EDI/X12 files are text files that contains a tree data structure (much like XML or JSON). The ![]() ReadEdiX12 Action creates a simple table from the EDI/X12 files: i.e. it ‘flattens” the tree-structure to obtain a simple table.
ReadEdiX12 Action creates a simple table from the EDI/X12 files: i.e. it ‘flattens” the tree-structure to obtain a simple table.
An EDI/X12 file is composed of different “Segments”. Each Segment is separated from the next one using a special character: the “Segment Terminator”.
|
Default Segment Terminator |
EDIFACT |
Quote ‘ |
X12 |
Caret ^ or Line Feed (LF) or both |
Each segment is composed of several “Data Elements”. The different “Data Elements” are separated using a special character: the “Data Element Delimiter”.
|
Default Data Element Delimiter |
EDIFACT |
Plus + |
X12 |
Star * |
The first “Data Element” of a segment contains the Segment Name. Some “Data Elements” (but not all) are composed of several (sub)fields. These special “Data Elements” are named “Composite Data Elements”. Each field inside a “Composite Data Element” is is separated from the next field using a special character: the “Sub-Element Delimiter”.
|
Default Sub-Element Delimiter |
EDIFACT |
colon : |
X12 |
colon : |
Here is an example of EDI/X12 file (we added a CR/LF after each segment to make it easier to read):
EdiFact |
X12 |
The following example is an EDI file that describes a PURCHASE ORDER. It contains the following segments: UNH, BGM, NAD, LIN, QTY, PRI, UNS, CNT, UNT.
UNH+SSDD1+ORDERS:D:03B:UN:EAN008’ BGM+220+4768+9’ DTM+137:20140930:102’ NAD+BY+541234::9++XYZ Company+123 Church Street+Brussels+BX+1050+BE’ LIN+1+1+ID-12AB+VN’ QTY+1:100:EA’ PRI+AAA:2765’ UNS+S’ CNT+2:100’ UNT+10+SSDD1’ |
The following example is an EDI file that describes a PURCHASE ORDER (850). It contains the following segments: ST, BEG, N1, N3, N4, PO1, STT, SE.
ST*850*54001^ BEG*00*SA*4768*65*20140930^ N1*SO*XYZ Company^ N3*123 Church Street^ N4*Brussels*BE*1050^ PO1*1*100*EA*27.65**VN*ID-12AB^ CTT*1*100^ SE*9*54001^ |
![]()
Inside an EDI file, the NAD segment contains an address.
In the example above the addess is:
XYZ Company
123 Church Street
1050 Brussels – BE
If the street name contains a special characters (such as the ‘, the + or the : ), we need to “escape” it (so that it’s not interpreted as a “Segment Terminator”, a “Data Element Separator” or a “Sub-Element Separator”). The default “Escape” character is the “Question Mark”(?).
For example, if the street name is:
2+ Is it Bob? Street
… the EDI file contains:
2?+ Is it Bob?? Street
Let’s now illustrate the tree structure of an EDI/X12 file.
