![]()
Warning: Anatella does not support EDI files that:
• … contains encrypted segments (i.e. EDI files that contains USA, USC and USH segments).
• … contains segments with binary data (i.e. EDI files that contains BIN or BDS segments): If you want to add binary data to EDI files, use Base64 encoding.
These segments are very uncommon and only appears in very old grammars.
![]()
Warning: Anatella does not support X12 files that have “Repetition Separators” with a repetition factor greater than 1. “Repetition Separator” are currently defined inside the X12 standard but they are never used with a repetition factor greater than 1, so we are perfectly safe here.
The first step is to specify the filenames of your EDI or X12 files: See section 5.1.1 to have more information on this subject (i.e. You can read the filenames from the input pin. You can also use relative path, wildcards, and Javascript to specify your filename(s)).
The second step is to select the Grammar: Go to the second panel (named “Grammar, Segments & Codes”) and click the button “Select Grammar from Templates”. You’ll see the following window:
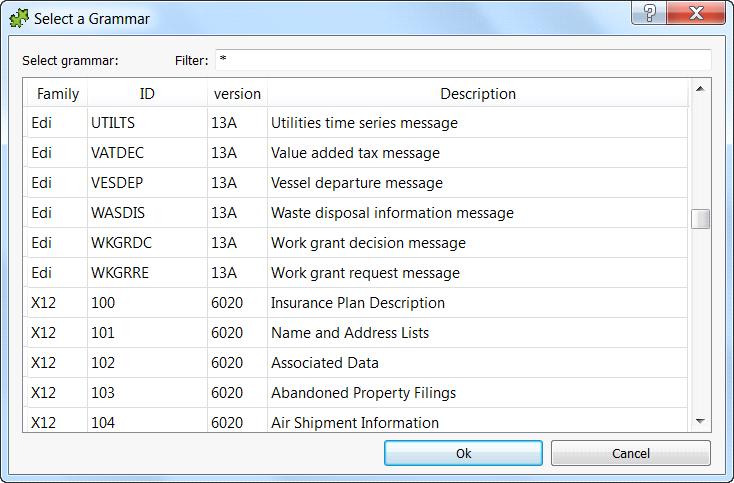
Inside Anatella, there are currently nearly 200 “EDI grammars” and more than 300 “X12 grammars” to choose from. So, you are nearly assured to find the exact grammar that you need. If you don’t find your grammar, don’t worry: You can still easily add manually later a new grammar (or edit/tweak an existing grammar so that it matches your exact file’s structure).
Select your grammar (click the required row inside the table) and click “Ok”.
The third step is to select the fields that you want to extract out of the EDI/X12 files. There are 2 types of fields that you can extract:
•Fields extracted from the “Enveloppe” data (i.e. from the UNB&UNG segments for EDI or from the ISA&GS segments for X12). You can specify these fields in the third panel (that is named “Advanced Parameters”):
