excel me acusaran, busqué una solución que fuera más económica en términos de transformaciones.
En definitiva, como habrás comprendido, podría haber dedicado unas cuantas horas a limpiar mi base de datos y a hacer que las entradas fueran “revisadas” para que la unión pudiera funcionar. Pero necesitaba una solución más elegante.

Solución n°1 (la que no funcionó)
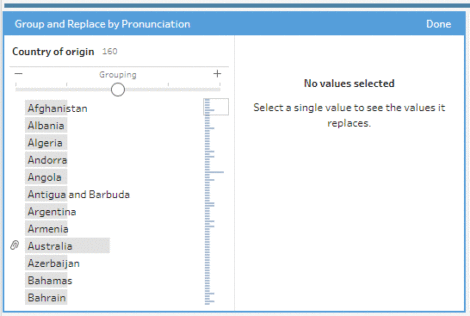
Como mi objetivo era visualizar mis datos en Tableau, la primera solución que probé fue utilizar Tableau Prep Builder. Su ventaja es que el proceso ETL es gráfico y los problemas son evidentes (véase más abajo, Tableau Prep los marca automáticamente en rojo). He resaltado en amarillo los que comentaba más arriba. Quedaba por ver si era posible realizar un fuzzy join entre las tablas.

Investigando un poco más, encontré este artículo que describe un método de agrupación por pronunciación. Esta opción está disponible aquí:

Las agrupaciones son útiles dentro de la misma tabla para detectar variaciones. Las explicaciones técnicas están aquí. El algoritmo utilizado se llama Metaphor 3 (open source, ver aquí).
La preocupación es que las agrupaciones sólo son posibles en una sola tabla. Debería haber hecho una combinación, luego una agrupación y finalmente una deduplicación manual. Este proceso es posible cuando se tienen pocas entradas, pero el método no habría sido ampliable.
Ha llegado el momento de hablar de la segunda solución.

