La précision des modèles de l’IA vous impressionne?
J’ai récemment regardé une vidéo intéressante de Eric Siegel, dans laquelle il parle de l’erreur de précision (Accuracy Fallacy). C’est un thème dont je parle souvent et que j’ai abordé (bien que pas aussi clairement que lui) dans un autre billet il y a quelques années, lorsque j’ai écrit sur la classification, les courbes ROC et Lift (Gain). Siegel a vraiment bien inventé le terme et m’a motivé à écrire ce petit billet, et c’est un terme que j’utiliserai fréquemment à partir de maintenant.
Dans la communauté de la science des données, nous avons une mauvaise tendance à exagérer la qualité de nos modèles, souvent de manière inconsciente. Nous sommes tout simplement formés à utiliser les mauvais indicateurs de performance, et la population générale les comprend encore moins bien que nous.
Lorsque j’ai appris les techniques de classification à la fin des années 90/début 2000, le KPI que nous utilisions tous était la table de classification, exprimée en pourcentage, et cela ne semblait poser de problème à personne.
Puis, le ROC a pris le relais, ce qui est déjà une énorme amélioration, car il exprime la composante dynamique d’une table de classification. La classification suppose un seuil constant en termes de probabilité, souvent 50% ou un point « optimal » fixé pour maximiser le taux de réussite, ou la précision. Lorsque ce point bouge, la courbe ROC se forme.
Mais cela donne une confiance très trompeuse.
Prenons l’exemple simple d’un très bon modèle prédictif.
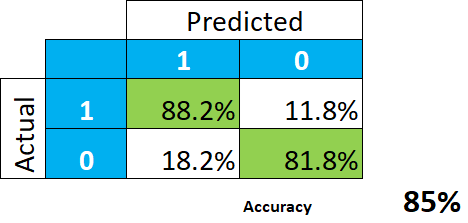
Ceci semble en effet génial. La conclusion est que le modèle nous donne 85% de taux de réussite (la moyenne entre 88,2 et 81,8), ou de précision, et que nous ne devrions pas nous attendre à tout un tas d’erreurs de classification.
Mais est-ce correct?
Souvent, la réalité est vraiment déséquilibrée, et la probabilité apriori est de 1 ou 2%. Prenons un exemple, disons la probabilité de déclarer un revenu élevé, qui elle est d’environ 6%. La courbe ROC aurait bien sûr l’air aussi bonne que – ou même meilleure que – le tableau de classification :
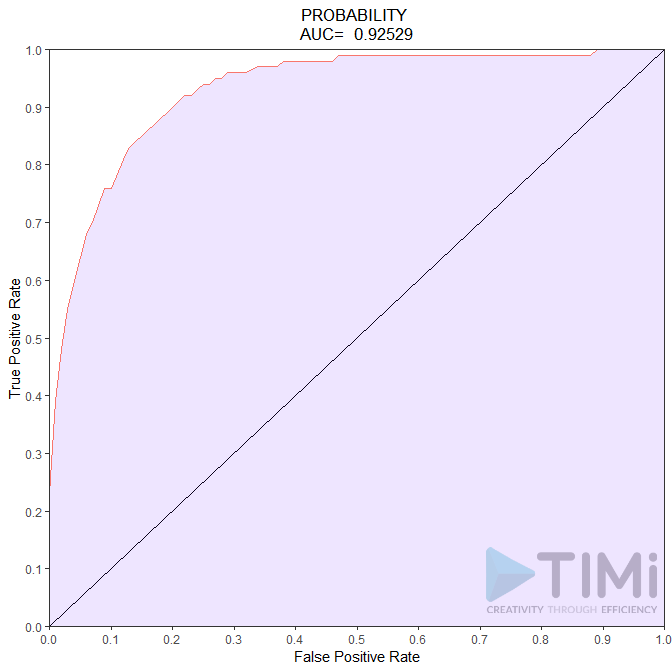
Alors, que concluons-nous maintenant ? Nous avons un modèle incroyable, avec une qualité de 85 à 92,5 % ! Rien ne peut aller mal, et ce qu’un non spécialiste des données comprendra, c’est que tous les contribuables seront identifiés, avec peut-être 7,5 à 15% d’erreur. Ce n’est pas le cas, et cette mauvaise (effrayante !) interprétation est de notre faute.