Let’s create an EDI/X12 file that represents the following tree:
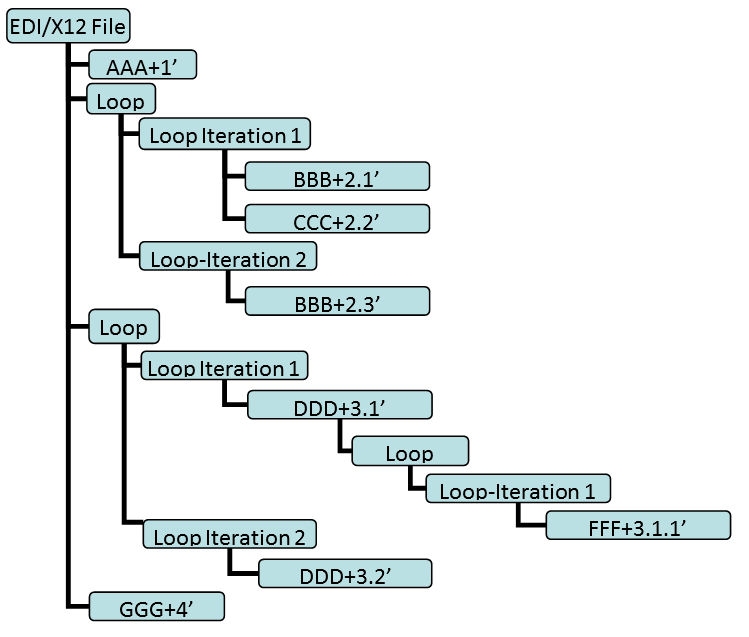
The corresponding EDI/X12 file is (we added CR/LF and spaces after each segment to make it easier to read):
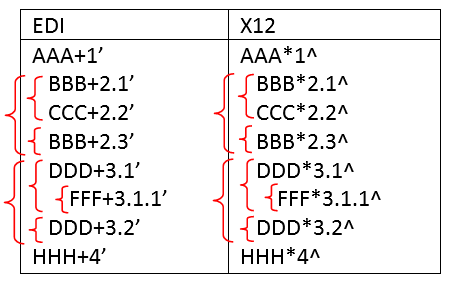
The corresponding XML or JSON file is:
XML File |
JSON File |
<File> <AAA v=’1’/> <Loop> <Iteration> <BBB v=’2.1’/> <CCC v=’2.2’/> </Iteration> <Iteration> <BBB v=’2.3’/> </Iteration> </Loop> <Loop> <Iteration> <DDD v=’3.1’/> <Loop> <Iteration> <FFF v=’3.1.1’/> </Iteration> </Loop> </Iteration> <Iteration> <DDD v=’3.2’/> </Iteration> </Loop> <HHH v=’4’/> </File> |
{ “File”: { “AAA”: [“1”], “Loop”: [ { “BBB”: [“2.1”], “CCC”, [“2.2”] }, { “BBB”: [“2.3”] } ], “Loop”: [ { “DDD”: [“3.1”], “Loop”: [ { “FFF”: [“3.1.1”] } ] }, { “DDD”: [“3.2”] } ], “HHH” : [“4”] } } |
A difficulty with EDI/X12 files is that there are no tags inside the file that “close” a level: i.e. There are no “</loop>” tags (i.e. no “end-of-loop” tags), no “</iteration>” tags (no “end-of-iteration” tags) (…or in JSON: There are no “]” or “}”).
Inside an EDI/X12 file, to know if you need to either “go down” a hierarchical level, either “close” a hierarchical level (i.e. “go up”) or either start a new iteration at the same hierarchical level, you need to refer to the grammar of the EDI/X12 file. Without the grammar, you cannot properly decipher an EDI/X12 file. Here is the grammar used to parse the above file (note that this grammar refers to the segments “EEE” and “GGG” but the example file did not contain any such segments, since they are optional):
<Message envelope='Edi'> <Seg id=’AAA’/> <Loop u=’-1’> <Seg id=’BBB’/> <Seg id=’CCC’/> </Loop> <Loop u=’-1’> <Seg id=’DDD’/> <Loop u=’-1’> <Seg id=’FFF’/> <Seg id=’GGG’/> </Loop> <Seg id=’EEE’/> </Loop> <Seg id=’HHH’/> </Message> |
The grammar contains two type of tags: “Seg” tags and “Loop” tags.
The “Seg” tags indicate that the EDI/X12 file might contain here a specific segment, with a specific name. The attributes of a “Seg” tag are:
•“id”: the name of the segment
•“l” (optional: if omitted, l=0): if l=1, then the segment if mandatory (i.e. it must appear inside the EDI/X12 file). “l” stands of “lower bound”.
•“u” (optional: if omitted, u=1): The number of time this segment might be repeated inside the ED/XC12 file. If u=-1, then an unlimited number of repetition is authorized. “u” stands of “upper bound”.
The “Loop” tag indicates that the EDI/X12 file might contain here a loop (i.e. a repetition of several segments). “Loops” are sometime refered as “Segment groups” inside Edi-Fact documentation. You can have a Loop within a Loop. The attributes of a “Loop” tag are:
•“id”: the name of the loop. Usefull only for debugging purposes. It’s not used to parse the EDI/X12 file. It’s also used when saving the .anatella file (The XPath expressions used to describe the fields to extract out of the EDI/X12 file are using the loop’s names).
