Quel est le meilleur processeur pour la data science?
Une question récurrente sur de nombreux blogs consacrés à la Data Science est la suivante : « Quel ordinateur recommanderiez-vous pour faire de la Data Science? ».
La question est très intéressante, car il n’y a pas une seule réponse à cette question. Ce qui est sûr, c’est que la marque importe peu: Dans tous les cas, il faut un disque SSD (et faire des backups!), minimum 8 GB de RAM, et un bon choix de processeur. Le choix du CPU est le plus complexe.
Note: Il faut faire attention à la façon dans le SSD est connecté à votre « Serveur Cloud ». Par exemple, chez Amazon/Azure&GCP les SSD sont systématiquement connectés aux serveurs clouds via un cable éthernet qui limite le débit en lecture/écriture à 100 MByte/sec (c’est une mauvaise vitesse, similaire à un simple HDD). Cette méthode de connection élimine totalement le grand avantage inhérent aux supports SSD: leur vitesse. En effet, un SSD de type NVMe qui est connecté « normalement » (càd sans passer par un cable éthernet) aura une vitesse de lecture/écriture autour de 3500 MByte/sec (et pas 100 MByte/sec comme sur mazon/Azure&GCP !). Nous vous recommandons le serveur Ax101 de chez Hetzner (un fournisseur cloud allemand, c’est un serveur avec un prix fixe de 111€/mois) car les disques SSD inclus dans ces serveurs ont une une vitesse de lecture/écriture normale comprise entre 1500 et 2500 MByte/sec.
Si vous prévoyez de travailler avec une serveur dans un Cloud Public (notez que dans la plupart des cas, cela vous coûtera beaucoup plus cher que d’acheter un bon PC), n’importe quel laptop fera l’affaire puisque votre laptop ne fera pas de calcul (il sera juste utilisé pour se connecter au serveur cloud). Par contre, essayez tout de même de choisir un serveur cloud qui réponds aux conseils donnés dans cet article : il existe maintenant des solutions de cloud computing qui fournissent d’assez bonnes machines « bare metal » !
Si vous comptez travailler principalement sur des images ou des videos, il vous faudra un GPU solide, et probablement un « serveur cloud optimisé GPU »: Dans cette situation, le calcul distribué prend tout son sens! Google sera probablement votre meilleure option.
De nos jours, la plupart des algorithmes disponibles fonctionnent en « single core », en particulier quand on utilise des solutions open-source comme R ou Python. Il faudra dès lors surtout prioriser la sélection d’un CPU rapide en « single-thread » (ou « mono thread »). Python est déjà particulièrement lent, et si vous lui donnez un CPU avec de faibles performances en single thread, vous allez vraiment vous rendre la vie trop compliquée. Au final, il n’y a que peu de cas dans lesquels la distribution des calculs sur plusieurs machines physique est intéressante, et dans tous les cas la loi d’Amdahl (qui s’applique aux calculs distribués) ne joue pas en votre faveur! Bien que R soit généralement plus rapide que Python (seulement s’il est bien programmé, en favorisant lapply pour faire les boucles), la plupart des opérations ne sont pas non plus multithreadées, et avoir de nombreux cores/threads (axe de Y dans les graphiques suivants) ne sera pas utile. Il est toutefois possible de paralléliser les calculs en multithread avec openR ou le package doParallel, par exemple. …Mais la grande majorité des data scientistes travaillent en « single thread » (en tout cas lors de la phase exploratoire). Une exception cependant: certains algorithmes (comme xgBoost) sont parallélisés et avoir plusieurs coeurs pour cette opération est relativement intéressant!
Si vous utilisez Anatella comme plateforme de data science, vous savez a quel point il est simple de traiter des tables avec des milliards de lignes sur votre PC. Le choix du CPU ne sera par contre pas trivial. Par défaut, un graphe Anatella tourne sur un seul coeur (plus exactement: sur une seule thread). Il est toutefois possible d’optimiser l’exécution d’un graphe pour utiliser plusieurs cœurs (par exemple en ajustant les options des boites loopAnatellaGraphs2 ou loopAnatellaGraphsAdv2) ou en utilisant les fonctionnalités de multi-threading. Mais, dans 99% des cas, Anatella est déjà tellement rapide en single-thread que ce ne sera pas nécessaire. Par contre, quand la volumétrie augmente, ou que la performance maximale est nécessaire, avoir plusieurs cœurs devient intéressant. …Mais sans dépasser les 32 cœurs! …car la loi d’Amdahl nous enseigne que c’est inutile d’aller plus haut! (voir ici pour plus de détails sur la loi d’Amdahl).
Le Siteweb « CpuBenchmark » est très utile pour comparer les CPU et déterminer quel est le meilleur CPU. Malheureusement, la comparaison de différents CPU selon plusieurs critères n’est pas évident avec les outils mis a disposition directement sur le siteweb. Nous allons donc utiliser Anatella pour déterminer quel processeur donnera les meilleures performances avec la Suite TIMi!
