An Hadoop HDFS drive is much slower (typically between 5MB/sec and 50 MB/sec) than a (comparatively much cheaper) SSD/RAID6 drive (that runs between 500MB/sec and 2000MB/sec), so don’t expect a very high processing speed from an analytical system based on Hadoop HDFS: You will need to add many computers (i.e. “nodes” in Hadoop terminology) to get a processing speed that is barely tolerable. You’ll find more details on this subject here: https://timi.eu/blog/cloud/
One good thing to keep in mind when using Hadoop HDFS and Anatella together is the following: The slow I/O speed of HDFS is (usually) not really a problem when you manipulate your data using Anatella because, when running an Anatella-Data-Transformation-Graph, the I/O speed is usually not the “bottleneck” (i.e. when using Anatella, the only bottleneck is usually the CPU).
![]()
Within Anatella, the only bottleneck is usually the CPU. How is that so?
The Anatella engine has two important properties that make it mostly insensible to I/O speed:
1. The Anatella engine works “in streaming” (meaning that it processes data row-by-row: see sections 5.3.2.1. to 5.3.2.5 for more details about this subject).
2. Reading (and writing) a data file inside Anatella is done using an asynchronous algorithm (see section 5.2.6.2. for more details about this subject)
This meaning that, most of the time, Anatella is able to simultaneously “read the required data file” and “process the data”. In this example:

… we simultaneously:
* read the data
* compute the join and the aggregate.
Let’s now assume the following: In the above example:
* the I/O read speed is around 100MB/sec
* the computation speed (to compute the join and the aggregate) is around 50 MB/sec.
Looking at the above assumptions, we can see that the “bottleneck”, when runnng this Anatella graph, is not the I/O speed: It’s the computing/CPU speed (as it is nearly always the case with Anatella): i.e. The global speed of the whole Anatella graph is limited to 50 MB/sec because of the limited computational speed of the join and the aggregate.
In practice, one quickly realizes that the I/O speed is practically NEVER the "bottleneck element" that decides of the overall execution time of an Anatella-data-transformation-graph.
This “insensibility to the I/O speed” is also due to the nature of the usual tasks that are performed using Anatella. Since Anatella is built for analytics and predictive analytics tasks in mind, a typical “workload” requires complex, CPU-intensive computations (to create refined KPI’s or to do “feature engineering”). These CPU-intensive operations usually represent 95% of the computation time (i.e. inside Anatella, the CPU is usually the bottleneck). So, if we can read the data faster, we will (maybe!) just gain a few percent out of the 5% of the time that Anatella devotes to reading the data.
On the other hand, it's true that, for a very simple "Anatella-data-transformation-graphs" (e.g. for example, a graph that contains only one simple aggregate to compute), it's worth reading the data faster.
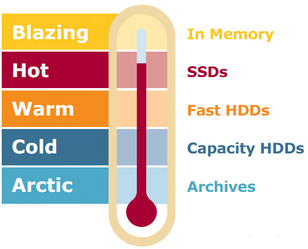
To alleviate the slow speed of HDFS, we can also choose how the data is stored using a methodology based on “data temperature”. We use the term “temperature” as a metaphor for “frequency of access”:
•Seldom-used data is “cold data” that should be kept on low-cost, high-capacity disk storage, such as HDFS.
Cold data may not be the most popular, but it is used daily to support vital strategic analytics and decision-making. The cold data is often last year’s financials, government risk and compliance data, or consumer behaviours that is used by the marketing department for loyalty or churn analysis.
•High-use data is “hot data” and it should be placed on high-performance SSD, SAN/NAS or RAID6 drives.
Hot data typically includes all recently collected data tables. It also includes all the “heavy used” datasets that are automatically prepared every night and used during the day by the data scientists to complete their daily tasks.