Icon: ![]()
Function: OracleOCI
Property window:
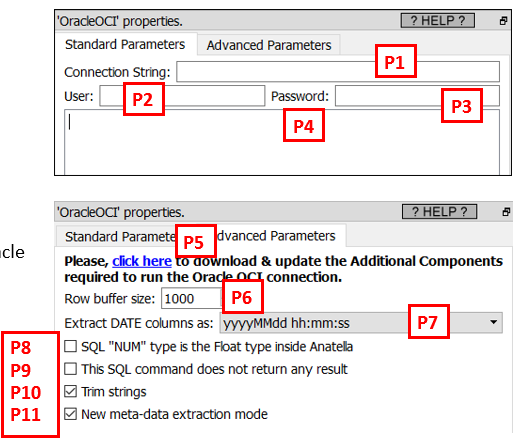
Short description:
Extract data from Oracle.
Long Description:
This action runs some SQL command to extract data from Oracle (i.e. it also runs any free-text SQL command inside Oracle).
![]()
The ODBC drivers from Oracle have strong limitations and we strongly suggest you to use the ![]() OracleOCI Action and the
OracleOCI Action and the ![]() upsertOCI Action in lieu and place of the equivalent ODBC actions.
upsertOCI Action in lieu and place of the equivalent ODBC actions.
Here are some of the reasons why you might be interested in using this ![]() OracleOCI Action rather than the standard ReadODBC action (from the sections 5.1.6, 5.1.6.4 and 5.2.2) to extract data from Oracle:
OracleOCI Action rather than the standard ReadODBC action (from the sections 5.1.6, 5.1.6.4 and 5.2.2) to extract data from Oracle:
1. If you want to insert data at high-speed inside Oracle you must use the ![]() upsertOCI Action. But, as soon as you start using the
upsertOCI Action. But, as soon as you start using the ![]() upsertOCI Action, all ODBC connections to Oracle fail. There are no other choices anymore than using the
upsertOCI Action, all ODBC connections to Oracle fail. There are no other choices anymore than using the ![]() OracleOCI Action to access Oracle (i.e. you cannot mix inside the same graph OCI-based actions and ODBC-based actions).
OracleOCI Action to access Oracle (i.e. you cannot mix inside the same graph OCI-based actions and ODBC-based actions).
2. If you want a better control on the connection “timeouts”: For very large extractions (i.e. an extraction of several TB), you’ll quickly notice that the ReadODBC action generates a large quantity of “timeout” errors. In opposition, the Oracle OCI Action is a lot more stable and reliable. This action actually uses the same exact same libraires (i.e. the OCI libraries) that are also used inside the “SQLPlus” tool to connect to Oracle (this tool is recognized to be the most stable and most efficient way to interact with Oracle).
3. The easiest way to connect Anatella to Oracle under Linux (inside Wine) is through this Oracle OCI Action (i.e. the setup of the ODBC connection for Oracle inside Wine is *much* more difficult).
You can use the “>” character at the start of the SQL field (parameter P4) to create dynamically the SQL command to execute (using Javascript and some Global Parameters). You’ll find more details on “Graph Global Parameters” in the section 5.1.5.
Before using this action, you first need to download the additional Oracle OCI components (it’s a 196MB download): i.e. Click the blue URL (parameter P5) to automatically download and install the Oracle OCI components.
The parameter P1 (named "Connection String") can be a reference to the file "TNSNAMES.ORA", or it can be directly the contents of the file "TNSNAMES.ORA". For example, a "Connection String" such as this one is perfectly valid:

The parameter P6 represents the number of rows that are extracted "in one block" out of the database. A higher value is better because it extracts larger "blocks of rows" and thus minimizes round trips of network data transfers (and thus the data extraction runs faster). Do not put a value too high neither, otherwise the Oracle drivers may crash (and it also consumes a little more RAM).
![]()
f you get an error while executing the ![]() OracleOCI Action that looks like that:
OracleOCI Action that looks like that:
OCI FAILED: Cannot execute the SQL code(1): ORA-24333: zero iteration count
…this means that your SQL command is special: i.e. It’s not a “SELECT” (that returns some rows from the database) but something else (that does not return anything). To fix the error, just check the checkbox P9.
![]()
If you get an error while executing the ![]() OracleOCI Action that looks like that:
OracleOCI Action that looks like that:
FAILED: OCIEnvCreate()
OCI FAILED: Cannot execute the SQL code(1): □ □
…this means that you used the ![]() readODBC action or the
readODBC action or the ![]() upsertODBC action to access Oracle. As soon as you use an ODBC-based connection to access data inside Oracle, all OCI-based connections stop working (and the other way around is also true). You cannot mix the two types of Oracle connections (ODBC and OCI) inside the same graph.
upsertODBC action to access Oracle. As soon as you use an ODBC-based connection to access data inside Oracle, all OCI-based connections stop working (and the other way around is also true). You cannot mix the two types of Oracle connections (ODBC and OCI) inside the same graph.
The solution is: To regain access to Oracle, close the Anatella windows (click the ![]() button in the top-right corner) and re-open Anatella. Once Anatella is re-open you can re-start using OCI again.
button in the top-right corner) and re-open Anatella. Once Anatella is re-open you can re-start using OCI again.
Regarding the parameter P8:
Almost always, the columns of the “NUM” types can be extracted and stored inside a “blue” column of the type “FLOAT” inside Anatella (see the section 5.1.2. about data types inside Anatella). Using a “blue/FLOAT” column inside Anatella is more efficient in terms of storage space on the SSD and in terms of running-time.
BUT, there exists a situation where a “NUM” column contains some numbers with a very high count of digits: i.e. there are some number with more than 14 digits inside the “NUM” column. Such “wide” columns cannot be store insided the type “FLOAT” inside Anatella (that is limited to 15 digits maximum). So, to be on the safe-side, the parameter P8 is left, by default, unchecked, so that the “NUM” columns are extracted as simple texts that is unlimited in terms of number of digits (rather than extracted as the type “FLOAT” inside Anatella). For efficiency reasons, it might be worth considering checking the parameter P8 (but, then, you should be sure to have numbers with less than 14 digits inside the “NUM” columns).
Regarding the parameter P7 and the way Oracle handles Dates
A time-related column inside a table can contain:
•Some Time (hours+minutes+seconds)
•Some Date (year+month+dayOfMonth)
•Some Time Stamp (year+month+dayOfMonth + hours+minutes+seconds)
Inside Oracle SQL, when you create a new table, you can define a time-related column …
•..as the SQL type “DATE” or
•..as the SQL type “TIMESTAMP”.
It seems logical to assume that the SQL “DATE”-type columns are containing some actual Date (i.e. they contain: year+month+dayOfMonth data), but Oracle does NOT actually enforce anything: i.e. inside a SQL “DATE”-type column, you can find any kind of content: you’ll find “Time”, “Date” and “Time Stamp” informations. So, to be sure to extract all the information contained inside a “DATE”-type column, the parameter P7 is set, by default, to “yyyyMMdd hh:mm:ss”.
BUT, if you were consistant when declaring your column’s SQL types when you created your tables inside Oracle, and you made sure to declare a column with the SQL “DATE” type when it actually really contains some actual Dates, then you can set the parameter P7 to “yyyyMMdd” to have a better, more compact data extraction.