The data inside a “.gel_anatella” file is compressed using block-based compression algorithm.
This means that the algorithm used to read a “.gel_anatella” file is the following:
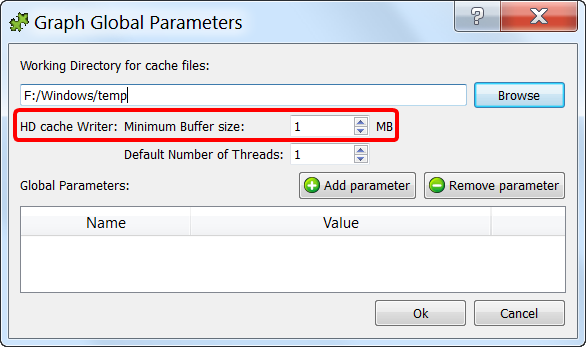
1.Extract/Read one data-block out of the hard drive. The data-block size is defined when you create the “.gel_anatella” file, using the ![]() GelWriter Action. You can select the data-block size at the moment of creating the “.gel_anatella” file (i.e. When you read the file, it’s too late: i.e. You don’t have any control on the data-block size anymore) using the “Graph Global Parameters” Windows: It’s the “Minimum Buffer Size” option, here:
GelWriter Action. You can select the data-block size at the moment of creating the “.gel_anatella” file (i.e. When you read the file, it’s too late: i.e. You don’t have any control on the data-block size anymore) using the “Graph Global Parameters” Windows: It’s the “Minimum Buffer Size” option, here:
It can happen that you are forced to open a large number of “.gel_anatella” files simultaneously (for example, when using the ![]() mergeSortInput Action: see section 5.2.15.). Keep in mind that each opened “.gel_anatella” file uses (by default) around 1 MB of RAM (…and it uses even more RAM if you set the “Read Buffer” parameter greater than one). Thus, to open one thousand “.gel_anatella” files simultaneously, you need at least 1GB of RAM: This is already a lot of RAM on a small 32-bit server and might lead to some crashes.
mergeSortInput Action: see section 5.2.15.). Keep in mind that each opened “.gel_anatella” file uses (by default) around 1 MB of RAM (…and it uses even more RAM if you set the “Read Buffer” parameter greater than one). Thus, to open one thousand “.gel_anatella” files simultaneously, you need at least 1GB of RAM: This is already a lot of RAM on a small 32-bit server and might lead to some crashes.
Using a larger block size than 1MB means that the compression is (very slightly) better and the reading&writing speed is also slightly better (faster).
2.Validate that the data-block is not corrupted: Anatella compute a checksum on each data-block.
3.Decompress the data-block to get some “data rows” and send these rows to the connected Actions as output.
4.Wait for the Actions connected to the ouput of the ![]() GelFileReader Action to use/consume all the rows from the current data-block. Once all the rows from the “current block” are used, go back to step 1.
GelFileReader Action to use/consume all the rows from the current data-block. Once all the rows from the “current block” are used, go back to step 1.
In terms of speed, the above algorithm used to read the “.gel_anatella” file is not very efficient because, it’s a “synchronous (i.e. blocking)” I/O algorithm: i.e. When the Actions connected to the ouput of the ![]() GelFileReader Actions are requesting some more rows (i.e. when they just consumed all the current rows from the current data block), the data-transformation:
GelFileReader Actions are requesting some more rows (i.e. when they just consumed all the current rows from the current data block), the data-transformation:
•Blocks until the extraction of the next data-block out the Hard Drive is completed.
•Blocks until the validation of the next data-block is completed.
•Blocks until the decompression of the next data-block is completed.
…and then (and only then) the data-transformation unblocks and you receive the next rows.
