The OVH Cloud object storage has some very special particularities when it comes to manipulating large files. What’s a “large” file? That’s a file that is larger than the parameter P3 (“Segment Size”) from the “ovhUpload” action:
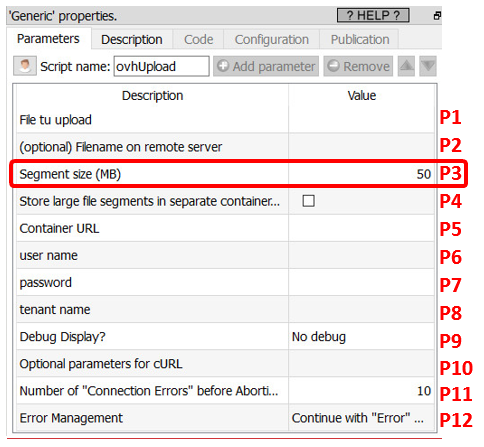
What’s happening when you upload a file that is larger than the segment size? (i.e. when you upload a file that is larger than 50MB, in the example above). For example, let’s see what’s happening if we upload a 120MB file that is named “big.txt”. The following happens:
•The “large” file named “big.txt” is splitted in many 50MB files.
Each of these 50MB file is named a “segment”.
•Each segment is uploaded to the OVH Cloud object storage.
Thus, we’ll have inside the OVH Cloud object storage, 3 file-segments that are:
Filename of the segment in the cloud storage |
Size |
big.txt|1 |
50 MB |
big.txt|2 |
50 MB |
big.txt|3 |
20 MB |
•Anatella uploads to the OVH Cloud object storage a “Manifest File” named “big.txt” that simply announce that the 3 file-segments “big.txt|1”, “big.txt|2” and “big.txt|3” are actually the different parts of a single 120 MB “logical” file that is named “big.txt”.
From now on, if you attempt to download back from the OVH cloud the file named “big.txt”, Anatella will transparently download a 120MB file (that is the concatenation of all the segment-files listed inside the “Manifest File” named “big.txt”).
If you use the ![]() OVH Cloud List File Action to list the files inside your OVH Cloud storage, you might see these 4 files:
OVH Cloud List File Action to list the files inside your OVH Cloud storage, you might see these 4 files:
Filename in the cloud storage |
Size |
big.txt |
120 MB |
big.txt|1 |
50 MB |
big.txt|2 |
50 MB |
big.txt|3 |
20 MB |
For many use-cases, we actually don’t want to see the individual file-segments that are composing the “large” files (e.g. we don’t want to see “big.txt|1”, “big.txt|2” and “big.txt|3”). So, when listing the files inside the OVH Cloud storage, there are 2 solutions to “hide” the individual file-segments:
•Solution 1 (the simplest solution)
You can uncheck the parameter P2 of the ![]() OVH Cloud List File Action. This will remove from the display all the files with a filename that ends with the character “|” followed by a number, so that we finally see:
OVH Cloud List File Action. This will remove from the display all the files with a filename that ends with the character “|” followed by a number, so that we finally see:
Filename in the cloud storage |
Size |
big.txt |
120 MB |
This solution has one small disadvantage: i.e. it’s not always 100% accurate. For example, this solution will remove from the output filename table a file that is named “myfile.txt|9” despite the fact that this file is a perfectly valid file (i.e. it’s not a segment-file). The removal occurs just because this filename unfortunately ends with the character “|” followed by a number (i.e. it just has the same “look” as a segment-file).
•Solution 2 (the more complex solution)
This second solution involves using two different OVH Cloud object containers. The first container contains all the files, with the exception of the segment files. The second container only contains the segment files. For this solution to work, you need the following:
oThe name of the second container (that only contains the segment files) must be the name of the first container followed with “_segments”. For example, if the name of the first container is “my_container”, then the name of the second container is “my_container_segments”.
