The proper usage of this function requires a little bit more explanations. There are basically two “use cases” when you need to use the “rowDeepCopy()” function:
9.2.1.5.1. Use Case 1
Let’s go back to our example of section 9.2.1.2:
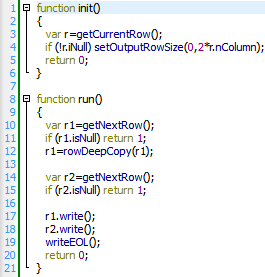
On line 12 of the above script, we used the global function “rowDeepCopy()”.
Let’s first examine what’s happening if the line 12 is missing:
Inside the above script, on line 10, we extract a new row from the table on input pin 0. This row is placed into the JavaScript “r1” variable. Inside Anatella, all row manipulations are highly optimized and what’s really placed inside the “r1” variable are actually only references to a memory buffer that contains all the real row data. When you call, on line 14, the “getNextRow()” function, you will re-use the same memory buffer to store the content of the new row designed by “r2”. The For performance reasons, the variables “r1” and “r2” are sharing the same memory buffer to store their content. The variable “r1” now contains some references to a memory buffer that has been altered. You cannot use anymore the variable “r1”. Any attempt to use variable “r1” will produce unforeseen results. The solution, of course, is in the usage of the “rowDeepCopy()” function.
The line 12 is present: Everything is ok:
The instruction “r1=rowDeepCopy(r1)” will create a completely new fresh copy of the row “r1” into a newly allocated memory buffer. In software terms, Anatella performs a “deep copy” of the “r1” row object (and places the copy into “r1” again). The variable “r1” is now sharing its memory buffer with NO other variable. In this situation, the call to the “getNextRow()” function, on line 16 is totally harmless.
To summarize: There exists one memory buffer per input pin. This memory buffer is shared by all the “Row objects” obtained using previous calls to the “getNextRow()” or “getCurrentRow()” functions. When you call the “getNextRow(pinP)” function, all the “Row objects” obtained using the “getNextRow(pinP)” or “getCurrentRow(pinP)” functions are invalidated: you cannot use them anymore. If you want to still be able to use an old Row object “R” after a call to the “getNextRow(pinP)” function, you must perform a deep copy of your Row object “R” (using the “rowDeepCopy()” function).
![]()
We just wrote in the previous paragraph “There exists one memory buffer per input pin”. This is not a precise description of the real Anatella implementation but this description is accurate enough to be able to give the required explanation regarding the correct usage of the “rowDeepCopy()” function.
Actually, The Anatella C++ code has been optimized to avoid:
1. the creation of many un-necessary memory buffers.
2. large un-necessary memory copy.
We made an extensive usage of the C++ pointers arithmetics to achieve the highest performances.
![]()
Coding for speed.
You should try to avoid calls to the “rowDeepCopy()” function because these calls are CPU intensive: At each call, Anatella will duplicate all the row content and, for very long rows, this means that Anatella might be forced to copy several megabytes of RAM. This might slow down significantly your transformation script.
9.2.1.5.2. Use Case 2
As you already know, inside JavaScript, “Rows” are objects and objects are always access by reference. This means that the following script won’t do what you expect it to do:
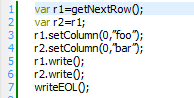
Since the “r1” and “r2” variables are manipulating the same Row Object, the instruction on line 3 will never have any effect at all because its effect is overridden by the instruction on line 4. To obtain a completely separated copy of a “Row object”, use the “rowDeepCopy(rowObject)” global function. Here is the same example with the appropriate correction:
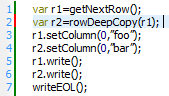
Here is an even better correction:
