Anatella is the only tool inside the Hadoop Ecosystem that is 100% developed using native (C/C++ or assembler) code. More precisely:
•Anatella is the only tool that can manipulate the famous .parquet files (using the ![]() readParquet Action and the
readParquet Action and the ![]() writeParquet Action) using very efficient C/C++ code.
writeParquet Action) using very efficient C/C++ code.
•Anatella is amongst the very few tools that can natively access (read&write) the HDFS drive using only very efficient C/C++ code.
![]()
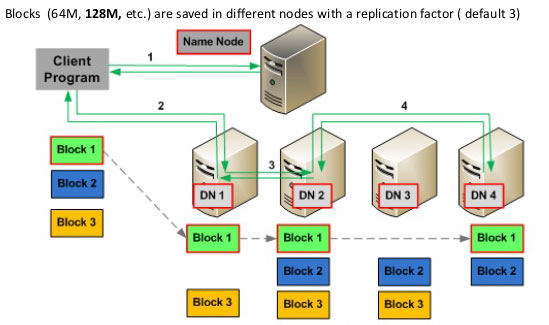
What’s an HDFS drive? An HDFS drive is a logical drive that is built “on top” of several real hard drives that are physically placed in several (usually cheap) servers. In Hadoop terminology, these servers (that contains your data) are named “data nodes”. An HDFS drive is composed of several “data nodes” (that contain data) and one “name node” (that is indexing the data contained in the HDFS drive: i.e. the name node contains an index that allows to know on which “data node” is stored each chunk/block of data).
Here is an illustration:
Thanks to its proprietary, native (code in C/C++) implementation, Anatella is faster than Hadoop/Spark clusters of any size (i.e. with any quantity of “nodes”). This is due to the relatively high incompressible time of Hadoop/Spark: you find more details on this subject here: https://timi.eu/blog/cloud/). Furthermore, thanks to its “streaming” (i.e. row-by-row) computations, Anatella is not limited to some small data files that “fits into RAM memory” (that is in opposition to Spark and to nearly all other tools inside the Hadoop ecosystem that are 100% “in-memory” tools). This means that, with Anatella, you can really process nearly unlimited datatset sizes (that is in opposition to Spark that is strongly limited to small data sizes because every input&ouput data files must fit simultaneously in the limited RAM memory available). To summarize, Anatella is for Seriously Big “Big data” processing.
![]()
Actually, one of the first thing that many companies usually do when they discover Anatella is to replace their Spark/Scala code with the much more efficient Anatella engine.
Indeed, Spark can be seen as a simple tool that reads some parquet files, transform the data contained in these .parquet files, and write back some parquet files on the HDFS drive. This type of very basic functionality is (of course) supported by Anatella.
Some of the reasons these companies abandon Spark in favor of Anatella are:
* An obvious gain in processing speed (Anatella is from 20 to 200 times faster than Spark).
* Reduced “maintenance & support” costs: Indeed, Spark is coded in this barbaric Language named “Scala”. The maintenance of a Scala code is just terrible: Only the coder that created the Scala code initially understand it (and with terrible difficulties, …and not for a very long time! �).
* Much more refined data processing: i.e. Anatella graphs allows to create data transformations that are much more complex & much more refined than the ones created with Scala.
* Scala coders are seldom and very expensive while, on the other hand, nearly any data analyst can create a good Anatella Graph.
The tools inside the Hadoop ecosystem are always exchanging data between each other using the same mechanism: i.e. they read/write .parquet files (or sometime .avro files) from/to the HDFS drive. In this regard, Anatella is no different from the other tools inside the Hadoop ecosystem: i.e. Anatella reads read/write .parquet files from/to the HDFS drive.