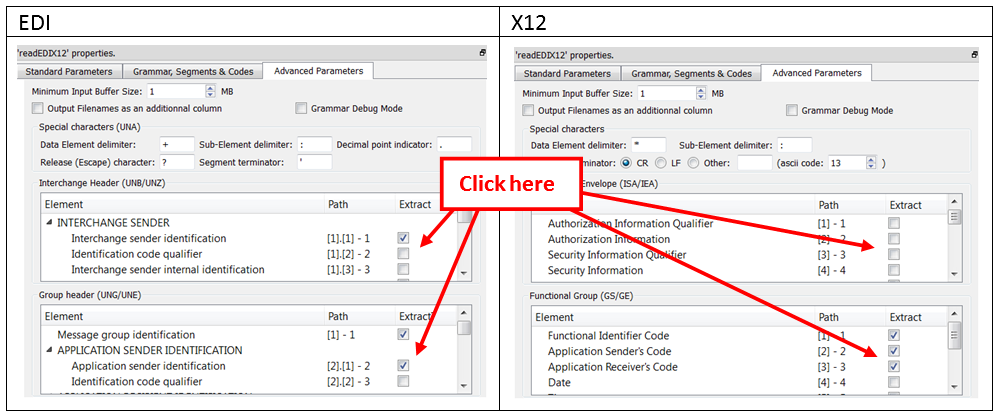
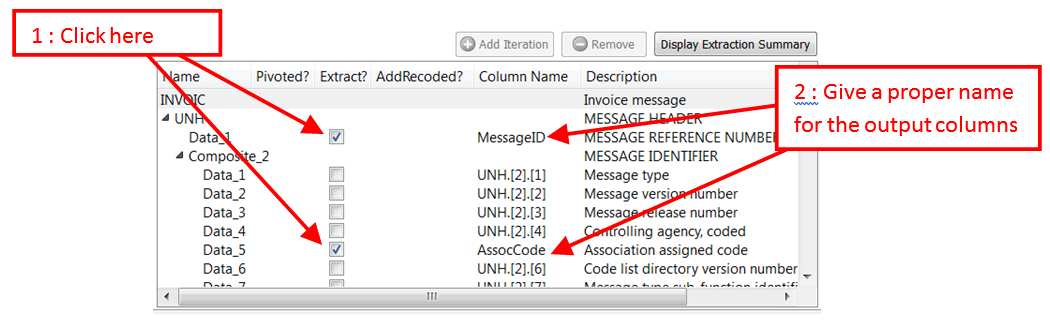
•Fields Extracted from the Message Segments (These fields depend on the selected grammar). You can specify these fields in the first panel (that is named “Standard Parameters”): For example: Let’s assume that you want to extract the fields “Message Reference Number” and “Association Assigned Code” out of each of your messages: We’ll have:
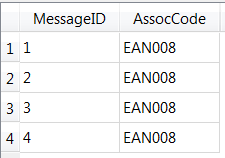
We get the following output table:
Let’s now look at a more complex EDI/X12 extraction example:
EDI Grammar |
EDI file to parse |
<Message envelope='Edi' id="INVOIC" desc="Invoice"> <Seg id="UNH" l="1"/> <Loop id="G1" u="99" desc="NAD - Name and address"> <Seg id="NAD" l="1"/> <Loop id="G2" u="9999" desc="RFF - Reference"> <Seg id="RFF" l="1"/> <Seg id="DTM" u="5"/> </Loop> </Loop> <Seg id="CUX" l="1"/> </Message> |
UNB+UNOC:3+ss:14+dd:14+11:0345+1016' UNH+1+INVOIC:D:96A:UN:EAN008' NAD+BY+1111' NAD+SU+2222' RFF+VA:2222.2' NAD+DP+3333' NAD+IV+4444' RFF+VA:4444.4' RFF+VA:5555.5' CUX+2:EUR:4' UNT+9+4' UNZ+1+1016' |
We want to extract the string “BY”: i.e. We want to extract the first “Data-Element” of the NAD Segment inside the first iteration of the Loop “G1” (that starts with the NAD Segment): We’ll have:
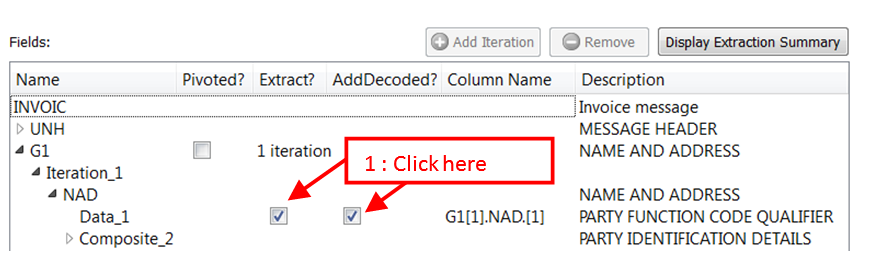
We get the following output table: ![]()
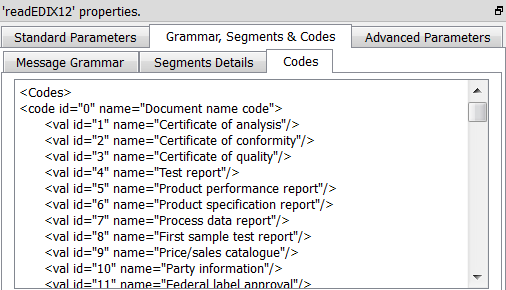
Note that we asked to decode the string “BY” (to get “Buyer”). The “decoding tables” are editable: They are given inside the subpanel “Codes” inside the panel “Grammar, Segment & Codes”:
Now, we want to also extract “SU”: i.e. We want to extract the first “Data-Element” of the NAD Segment inside the second iteration of the Loop “G1” (that starts with the NAD Segment): We’ll have:
