To remind you: The first PCA axises are defining priviliged directions that are the best directions on which to « project » our “cloud of points” in order to « loose » as little information as possible.
The PCA algorithm has one major drawback that we can use to our advantage: it’s “sensitive to outliers”. What does it means? It means that if the “cloud of points” on which the PCA is based contains some outliers, then the PCA algorithm fails and gives as output as set of direction that shows you the outliers. For example: Let’s go back to the example of section 2.1.1 and add 3 more “outlier points” inside the dataset used to construct the PCA:
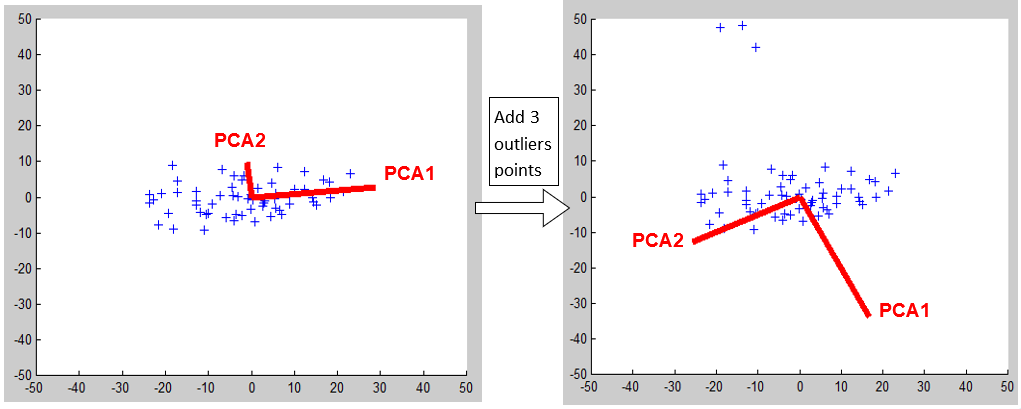
You can see that, when our dataset contains some outliers, the projection on the PCA1 axis will emphasize these outliers and completely “clutter” the main “cloud of points” that is really our interest. In such situation, we can:
1.Investigate the outliers:
a.what’s the profile of the outliers? You can use the charts described in sections 5.2.10, 5.2.11 and 5.2.12.
b.What are the primary keys of these outliers? Please refer to section 5.3.2.3.
2.Create a new PCA on a “reduced” dataset that does not contain anymore the outliers: To do that:
a.select with your mouse the “non-outlier” points (see section 5.2.7 to know how mouse selection works)
b.create a new group based on your selection, using the ![]() button (see section 5.3.1.1 to create a group).
button (see section 5.3.1.1 to create a group).
c.Select this new group as the dataset to analyse to create the PCA: click here:
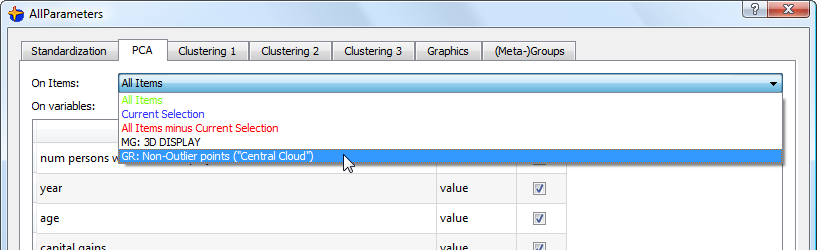
It’s important to remove the outliers from the PCA computation before computing any segmentation, otherwise the segmentation will only give, as a result, some segments that emphasize the fact that an individual is an outlier or not.