![]()
There are three ways to start the .TypeXML file Editor:
1. Create a new .TypeXML file using TIMi and open it directly after creation (this is normally what you just did)
2. Click the ![]() button inside the main menu of TIMi.
button inside the main menu of TIMi.
3. Double-click on a “*.TypeXML” file inside a “file explorer” window.
Using the Type Var Editor you can specify the type of each column of the dataset. There are basically five types of columns:
a.Value type. Examples are: Age, Size, Cost, Price,…
This type of column can only contain numbers and exhibits an ordering property. For example, a six-year old boy is younger than a twelve-year old boy and a twelve-year old boy is younger than an eighteen-year old boy. There is an order. So a column containing the age of a person should be of type “value”. On the contrary, a column containing the zip code of the house of a person should be of type “nominal” because the zip code 1050 is NOT smaller or bigger than the zip code 1210. There is no order inside the zip code.
b.Binary type. Examples are: isMale, isForeigner,…
This type of column can only contain a “true/false”, “yes/no” semantic. These columns contain only two modalities (T/F) or three modalities (T/F/missing).
c.Nominal type. Examples are CarLabel, Region,…
This type of column contains anything that is not “value type” or “binary type”.
d.Target type. What is the “target column”?
This is type of column is only useful with doing “predictive” analysis. Since we are performing a “Segmentation” analysis, we won’t have any column of this type.
e.Key type. What is the “primary key column”?
![]()
We will to set to the “nominal” type all the columns that contain “code”:
1. Enter “*code*” inside the Filter 1.
2. Click the![]() button and then the
button and then the ![]() button.
button.
See illustration below:
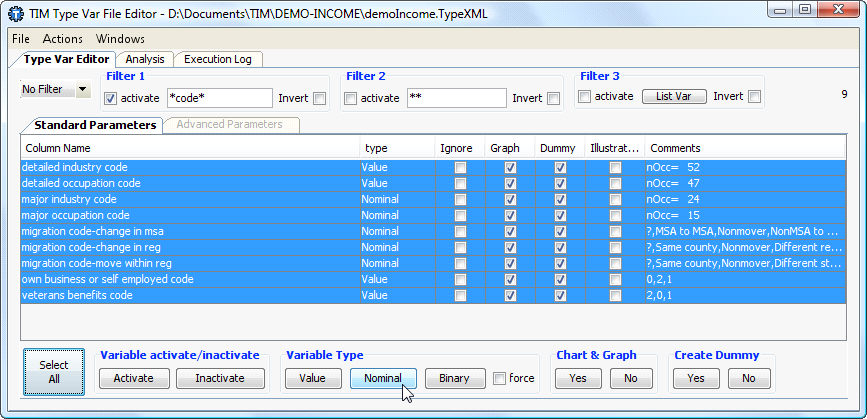
This manipulation HAS BEEN performed in the rest of this document.
You must define the column that contains the primary key. In our example the primary key is the column “Key”. See illustration:
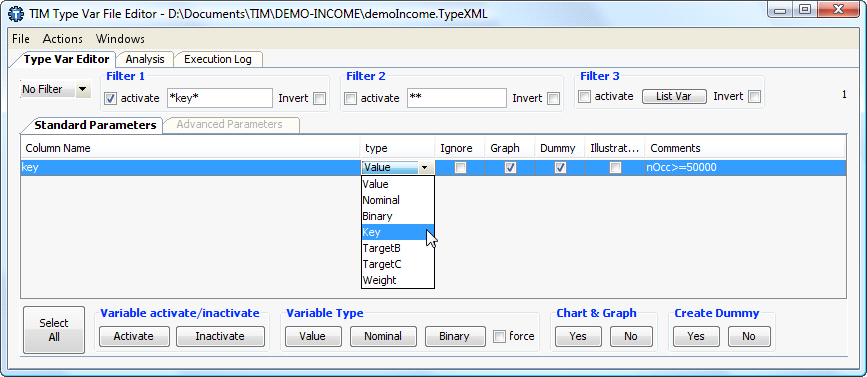
We do NOT have to define the column containing the target. For a segmentation analysis, there is no target.