•“l” (optional: if omitted, l=0): if l=1, then the loop if mandatory (i.e. the loop must appear inside the EDI/X12) file.
•“u” (optional: if omitted, u=1): The number of time this loop might be repeated inside the ED/XC12 file. If u=-1, then an unlimited number of repetition is authorized.
The first segment inside a Loop is special: It marks:
•The start of the loop (i.e. We “go down” one hierarchical level).
•The start of a new iteration of the loop (i.e. We stay at the same hierarchical level and we start a new iteration of the loop)
For example, if we have the following grammar:
<Seg id=’AAA’>
<Loop id=’G0’>
<Seg id=’BBB’/>
<Seg id=’CCC’/>
</Loop>
<Seg id=’CCC’/>
… and the following EDI files:
AAA+1’ CCC+3’ |
AAA+1’ BBB+2.1’ CCC+2.2’ CCC+3’ |
AAA+1’ BBB+2.1’ CCC+2.2’ BBB+2.3’ CCC+2.4’ CCC+3’ |
We don’t enter the loop at all because we din’t find the ‘BBB’ segment that marks the start of the loop. |
We enter the loop “G0” only one time because, for the second iteration, we din’t find the ‘BBB’ segment. In other words, the ‘BBB’ segment (that marks the start of the second iteration) is missing. |
We make two interations of the loop “G0”. |
![]()
The following grammar:
<Seg id=’AAA’>
<Seg id=’BBB’>
<Seg id=’CCC’>
…won’t be able to parse this file:
AAA+1’
CCC+1’
BBB+1’
…because Anatella expects the segment “BBB” after the segment “AAA” (and not the segment “CCC”).
In such situation, you will get a parsing error. To solve the error, you need to correct the grammar. (The correct grammar for the above example is:
<Seg id=’AAA’> <Seg id=’CCC’> <Seg id=’BBB’> ).To easily find what corrections are required inside the grammar, you can activate the “Grammar Debug Mode”:
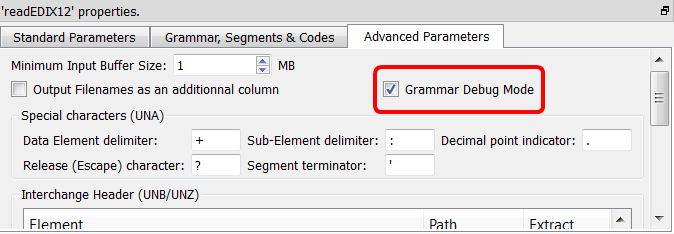
When the “Grammar Debug Mode” is activated, you’ll see inside the Anatella Log window some messages that gives you a precise explanation of the parser state (it explains you at which position inside the hierarchical structure of the document the parser is). You can see when the EDI/X12 parser “goes down” or “goes up” one hierarchical level, when it starts a new iteration, etc.
For example:
EDI/X12: parsing segment UNB - extract 5 element(s).
EDI/X12: parsing segment UNH -nothing to extract.
EDI/X12: parsing segment BGM -nothing to extract.
EDI/X12: parsing segment DTM -nothing to extract.
EDI/X12: skipping segment DTM
EDI/X12: skipping segment DTM
EDI/X12: Entering Loop 'G0' starting with 'RFF'
EDI/X12: parsing segment RFF -nothing to extract.
EDI/X12: Leaving Loop 'G0'
EDI/X12: Entering Loop 'G1' starting with 'NAD'
EDI/X12: parsing segment NAD -nothing to extract.
EDI/X12: Next iteration (1) of Loop 'G1' starting with 'NAD'
EDI/X12: skipping segment NAD
EDI/X12: Entering Loop 'G2' starting with 'RFF'
EDI/X12: skipping segment RFF
EDI/X12: Leaving Loop 'G2'
EDI/X12: Next iteration (2) of Loop 'G1' starting with 'NAD'
EDI/X12: skipping segment NAD
EDI/X12: Next iteration (3) of Loop 'G1' starting with 'NAD'
EDI/X12: skipping segment NAD
EDI/X12: Entering Loop 'G2' starting with 'RFF'
EDI/X12: skipping segment RFF
EDI/X12: Leaving Loop 'G2'
EDI/X12: Leaving Loop 'G1'
EDI/X12: Entering Loop 'G6' starting with 'CUX'
EDI/X12: parsing segment CUX -nothing to extract.
