Let’s assume that we have the following HTML file:

When displayed inside a browser, this HTML file looks like this:
Name |
Age |
Frank |
30 |
Sabrina |
25 |
David |
26 |
We want to import the above table inside Anatella. First, we need to find the XPATH that gives the location of the table inside the HTML document. To do so, open the HTML file inside a Browser (e.g. inside “Chrome”), right-click on the first cell of the table and select “Inspect Element”: See the screenshot below:
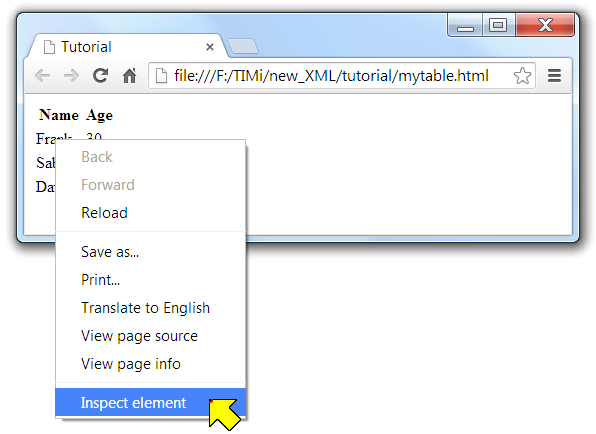
You should now see the following window:
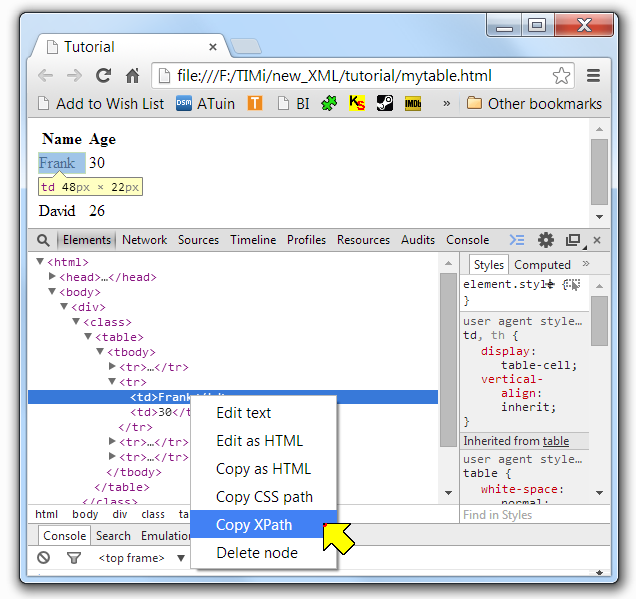
Right-click the required XML tag (i.e. the tag that contains “Frank”) and select “Copy XPath” in the cotext menu. The clipboard now contains the following XPath:
/html/body/div/table/tbody/tr[2]/td[1]
Looking at the above XPath, you can see that the XPath that represents the start of the table is:
/html/body/div/table/tbody
Open Anatella, add a ![]() ReadXML Action inside the graph, open the “Properties window” of this ReadXML Action, paste the XPath there, and click the “Auto Fill-In” button: You get:
ReadXML Action inside the graph, open the “Properties window” of this ReadXML Action, paste the XPath there, and click the “Auto Fill-In” button: You get:
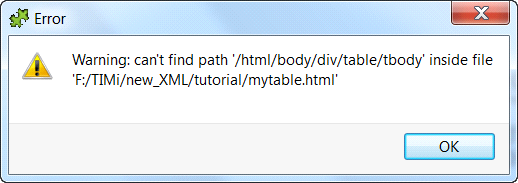
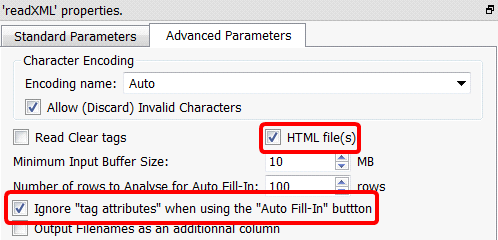
The above error message is normal because there is no “tbody” tags inside the HTML file (although a “tbody” tag appears inside your XPath expression). All the browsers always add “tbody” tags inside XPath expressions for compatibility reasons. To get around this annoying behavior from the browsers, open the “Advanced Parameters” panel and:
•Enable the check box “HTML file(s)”: In addition to properly handle “tbody” tags, Anatella now also properly handles “br”, “img”, “link”,… tags that all have a special behavior in HTML.