The other parameters available inside the .TypeXML File editor are not important at this time. You can leave them at their default value.
Click on the “Analysis” tab and then on the ![]() button. When the univariate analysis is complete, you obtain a “.DescXML file”. You can use this new “.DescXML file” to start a new segmentation analysis: Click the
button. When the univariate analysis is complete, you obtain a “.DescXML file”. You can use this new “.DescXML file” to start a new segmentation analysis: Click the ![]() button:
button:
The main window of StarDust appears:
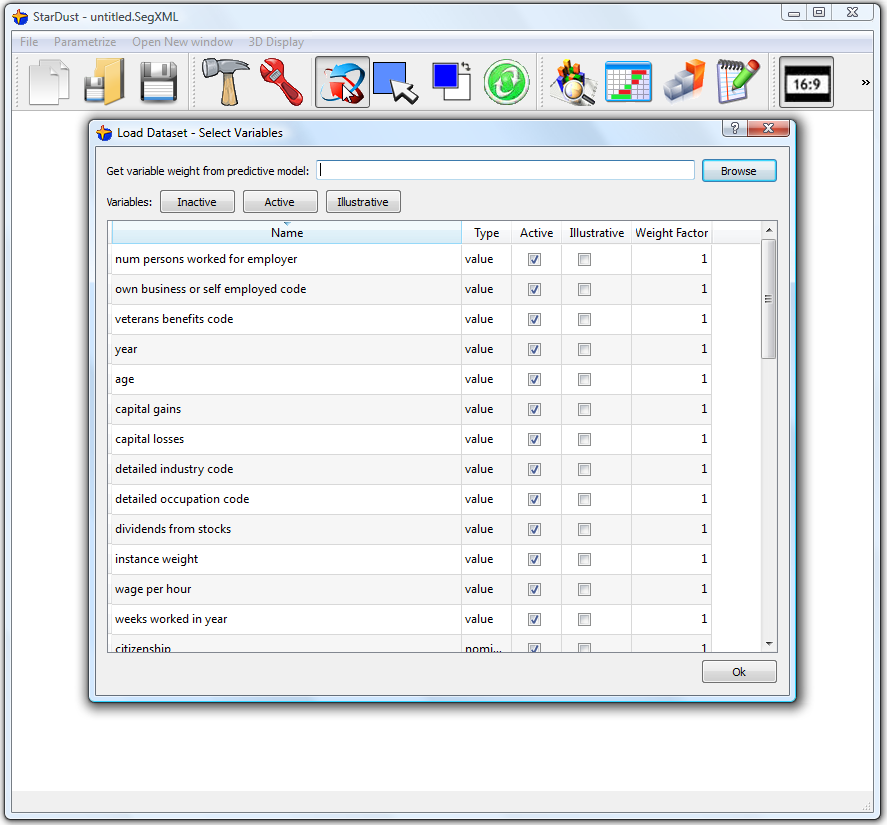
This first screen allows you to:
1.Select the columns that will be loaded into memory for analysis. Usually, you load everything. For very large database of several tens of gigabytes, you could “skip” some columns to gain time and memory.
2.Select the weight given to each column. This weight can automatically be extracted from a predictive model. This feature is very important when performing a segmentation analysis AFTER a predictive analysis. See the next section (section 4.3) for more information at this subject.
All the ACTIVE and ILLUSTRATIVE variables will be loaded into memory. The active variables will be used to create the segmentation. In opposition, the ILLUSTRATIVE variables won’t be use to create the segmentation but rather to explain it from a business-point of view.
You can directly click the ![]() button to start the segmentation analysis: the whole dataset is loaded into memory. Be patient: it can take some time, especially if the dataset is very large.
button to start the segmentation analysis: the whole dataset is loaded into memory. Be patient: it can take some time, especially if the dataset is very large.