EDI/X12: Leaving Loop 'G6'
…
Once all the segments are assembled according to a grammar, they form a complete electronic document. When you need to transfer several of these electronic documents, you can include them inside a single file. The procedure is named “enveloping”. The envelope data is composed of different additional segments that precedes and follows all the electronic documents. This is illustrated on the following charts:
EDI Enveloping |
X12 Enveloping |
|
|
Enveloppe Levels: 1.Message (UNH/UNT) 2.Functional Group (UNG/UNE) 3.Interchange (UNA/UNB/UNZ) |
Enveloppe Levels: 1.Transaction Set (ST/SE) 2.Functional Group (GS/GE) 3.Interchange (ISA/IEA) |
Example:
UNB+UNOB:4+SENDER:ZZZ+RECEIVER:ZZZ+ 20140930:1159+6002’ UNG+ORDERS+SENDER:ZZZ+RECEIVER:ZZZ+ 20140930:1159+9+UN+D:038’ UNH+SSDD1+ORDERS:D:03B:UN:EAN008’ BGM+220+4768+9’ DTM+137:20140930:102’ NAD+BY+541234::9++XYZ Company+123 Church Street+Brussels+BX+1050+BE’ LIN+1+1+ID-12AB+VN’ QTY+1:100:EA’ PRI+AAA:2765’ UNS+S’ CNT+2:100’ UNT+10+SSDD1’ UNE+1+9’ UNZ+1+6002’ |
Example:
ISA*00* *00* *ZZ*SENDER *ZZ*RECEIVER *03092014*2052*U*00401*00114*O*P^ GS*PO*SENDER*RECEIVER*20140930*252 *702*X*004010^ ST*850*54001^ BEG*00*SA*4768*65*20140930^ N1*SO*XYZ Company^ N3*123 Church Street^ N4*Brussels*BE*1050^ PO1*1*100*EA*27.65**VN*ID-12AB^ CTT*1*100^ SE*8*54001^ GE*1*702^ IEA*1*00114^
|
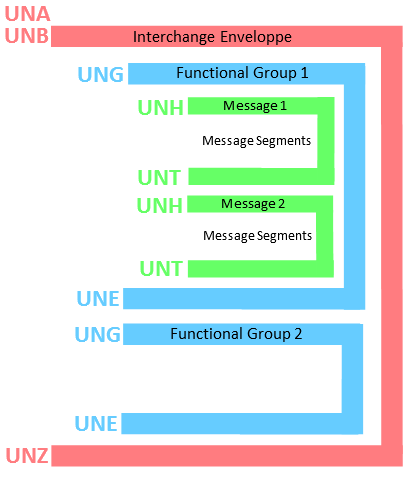
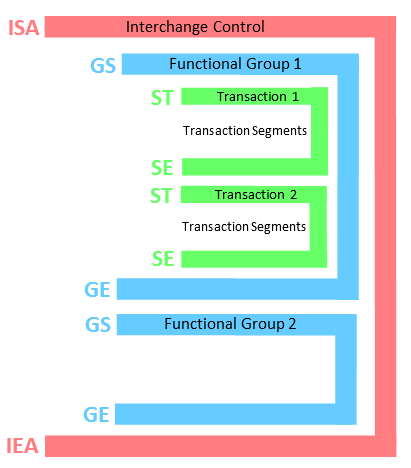
Functional Groups, often referred to as the “inner envelope,” are made up of one or more documents, all of the same type, which can be batched together into one file. Functional Groups are optional in EDI and (often) mandatory in X12.
If present, the UNA segment inside EDI files sets the values of the special characters (i.e. It sets the value of the “Segment Terminator”, the “Data Element Separator”, etc. for the current file).