•Optional: Enable the check box “Ignore tags attributes when using the “Auto Fill-In” button.
You should have:
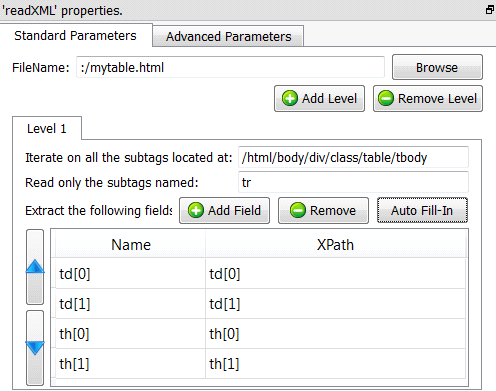
Go the “Standard Parameters” panel and click again the “Auto Fill-In” button: You now get:
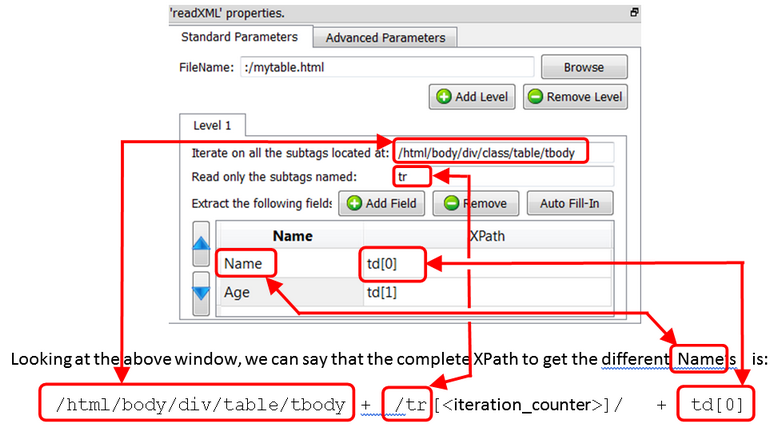
Discard the last 2 rows (i.e: the last 2 extractions - You don’t need them) and rename “by hand” the first 2 rows: You now have:
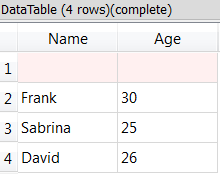
Run the extraction (i.e. click the output pin of the ReadXML action): You get:
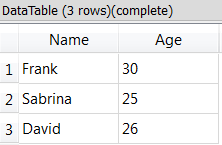
You should still add a simple ![]() FilterRow Action to remove the “empty rows” (e.g. use the following expression: “strlen(Name)>0”). You finally get:
FilterRow Action to remove the “empty rows” (e.g. use the following expression: “strlen(Name)>0”). You finally get:
![]()
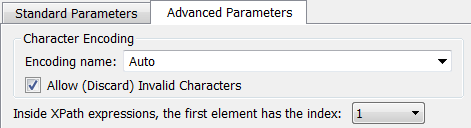
Inside Anatella, by default, the XPath indexes are zero-based (everything is zero-based in Anatella). This means that, inside Anatella, “td[0]” is equivalent to “td”. Unfortunately, HTML browsers are using indexes inside XPath expression that are “one-based” (i.e. for HTML browsers, “td[1]” is equivalent to “td”). Thus, to be able to directly copy/paste XPath expressions from your browser into Anatella, please verify that you changed the Anatella’s setting to use “one-based” XPath expression: Click here: