Let’s assume that we have the following HTML file:

When displayed inside a browser, this HTML file looks like this:
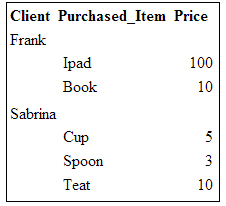
There are two “iteration levels” inside this HTML file:
•The first iteration is about the Clients
•The second level of iteration is about the transactions that each client commited. The second level is “embedded” inside the first level.
To extract this HTML, you have 2 solutions.
Here are the parameters for the first solution:
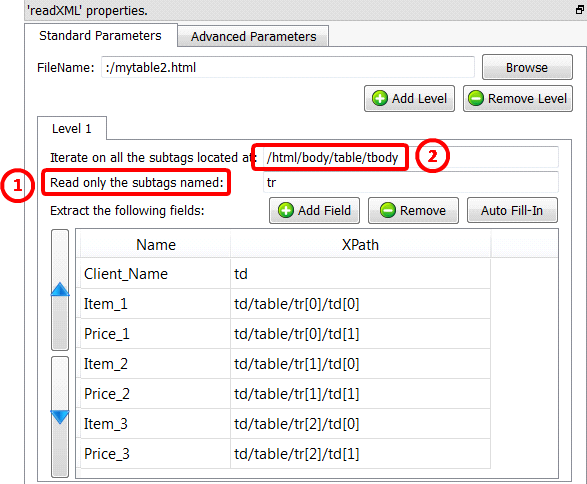
![]()
The parameter “Read only the subtags named:” is optional.![]()
If left blank, Anatella simply iterates on all the subtags found here ![]() .
.
E.g. for the above example, you can let this parameter blank: It does not change anything.
The output of the first solution is (after removing the empy row):

This first solution is not very good because the number of “Purchased items” extracted is limited to 3.
Here are the parameters for the second solution: Please note that we are now defining 2 levels:
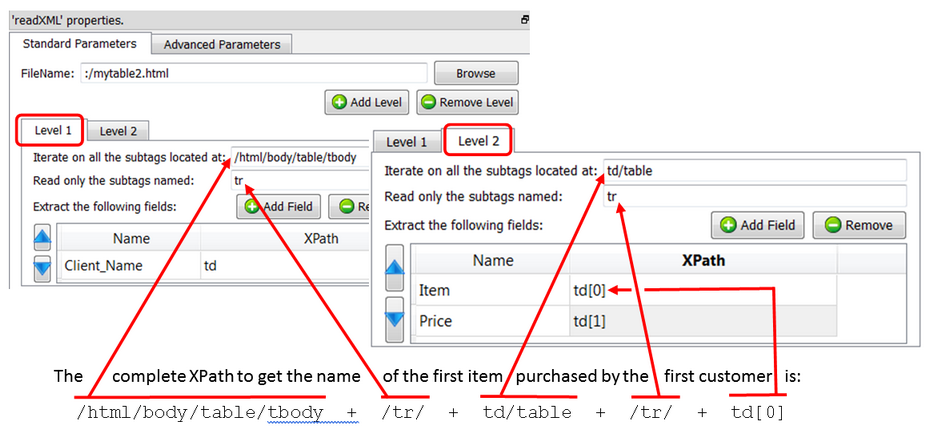
The output of this second solution is (after removing the empy row):
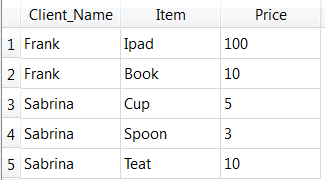
This second solution is better than the first one because it does not impose any restriction on the number of transactions that each client commited (and, also, it looks more like the original HTML file).
Anatella allows you to define as many levels as you like, so that you can easily extract any data from any HTML file, whatever the size and structure. Furthermore, it’s very easy to find the right extraction parameters for the ![]() ReadXML Action (i.e. the right XPATHs) because you can directly use the XPath expressions generated by Chrome, Firefox or IE (i.e. nearly all other HTML parsers that are based on XPath expressions can’t use XPath expressions generated by Chrome, Firefox or IE because they have problems with <tbody> tags).
ReadXML Action (i.e. the right XPATHs) because you can directly use the XPath expressions generated by Chrome, Firefox or IE (i.e. nearly all other HTML parsers that are based on XPath expressions can’t use XPath expressions generated by Chrome, Firefox or IE because they have problems with <tbody> tags).