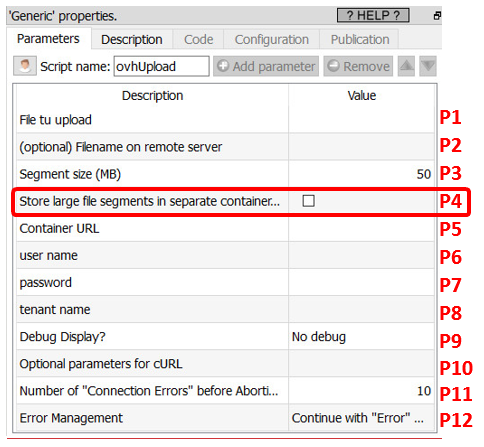
oYou must check the parameter P4 inside the “ovhUpload” action:
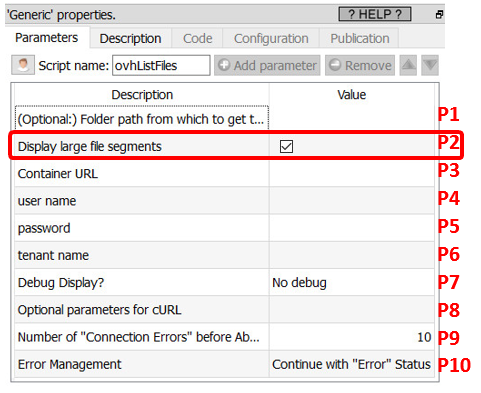
oYou must check the parameter P2 inside the “ovhListFiles” action:
This solution is better because it’s always 100% accurate: i.e. there is no risk of “hiding” a valid, non-segment file: You just display ALL the files inside the first container and you are good! 12
All the Anatella OVH Cloud Storage actions are built to handle flawlessly both the first and the second solution described here above. In particular, if you are using the second solution, this means that:
•When Anatella must download the file “big.txt” (this file is actually just a small “manifest file” that is stored in the first container), Anatella will actually transparently connect to the second container to download the appropriate file-segments.
•When Anatella must delete the file “big.txt” (that is stored in the first container), it will actually also connect transparently to the second container to delete from this second container the appropriate file-segments.
•Everything is totally transparent for the final user: i.e. it looks like all the files are simply stored inside the first container.
One final note about the parameter P3 (“Chunk Size”) from the ovhDownload Action:
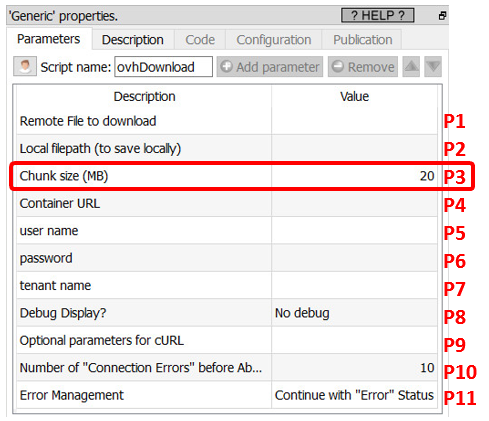
This parameter P3 (“Chunk Size”) from the ovhDownload Action is usefull when your internet connection is unstable. Anatella always downloads your files chunk-by-chunk. If the internet connection is lost during the download of one chunk, Anatella will “throw away” the incomplete/corrupted chunk and attempt to re-download again the same chunk (the number of “retries” is defined in parameter P10). A small “chunk size” means that, when the internet connection is lost, we don’t have to “throw away” a large quantity of bytes. This means that, when your internet connection is bad, you should decrease the value of the “chunk size”.
What’s happening if we want to download the 120 MB file named “big.txt” from the OVH Cloud storage and the parameter P3 (“Chunk Size”) is 20 MB? At first sight, we expect Anatella to run 6 downloads to download “big.txt” (since the file-size is 120MB and the chunk-size is 20 MB, we should have 120/20=6 downloads) but Anatella actually runs 7 downloads:
# |
Donwload from |
Download size |
Size of the local “big.txt” file after the completion of the download |
1 |
big.txt|1 |
20 MB |
20 MB |
2 |
20 MB |
40 MB |
|
3 |
10 MB |
50 MB |
|
4 |
big.txt|2 |
20 MB |
70 MB |
5 |
20 MB |
90 MB |
|
6 |
10 MB |
100 MB |
|
7 |
big.txt|3 |
20 MB |
120 MB |
We have 7 downloads (instead of the expected 6) because the downloads #3 and #6 are only 10 MB (instead of 20 MB) because we used a 50MB segment-size during the “upload”. So, to avoid un-necessary extra downloads, it’s better to use a segment-size that is a multiple of the chunk-size.