Icon: ![]()
Function: SAPReader
Property window:
Short description:
Left-Join several tables into one gigantic table.
Long description:
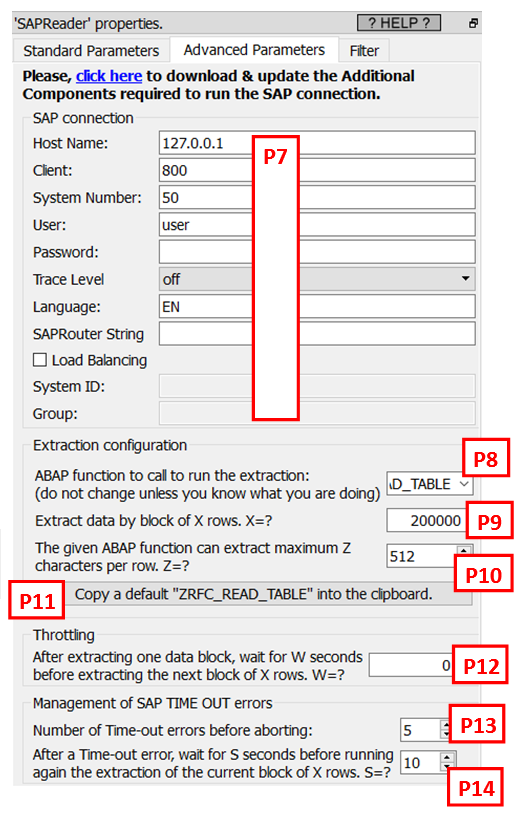
The SAP table extraction is performed using the newest NetWeaver RFC libraries. By default, to run the extraction, Anatella calls the ABAB function named “BBP_RFC_READ_TABLE”, but you can change that using the parameter P8 (see here above).
Instead of running “BBP_RFC_READ_TABLE”, you can run any alternative ABAP function with the same signature. All the ABAP functions with the following signature are compatible with Anatella:
These are all the standard ABAP functions that are compatible with Anatella:
BBP_RFC_READ_TABLE
RFC_READ_TABLE
/SAPDS/RFC_READ_TABLE (which is still different from “RFC_READ_TABLE”)
Z_AW_RFC_READ_TABLE
ZRFC_READ_TABLE
Many SAP system only contains the ABAP function “RFC_READ_TABLE” and no other function.
![]()
If you get an error inside the Anatella-log-window that says:
SAP ERROR: cannot describe function …
or
SAP ERROR: authorization refused to access function…
This means that you need to use another ABAP function to run the extraction.
If you don’t have any ABAP function that is compatible with Anatella inside your SAP system, don’t worry: You can still get the code of a good ABAP function (that is named “ZRFC_READ_TABLE”) that is compatible with Anatella: Just click the button named “Copy a default "ZRFC_READ_TABLE" into the clipboard” (This is the parameter P11). However, in such (very uncommon situation), you’ll need to contact an SAP administrator (and thus you’ll need to have administrative rights to SAP) to add the required ABAP function inside your SAP system. Luckily, 99% of the time, the “RFC_READ_TABLE” ABAP function is available (and then you don’t need any administrative rights to run all the extractions: i.e. a simple & common SAP login is just enough).
![]()
Which ABAP function should I use? What’s the order of preference?
The order is (from best to worst):
/SAPDS/RFC_READ_TABLE
BBP_RFC_READ_TABLE
Z_AW_RFC_READ_TABLE
ZRFC_READ_TABLE
RFC_READ_TABLE
The “RFC_READ_TABLE” ABAP function has the advantage to be available in (nearly) all SAP systems.
The disadvantage of the “RFC_READ_TABLE” ABAP function is that, sometime, when working with some columns of type FLOAT, this function might cause an ABAP exception named “ASSIGN_BASE_WRONG_ALIGNMENT”. When this happens, the extraction fails (In this situation, just remove the FLOAT column that caused the error from the list of selected columns and re-run the extraction).
![]()
The extraction methogology that is used by Anatella guarantees a total safety: No data is ever written inside SAP. The extraction algorithm used in Anatella is working in pure “read-only” mode: It is thus 100% safe. There are no dangers of loosing any data from your SAP system.
All these ABAP functions proceed in the same way to do the extraction:
More precisely, they all execute the following steps:
1.Run the following SQL command:
SELECT * FROM <table_given_in_parameter_P1> WHERE <filter_given_in_parameter_P15>
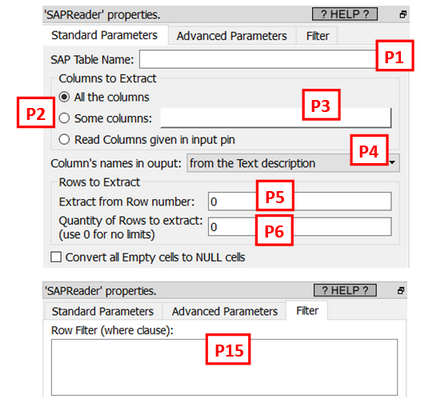
2.Run a loop to skip the first X rows of the output table of the “SQL SELECT” command that was performed during the previous step 1. The quantity X of “skipped” row is given in the parameter P5.
3.Create “in-memory” (inside the memory of the remote SAP server) a large table “T” that contains at most R rows and one single column.
The maximum quantity (“R”) of rows inside the output table “T” is defined using both the parameters P6 and P9.
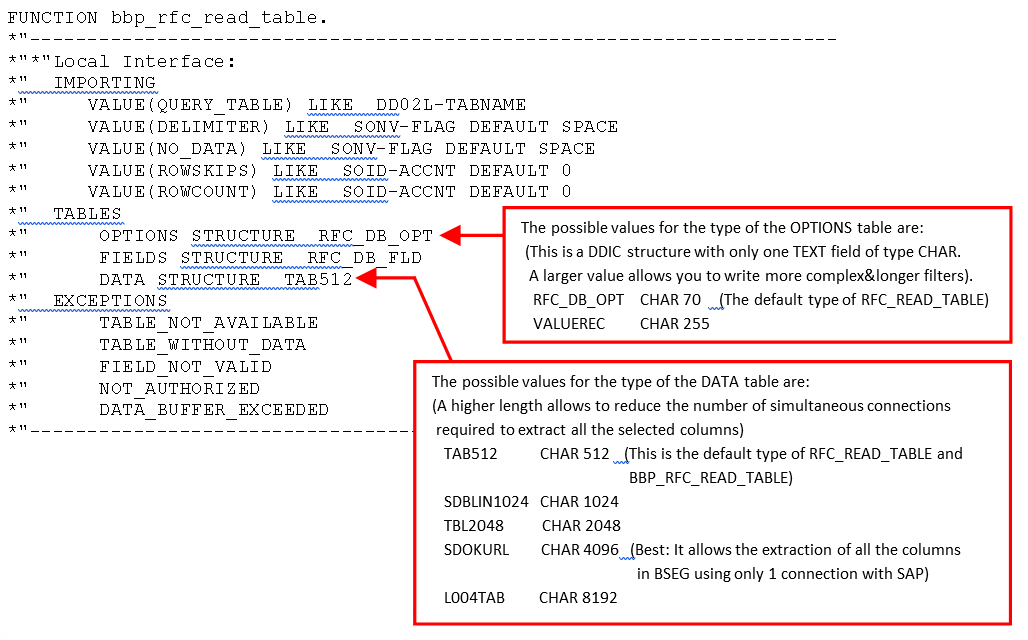
The single column of the output table “T” is a very wide column: it contains the concatenation inside one unique string “S” of all the columns that were selected using the parameters P2 and P3.
Depending on the ABAP function used, there are different limits to the length of this large string “S”. For example, when you use the standard “RFC_READ_TABLE” or “BBP_RFC_READ_TABLE” ABAP functions, the maximum length of the string “S” is 512 characters.
4.Send back to Anatella the output table “T” using the computer network. At that point, the whole output table “T” is fully stored inside both the RAM memory of the SAP server and inside the RAM memory of the Anatella server.
There are many different ways for the above ABAP function to fail. Luckily, the Anatella engine that is used to extract data from SAP has many built-in “work arounds” to still be able to run a successful extraction. You're in for a treat because the SAP-data-extraction-engine included inside Anatella is one of the most advanced engine currently available!
The most common cause of failure is due to the limitation on the length of the string “S” (that is used inside the single column of the output table). By default, this string “S” is limited to 512 characters and this is way too short to be able to extract all the columns of nearly all the “wide” tables (such as the “BSAK” table from SAP).
One first solution (to this “512 characters-limit” problem) is to avoid to extract all the columns from the SAP table and only extract a subset of the columns (i.e. to stay below the 512-character limit). To do so, you can just select, using the parameter P2 and P3, the minimum number of columns that are required to do your analysis. To help you, when you click on P3, Anatella displays here in real-time the number of characters required to do the extraction (this is very handy!): ![]()
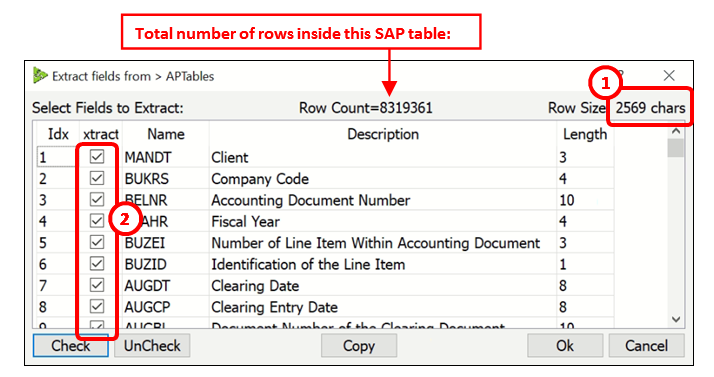
This means that you can click here: ![]() to easily select with your mouse the columns to extract and directly see if you are still below the 512-character limit here:
to easily select with your mouse the columns to extract and directly see if you are still below the 512-character limit here: ![]()
![]()
Wen you click on P3, Anatella connects to the SAP sever to retrieve information about the columns in the currently selected table. If the connection to SAP fails, Anatella will display the standard “Column chooser” window (to still enable you to edit your column’s selection). So, if you see the “Column chooser” window when you click on P3, it means that you need to check your log window for more details on why the SAP connection failed.
When you click on P3, Anatella also displays the total row count of your currently selected SAP table. To get this row count, Anatella calls the SAP function named “EM_GET_NUMBER_OF_ENTRIES”. If you don’t have this function inside your SAP system, or if you don’t have sufficient priviliges to execute this function, then Anatella will not be able to display the “Row Count” (No worries: everything else still works without any trouble: e.g. the table extraction and the column selection still works ok). If you don’t see any row count, check the Anatella log window to get more details on why you couldn’t execute “EM_GET_NUMBER_OF_ENTRIES”.
For analytical tasks, the above solution is not very convenient because, when you are working on an analytical project, you don’t know in advance what are the columns that you’ll need later on (most of the time). So, you want to be able to extract all the columns easily so that you have everything available, just in case you need it later. This is when the parameter P10 comes into play (by default, it’s “512”). The parameter P10 informs Anatella that it cannot extract more than P10 characters using one connection to SAP. So, a possible workaround (to the “512 characters-limit” problem) is to open several simultaneous connections to SAP! Each connection extracts a different subset of the user-selected columns (to always stay below the character limit defined in the parameter P10) and, finally, Anatella re-combine everything into one single “wide” table. In other words, Anatella merges into one table all the different small tables obtained from the different small extractions (that are each running using a different SAP connection). Don’t worry if this explanation looks complex: In reality, everything is totally transparent and non visible to the final user. When Anatella opens several simultenous connections to SAP, you’ll just see inside the Anatella log window the following warning message:

The obvious advantage of opening several simultaneous connections to SAP is that you are not limited anymore to 512 characters per row. The downsides are the following:
•The load on the SAP server is slightly higher.
•Since we are using several different connections to extract the data from SAP, we cannot enforce any ACID properties anymore. To know more about the ACID properties of databases, please refer to this page: https://en.wikipedia.org/wiki/ACID
To summarize, it can happen a very uncommon situation where we have some inconsistencies between the different columns that were extracted using the different connections.
To avoid this inconsistent situation, the Anatella engine runs all the required extractions simultaneously, at the exact same time, so that it’s almost impossible to obtain inconsistant data. Just to be sure, it’s also better to run your extraction during the night, when the load on the SAP server is at a minimum.
You shouldn’t care too much about this last point because, the most common database that is used "behind-the-scene" in SAP is DB2 and DB2 does not support any ACID properties anyway.
Another common cause of failure of the extraction is an excessive RAM consumption.
An “out-of-RAM” memory error can happen…
•…during step 1: During this step, the SAP system runs a heavy “SELECT * FROM table” SQL command without placing any limits on the number of rows or on the number of columns returned by the “SQL SELECT” command.
This means that, even if you used the Anatella parameter P6 to extract only 1 row out of the SAP system, the SAP server will still run this heavy “SQL SELECT” command that can, potentially, materialize inside the RAM memory of the SAP server a (very heavy) table with millions of records. This is just horrible.
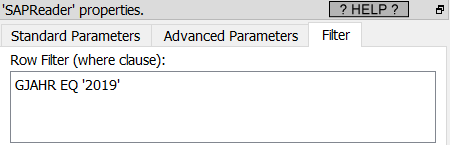
To avoid this situation, you can use the parameter P15 to reduce the size of the table returned by the “SQL SELECT” command. For example, if you want to extract from the table “BSAK” all the rows where the “Invoicing Year” (i.e. the column “GJAHR” in SAP) is 2019, you’ll write:
Please note that the SQL language used inside SAP is not a “standard” SQL: For example:
oSimple operators used to compare field values are EQ, NE, GT, LT, GE and LE (equivalent to =, <>, >, <, >=, <=).
oYou need to place numbers in-between single quotes.