Pour bien choisir notre CPU, nous devons considérer deux dimensions: single thread speed (pour la plupart des opérations) et multi-thread speed (parce que quand le volume de données augmente, nous créerons des processus&graphes qui peuvent se lancer en parallèle, et TIMi Modeler utilise plusieurs cœurs). Pour la réalisation de ce script, nous avons téléchargé les informations disponibles sur:
Le script Anatella est disponible ici (les fichiers HTML sont inclus, mais vous pouvez les mettre a jour). Si vous lancez ce graphe, vous obtiendrez un scatter plot, assez basique dans lequel les 175 meilleurs CPU sont visibles:
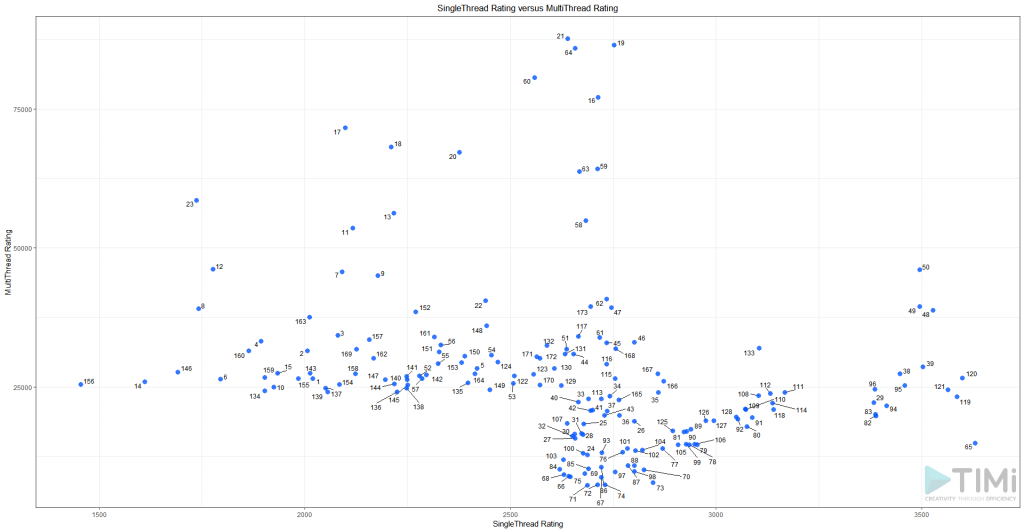
Il est intéressant de constater qu’il semble y avoir un groupe de « CPU haute performance » au delà du score de 3000. Puisque la vitesse en « single thread » est le goulot d’étranglement principal, nous pourrons plus tard zoomer sur ces processeurs (avec un score en single thread supérieur à 3000). Ajoutons quelques options à notre graphique:
Nous voulons mieux visualiser la différence entre AMD et Intel, nous allons donc choisir un série de couleur avec la variable « Make ». Pour avoir une idée relative du prix, nous choisissons la variable « log(Price) » comme taille des points. Nous allons également visualiser le nom des processeurs, maintenant qu’il y en a moins, il n’y a pas de raison de ne voir qu’un index.
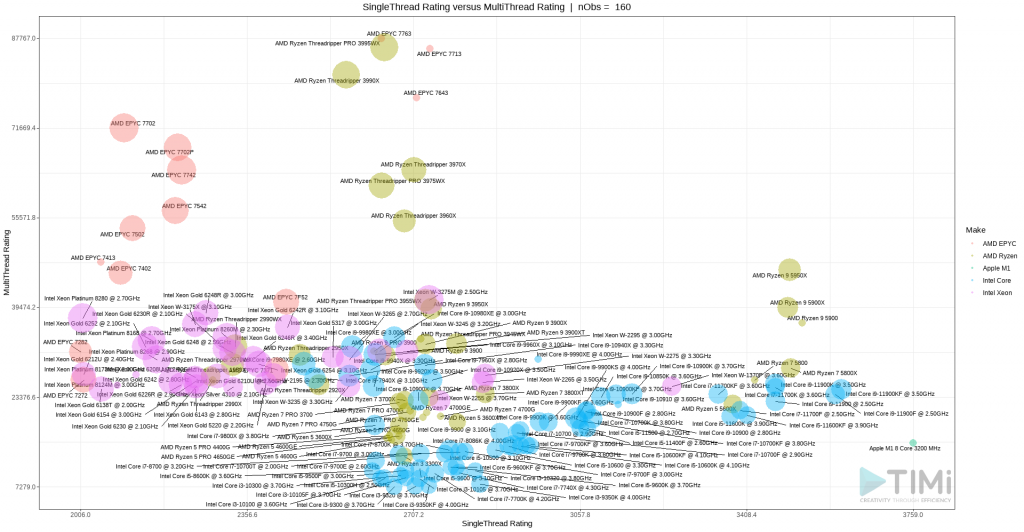
Le graphique reste un peu confus, mais nous permet déjà de voir quelques groupes intéressants. La famille AMD Ryzen Threadrippers offre des produits incroyables en termes de vitesse en multi-thread, ce qui les rend les plus intéressant pour faire des serveurs web (spécialisés pour servir des pages http) mais pas pour réaliser du traitement de données ou de la data science. Regardons de plus près les processeurs avec un score de « plus de 2000 » en single thread:
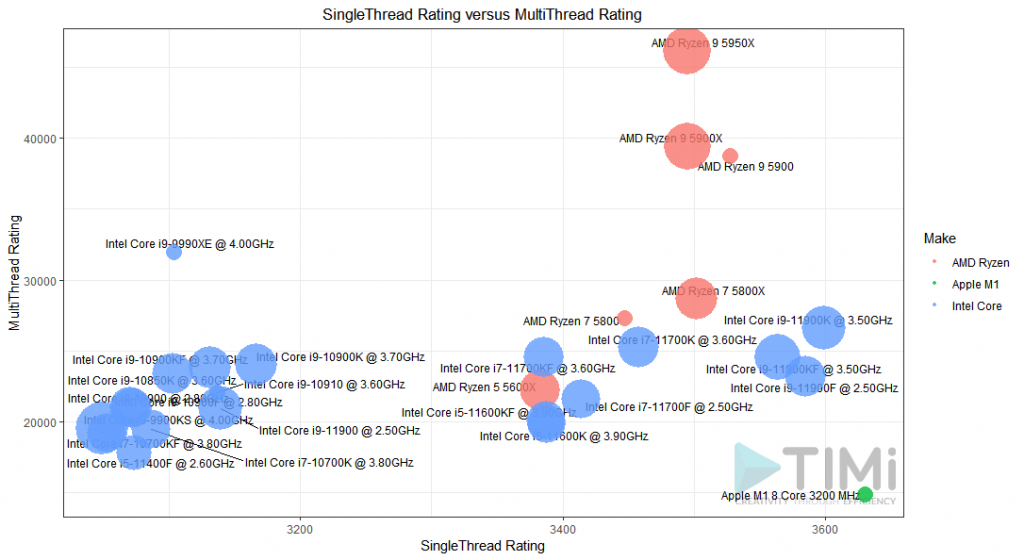
Et nous avons un gagnant!L’AMD Ryzen 9 5900 est clairement le processeur qui nous en donne le plus pour notre argent! Et si les nouveaux Intel i9-11900K, i9-11900KF et i9-11900F sont marginalement meilleurs en terme de vitesse single thread, la valeur ajoutée par la capacité mutli-thread des Ryzen 9 les rend moins attractifs!
Si le budget n’est pas un problème, le meilleur de tous les CPU pour Anatella est le AMD Ryzen 9 5950x ! Il a un des meilleurs scores en performance single thread, et offre aussi une des meilleures performance en multithread grace a ses 32 cœurs. Donc, même pour les opérations demandant du calcul distribué (comme c’est le cas pour les graphes anatella optimisés) vous obtiendrez la meilleure vitesse possible. Je ne pensais pas dire cela un jour mais, oui: vive AMD!
Pour les applications développées en R ou Python, il semble que le MacBook soit votre meilleure option. Mais attention, si vous utilisez les routines d’algèbre linéaire (ou n’importe quelle librairie intéressante, en fait) dans R ou Python, vous devrez utiliser un processeur compatible Intel (donc Intel ou AMD) qui supporte les instruction vectorisées du CPU (SIMD instructions set) pour avoir les meilleures performances. Le M1 n’ayant pas ces caractéristiques, même si il offre une fréquence supérieure, les performances seront inférieures. Si vous restez un pur utilisateur PC ou Windows, alors ces processeurs i9 de Intel sont pour vous.
Note: En août 2021, le meilleur CPU pour faire de la data science (càd le AMD Ryzen 9 5950x ) était disponible uniquement dans les serveurs clouds de chez Hetzner (un fournisseur cloud allemand) au prix fixe de 111€/mois!
Note: Ces résultats se basent sur des données de août 2021. Le marché évolue rapidement, vous pouvez obtenir des résultats différents si vous mettez les données à jour !
Détails techniques:
Ce petit script combine des techniques de web scraping et text mining en Anatella. La première partie du script consiste a charger les données, les url, noms et performance de chaque CPU, pour les meilleurs CPU en single thread et en multi thread. Comme ils sont ordonnés, nous pouvons garder le top 100 de chaque catégorie, retirer les doublons, et continuer l’analyse.

La deuxième étape est de télécharger les URL. Pour cela, nous utilisons l’action MultipleDownAndUpload, qui prend simplement en entrée l’URL à téléchager et le nom du fichier local correspondant:
Finalement, nous allons extraire des pagewebs téléchargées toutes les informations qui nous servent, en utilisant l’action extractRegExpPosition. Nous allons extraire les valeurs associées a un label, lui donner un nom, et organiser l’information dans une grande table afin de créer le graphique. Enfin, nous saucons la table dans un fichier Excel.