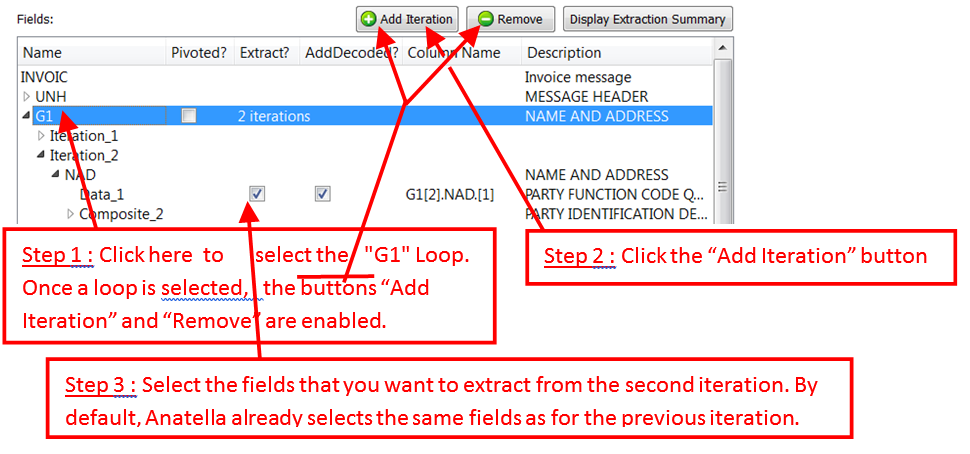
We get the following output table: 
Now, let’s assume that we want to extract the first “Data-Element” of all the NAD Segments inside all the iterations of the “G1” Loop. There are two different approaches to this request:
1.We can click many times on the button “Add Iterations” (to add more iterations), until we have enough iterations to be (more or less) sure to get the data from all the iterations of the “G1” Loop. This is not a very good&efficient solution (and, also, it creates very wide output tables, and wide tables can be annoying from time to time).
2.We can click the “Pivoted” checkbox:
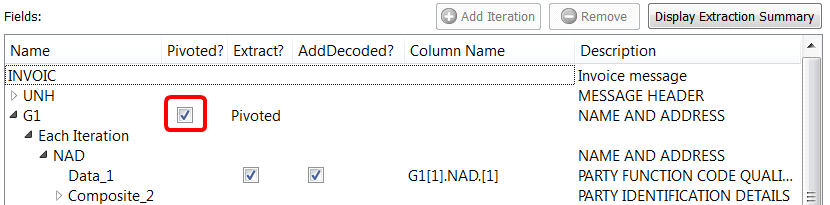
When the “Pivoted?” option is enabled, Anatella creates a new row inside the output table for each different iteration of the “G1” Loop. We get the following output table:

You can check several times the pivoting option (at different level of the Hierarchy). For example:
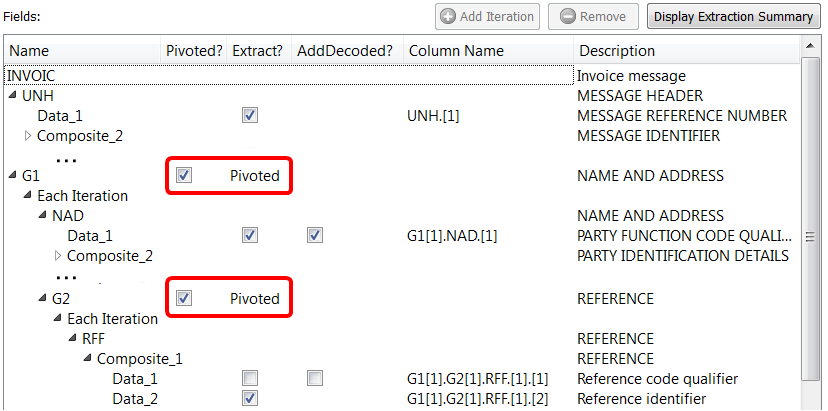
Anatella now creates a new row inside the output table for each different iteration of the “G1” or “G2” Loop. We get the following output table:

![]()
Defining several pivoting points is equivalent to defining several “Levels” inside the XML parser. See section 5.2.10.2 about an example of XML extraction with multiple levels.
Anatella is extracting data only from the messages whose name matches the name of the selected grammar. For example: If we have selected the grammar “INVOIC”:
… then Anatella will only process the “INVOIC” messages (simply skipping the others).
This means that, to updates all the required tables inside your enterprise-level datawarehouse using the data originating from EDI/X12 files, you’ll typically read several time the same EDI/X12 file(s) (using different grammars and different field’s selection).