It would be nice to have a better algorithm that is an asynchronous (i.e. non-bloking) I/O algorithm: When you set the value “2” for the “Read Buffer” parameter from the ![]() GelFileReader Action, Anatella will use an asynchronous (i.e. non-bloking) I/O algorithm to read the “.gel_anatella” file (this implies using several threads in parallel). This means that all the extraction/validation/decompression tasks will be performed continuously “as a background thread” so that, when the Actions connected to the ouput of the
GelFileReader Action, Anatella will use an asynchronous (i.e. non-bloking) I/O algorithm to read the “.gel_anatella” file (this implies using several threads in parallel). This means that all the extraction/validation/decompression tasks will be performed continuously “as a background thread” so that, when the Actions connected to the ouput of the ![]() GelFileReader Actions are requesting some more rows (e.g. from the next data-block), these rows are always directly available in RAM, ready to be used (i.e. and the data-transformation-process does not have to stupidly wait for the extraction/validation/decompression tasks to be finished). The “background thread” continuously produces new rows (so that they are always directly available when requested). These rows are stored inside one of the (many) “Read Buffers”. The quantity of “Read Buffers” is set here:
GelFileReader Actions are requesting some more rows (e.g. from the next data-block), these rows are always directly available in RAM, ready to be used (i.e. and the data-transformation-process does not have to stupidly wait for the extraction/validation/decompression tasks to be finished). The “background thread” continuously produces new rows (so that they are always directly available when requested). These rows are stored inside one of the (many) “Read Buffers”. The quantity of “Read Buffers” is set here:
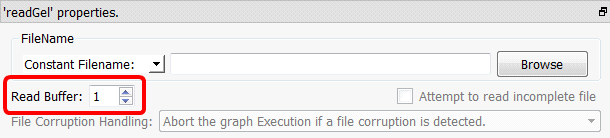
When the parameter “Read Buffer” is:
•“1”:
oAnatella uses a synchronous (i.e. bloking) I/O algorithm.
oThis is the best option if you want to reduce to the minimum the RAM consumption (at the cost of speed). By default, the ![]() GelFileReader Action uses 1MB of RAM.
GelFileReader Action uses 1MB of RAM.
•“2”:
oAnatella use an asynchronous (i.e. non-bloking) I/O algorithm.
oLectures from the Hard Drive are faster but RAM comsumption is two times higher. With the default settings, the ![]() GelFileReader Action now uses 2MB of RAM.
GelFileReader Action now uses 2MB of RAM.
oThis is usually the best option when your “.gel_anatella files” are stored on a local hard drive, with constant guaranteed access speed.
•“3 and higher”:
oAnatella use an asynchronous (i.e. non-bloking) I/O algorithm.
oLectures from the Hard Drive are faster but RAM comsumption is higher (by default, the RAM consumption is 1MB multiplied by the quantity of “Read Buffers”).
oThis is the best option when your “.gel_anatella files” are stored on a distant hard drive on a remote server with an unconstant, varying computer network speed (e.g. when the Anatella server is connected to a common-grade 100Mbit/sec or 1Gbit/sec computer network).
A large value for the quantity of “Read Buffers” allows to cope with a sudden&brief “speed drop” of your network drive. Let’s assume that your remote drive stops working for a very brief moment of time (e.g. there are some “network drops”). During this second, the Actions connected to the ouput of the ![]() GelFileReader Action won’t stop working because they will use the rows that have been pre-loaded into the N “Read Buffers” (with N, a very large number). As soon as the network drive works again, the “background thread” directly fills-in the N “Read Buffers” to the maximum, so that, when the next “drive-speed-drop” occurs, the data-transformation-computations can still continue without interruption. A large N value means that Anatella can compute its data-transformation at full speed, even on a very poor, unstable computer network.
GelFileReader Action won’t stop working because they will use the rows that have been pre-loaded into the N “Read Buffers” (with N, a very large number). As soon as the network drive works again, the “background thread” directly fills-in the N “Read Buffers” to the maximum, so that, when the next “drive-speed-drop” occurs, the data-transformation-computations can still continue without interruption. A large N value means that Anatella can compute its data-transformation at full speed, even on a very poor, unstable computer network.