This means that this “standard” SQL command:
SELECT * from BSAK WHERE GJAHR=2019
…will not work inside SAP and you need to write instead:
SELECT * from BSAK WHERE GJAHR EQ '2019'
(see also the screenshot here above to know how to write this row filter inside Anatella).
If you see the following message inside the Anatella log window:

…this means that the SAP system does not understand your user-defined “Where clause” SQL filter that is defined inside the parameter P15 (i.e. There is a syntax error inside your “Where clause”).
•…during the Steps 3 and 4: During these two steps, the SAP system creates in-memory the output table “T” (inside the RAM memory of the SAP server and, thereafter, inside the RAM memory of the Anatella server). This output table “T” might be very large and consume too much RAM memory.
In such situation, you’ll see inside the LOG of the SAP server:
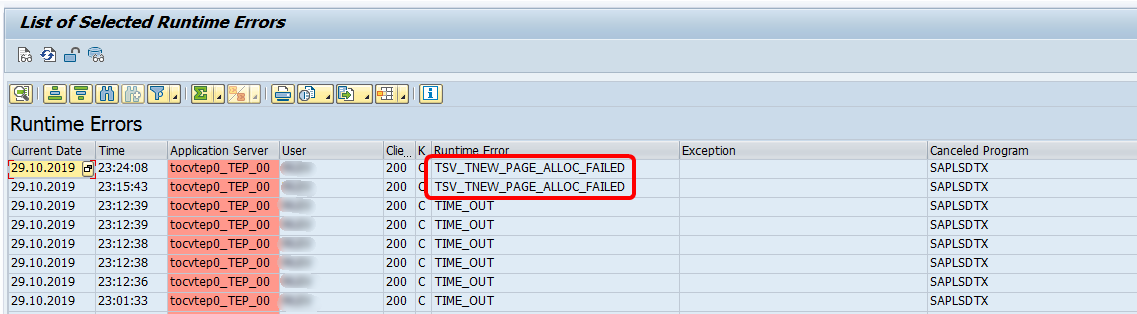
To solve this error, you need to reduce the RAM memory consumption required to run the extraction: e.g. one solution is to reduce the number of rows inside the output table “T” that is used during the steps 3 and 4 of the ABAP function. To reduce the number of rows inside the output table “T”, you can decrease the value of the Anatella parameter P9.
Let’s now assume that:
oThe Anatella parameter P9 is 1000.
In other words, the maximum size of the output table “T” is 1000 rows.
oThere are, in total, 3500 rows inside table to extract from SAP.
In such a situation, Anatella will run the ABAP function 4 times (i.e. Anatella will run 4 extractions):
oRun 1: Anatella extract the rows 0 to 1000
oRun 2: Anatella extract the rows 1000 to 2000
oRun 3: Anatella extract the rows 2000 to 3000
oRun 4: Anatella extract the rows 3000 to 3500
Anatella will automatically merge the 4 tables obtained from these 4 extractions into a single large table. Everything is totally transparent and non visible to the final user.
The obvious advantage of using a small value for the parameter P9 is that you will use less RAM memory on the server and, thus, your extractions are more likely to run successfully. The downsides are:
oA longer extraction-time because: If you use a smaller value for the parameter P9, you will be forced to make many more calls to the ABAP function to extract the full table. And, each of these “calls” introduces a significant overhead (i.e. the overhead is really big: it’s the time required to run the steps 1 and 2 from the ABAP function). This overhead is heavily slowing down the extraction procedure.
To reduce the overhead, you can use the parameter P15 to add a “Where clause” filter because this effectively reduces the running-time of the steps 1 and 2 from the ABAP function.
oSince we are using several different runs to extract the data from SAP, we cannot enforce any ACID properties anymore
Finally, the SAP system sometimes returns a “TIME OUT error” for no apparent reason. No worries: When this happens Anatella just re-runs the extraction of the last block of rows (the size of this block of row is defined using the parameter P9) and the extraction continues without any problem. The parameters P13 and P14 control how Anatella reacts to the TIME OUT errors. If you see many TIME OUT errors, it might be because you are extracting data from SAP at a “too high pace” for your (old) SAP system to handle: i.e. You need to slow down a little: i.e. You should increase the parameter P12 to a higher value (e.g. 40).