Regardons comment les données sont réellement classées, en chiffres absolus. Et au lieu de nous concentrer sur le nombre de vrais et faux positifs et négatifs en pourcentage, regardons ce que le modèle nous dit être un positif :
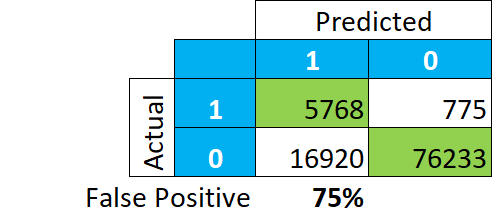
Cela donne une image complètement différente. Parmi notre classification des « VRAIS », 75% des enregistrements sont en fait des « FAUX » (16,920/(5,768+16,920)). Cela signifie que si nous examinons les payeurs de taxes dans ce groupe, nous ne trouverons pas 85-92% de payeurs réels, mais seulement 25%.
La courbe de GAIN nous aide a mieux comprendre ce phénomène.
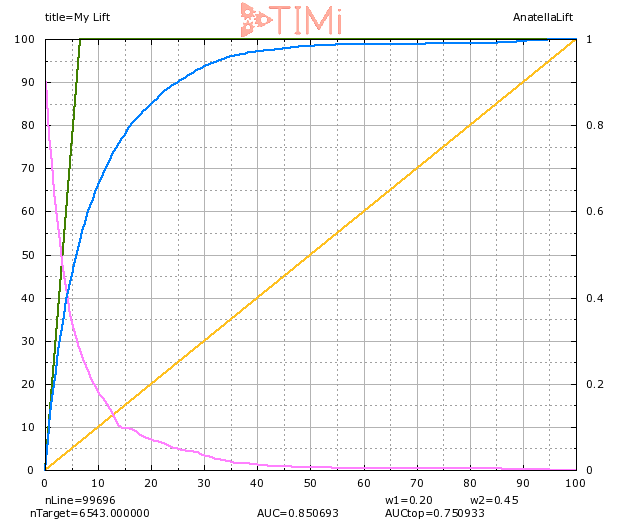
Lorsque nous sélectionnons 20% de la population (sur l’axe des X), nous constatons effectivement que 85% des cibles sont identifiées. Mais nous voyons aussi que nous avons sélectionné un échantillon environ 3 fois plus grand que notre groupe apriori (visible sur la ligne verte : 6% sur l’axe X), donc nous pouvons nous attendre à ce que BEAUCOUP d’enregistrements dans ce groupe soient en fait négatifs. A 20% de la population sélectionnée, la probabilité d’être vrai pour l’enregistrement le moins probable est d’environ 6-7% (voir la courbe bleu clair).
Soyons un peu réalistes: nous ne classons pas vraiment les choses. Et si nous le faisons, admettons que nous sommes nuls à ce jeu. Ce que nous pouvons faire correctement – comme indiqué ici – s’appelle la priorisation. Les modèles de priorisation sont un outil incroyable pour hiérarchiser et trier les données, ils aident à prendre des décisions qui génèrent des millions d’euros dans de nombreuses industries. Mais nous sommes loin du point où un algorithme pourra nous dire avec une faible marge d’erreur qui est un mauvais payeur, qui est un futur mauvais étudiant, un futur mauvais employé, ou qui est sur le point de commettre un délit. Il nous guidera dans la bonne direction, mais à moins que la probabilité réelle d’un événement pour une observation soit >0,99, il est dangereux, et irresponsable, de dire que nous l’avons « classé ».
Arrêtez d’avoir peur de la vérité : C’est un excellent modèle, si vous prenez les 2% les plus élevés de la population, vous aurez 70% de positifs réels (au lieu de 6% !), le « lift » est de 6,5 à 10% de la popuation. Nous n’avons pas besoin de générer de fausses attentes et de parler de ces taux de 85% et plus.