Solución n°2 (¡ésta ha funcionado!)
Para resolver mis problemas de fuzzy matching y obtener una solución escalable, recurrí entonces a Anatella.
La ventaja de esta solución (además de ser gratuita para las configuraciones pequeñas) es que tiene una herramienta de combinación acoplada al fuzzy matching. Si sabe utilizar Tableau Prep (o cualquier otro ETL), no debería tener ningún problema. El aspecto es prácticamente igual (cajas, flechas, parámetros). Para mí, la ventaja significativa de Anatella es la gran oferta de las funciones propuestas (+/-300). Este es el aspecto de la configuración para resolver el problema (haz clic para ampliar la imagen).
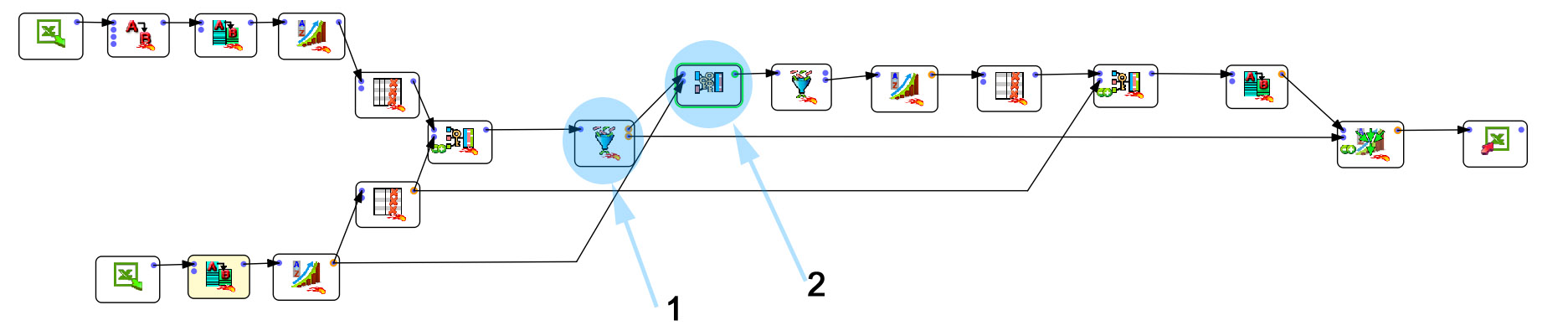
No voy a detallar todo el proceso, sino que me centraré en las partes esenciales y, por supuesto, en el fuzzy matching.
- En el paso 1, separo las entradas para las que ha funcionado la combinación (lower arm) de las entradas para las que no se ha encontrado ninguna coincidencia (upper arm).
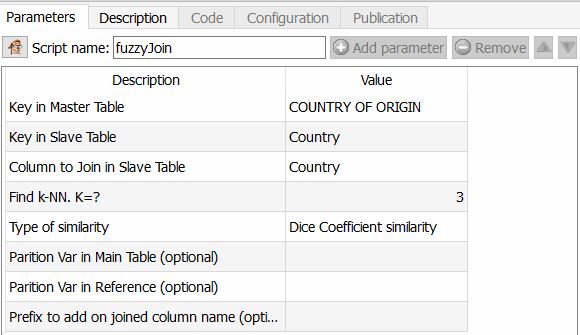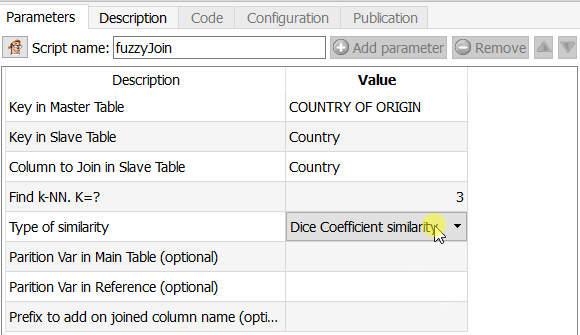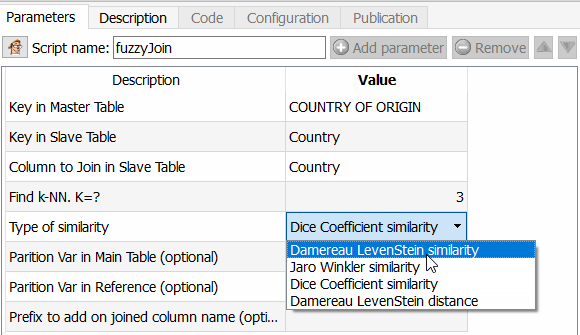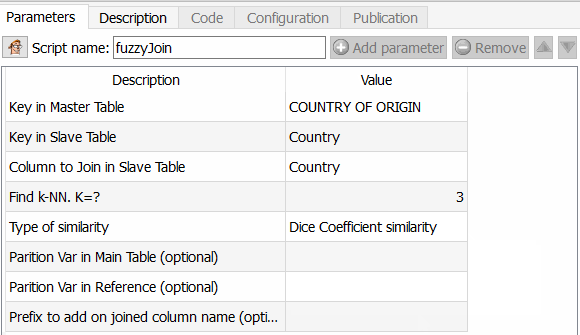
- En el paso 2, aplico el famos fuzzy matching.
Esta función es emocionante porque permite ir mucho más allá que Tableau Prep, por ejemplo, pero también de un ETL como Talend. En efecto, se puede elegir el algoritmo a aplicar para calcular la similitud entre dos campos. Como Anatella devuelve el coeficiente de similitud, es suficiente elegir un umbral y utilizarlo. Los diferentes algoritmos disponibles son el coeficiente de similitud de Dice, el método de similitud de Damereau LevenStein, el método de similitud de Jareau Winkler y el cálculo de distancia de Damereau Levenstein. Se dedicará otro artículo a la comparación de estos diferentes métodos.
Otra ventaja de Anatella es la velocidad. El proceso completo se ejecuta en 14,84 segundos (incluyendo el fuzzy matching). La parte de la combinación (hasta el paso 1) se ejecuta en 1,58 segundos, mientras que Tableau Prep Builder tarda 10 segundos.

Conclusión
Para concluir, digamos que, en mi caso de estudio (combinación de 2 tablas con Fuzzy Matching), la comparación de los 2 ETLs resultó ventajosa para Anatella. Por desgracia, la función de agrupación fonética que ofrece Tableau Prep Builder no está adaptada a la creación de una combinación. Sólo puede aplicarse a una única tabla y entonces requiere operaciones de filtrado manuales, lo que no es escalable.
Fuente: IntoTheMind


