Icon: 
Function: readJSON
Property window:
Short description:
Reads a (comrpressed) JSON file.
Long Description:
See section 5.1.1 to have more information on how to specify the filename of the .JSON file (i.e. You can use relative path, wildcards, and Javascript to specify your filename).
![]()
You can drag&drop a .JSON file from a MS-File-Explorer-Window into an Anatella-Graph-Window: This will directly create the corresponding ![]() ReadJSON Action inside the Anatella graph.
ReadJSON Action inside the Anatella graph.
The JSON reader included inside Anatella is stream-oriented. This means that Anatella reads the JSON file “chunk-by-chunk” (when all data from one chunk has been extracted, Anatella loads the next chunk). This is in opposition to all other JSON parsers (Almost all parsers require to load the whole JSON file in memory before starting data extraction). This means that, in opposition to other JSON extraction engine:
•There are no limits to the size of the JSON file that Anatella can read&parse.
•With Anatella, Data Extraction from JSON only requires a small (and constant) amount of RAM.
•With Anatella, data Extraction from JSON is very fast.
If the extension of the JSON file is RAR, ZIP, GZ or LZO then Anatella will transparently decompress the JSON file in RAM memory. Anatella chooses the (de)compression technique to use based on the filename extension. When Anatella uses compressed file formats, it does NOT decompress the files on the Hard Drive: Anatella decompresses the data “on-the-fly” in central core RAM memory, thus reducing:
•the load on the hard drive
•the hard-drive consumption required to do the analysis.
Usually, for classical “real world” JSON files, the compression/ratio is around 90%. Thus, it makes a lot of sense to compress all your JSON files.
Let’s assume that we have the following JSON file:
{ "ConfidentialData":
{ "Revision":3,
"Diary":
[
{ "Name":"Frank",
"Address":{"street":"villers","town": "ath", "zip":7812},
"Notes": { "age": 38 },
"Skills": [ "Coding", "Datamining" ]
},
{ "Name":"Sabrina",
"Address":{"street":"jeanne","town":"ixelles", "zip":1050},
"Notes": { "age": 36 },
"Skills": [ "Coding" ]
}
]
}
}
We want to extract the name and age of each of your contact.
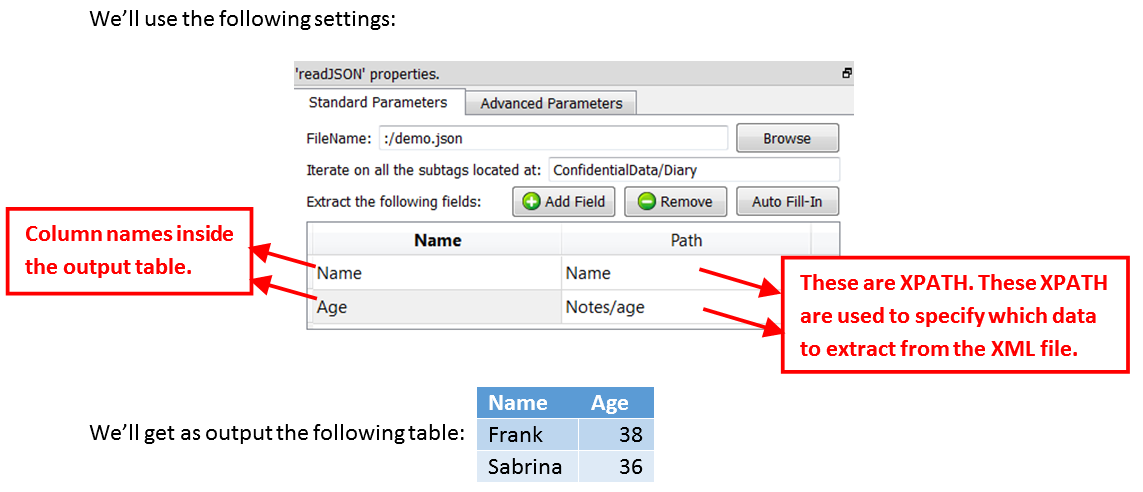
It can sometime be difficult to manually write the different required XPATHs. This is why Anatella has an “Auto Fill-In” button: After you finished entering the “Iterate on all subtags located at” parameter, you can click the “Auto Fill-In” button. Anatella will analyzes the first 100 entries in the "Diary" (You can change this number using the “Number of Rows to Analyze for Auto Fill-In” parameter inside the “Advanced Parameters” tab) and extract all the different XPATH to all the different data contained inside these first 100 entries. For the above example, Anatella will find the following XPATHs:
Name |
Address/street |
Address/town |
Address/zip |
Notes/age |
Skills/[0] |
Skills/[1] |