We will start from the basic “zooming” example given in section 5.3.2.1.
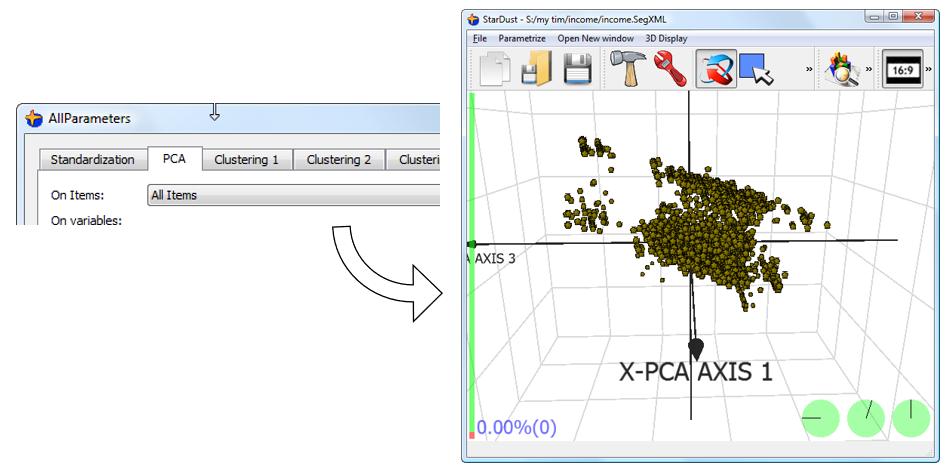
We will change the individuals on which the PCA is computed, in order to obtain a new PCA that is especially tailored to display the individual inside the “segment1” group with the less distortion possible (distortion arrives from the dimensionality reduction). We obtain:
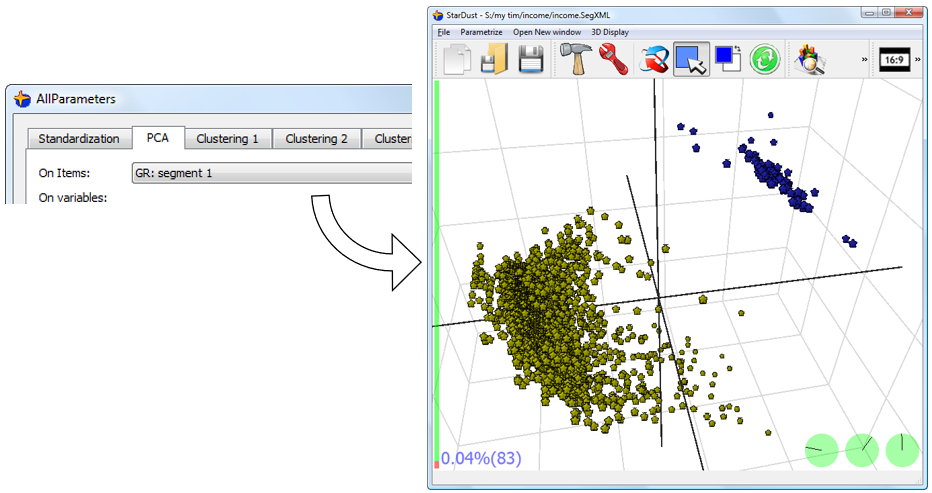
We can see that the “segment1” group contains in reality 2 sub-segments. These sub-segments were not visible when the PCA was computed on the whole database.
Using the PCA in this way, we can really “zoom-in” in some specific part of the space and easily explore our database in a real multivariate way to discover new “insights” about our customers.
In opposition to simple OLAP softwares that are showing your database “variables per variables” (or “columns per columns”) in a UNIvariate (or, some time, BIvariate) way, with StarDust, we can do “MULTIvariate exploration” because all the original axises of the database are represented at the same time on the 3D graph. You can even “see” where are “placed” the original axises using techniques described in section 3.2.5 and 5.3.2.4.
The real-time and powerful “MULTIvariate exploration” of your database with StarDust is a unique functionality amongst all currently available datamining tools.
![]()
Note that you must be careful when using the PCA to “zoom-in” inside your data because the same PCA is also used to create the segmentation.
This means that, if the PCA is currently used to “zoom-in” on the “Segment1” group (like here above), then all the newly created segmentation will emphasize the segments that are contained inside the “Segment1” group. This is not what you want.
However, it is very common (and strongly recommended) to change the default group (that is “All Items”) on which the PCA is built to remove from the PCA analysis the “outliers”: see previous section 5.4.1 at this subject.