|
<< Click to Display Table of Contents >> Navigation: 5. Detailed description of the Actions > 5.5. Standard > 5.5.5. Aggregate (Group by) (High-Speed
|
Icon: ![]()
Function: aggregate
Property window:
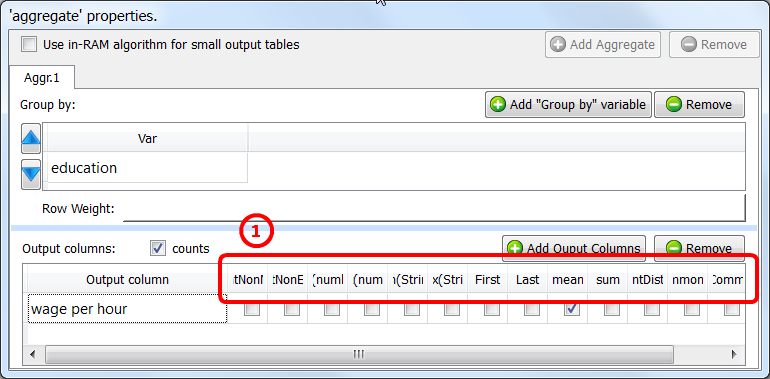
Short description:
Aggregate (or Group By) rows.
Long Description:
This action aggregates (or Group By) rows.
You can click on the header of the “output column table” ![]() to check all the checkboxes of the column.
to check all the checkboxes of the column.
If you don’t provide any “group by” variables, the whole input table will be used to compute only one output row. For example, these settings:
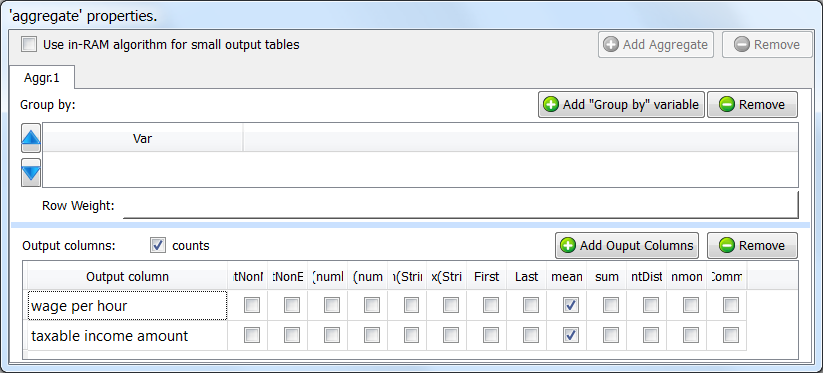
… will generate a one-row output table with the 2 columns “wage per hour_mean” and “taxable income amount_mean”.
You can give several “Group by” variables, there will be as many output rows as there are of modality-combinations into your data. For example, if your “Goup-By-variables” are: Wealth (Poor, Rich), Age (Young, Middle, Old), Sex (Woman, Man), then you will have as output these 12 rows:
Idx |
Wealth |
Age |
Sex |
1 |
Poor |
Young |
Woman |
2 |
Poor |
Young |
Woman |
3 |
Poor |
Middle |
Woman |
4 |
Poor |
Middle |
Woman |
5 |
Poor |
Old |
Woman |
6 |
Poor |
Old |
Woman |
7 |
Rich |
Young |
Man |
8 |
Rich |
Young |
Man |
9 |
Rich |
Middle |
Man |
10 |
Rich |
Middle |
Man |
11 |
Rich |
Old |
Man |
12 |
Rich |
Old |
Man |
Note that the combination (Rich,Young,Man) is very un-likely, so it might not appear as output in the result table.
There are two operating modes for this Action:
1.In-Memory Mode.
In this mode, Anatella is building “in-memory” all the output table(s) (…and there can be many output table(s)).
Anatella read the input table row-by-row: Each time a new combination (in technical term: a new “t-uple”) is found in the input table, Anatella extends the “in-memory” output/result table (it adds a new row) to store the new aggregations for this particular t-uple. If an already known combination is found, Anatella simply updates the aggregations to take into account the new input row.
In this mode, Anatella reads the whole input table before producing any output row.
This mode is very memory-hungry because it needs to store in RAM memory all the output tables. If your output tables do NOT fit into RAM memory (e.g. on a 32 bit computer: they are larger than 2GB), then Anatella won’t be able to compute the aggregation (or, it will be intolerably slow because of “memory swapping”). Thus, if you have very big output tables, you must use the Out-of-Memory Mode.
When using the “in-memory” mode, the ![]() Aggregate Action cannot be included inside a “N-Way Multithread Section” (see section 5.3.2.5. to know more about this subject).
Aggregate Action cannot be included inside a “N-Way Multithread Section” (see section 5.3.2.5. to know more about this subject).
2.Out-of-Memory Mode.
This mode allows Anatella to compute any aggregation, whatever the size of the (unique) output table.
In order to use this mode, your input table must be sorted on the “Group by” variables. This is somewhat annoying because “sorting” is always a very slow operation (that you should thus avoid). Thus, if you have small output tables, you should rather use the “in-memory mode” (unless your input table is already sorted “for free”).
Anatella read the input table row-by-row: Because of the sort, all the rows that have the same combination (i.e. the same value for the “Group by” variables)(in technical term: the same “t-uple”) are contiguous. If an already known combination is found, Anatella simply updates the aggregations to take into account the new input row. If the combination changes, then Anatella directly produces a new output row with the aggregation values of the t-uple that “just ended”.
In this mode, Anatella is producing output rows while reading the input table.
This mode consumes a negligible amount of memory space (in opposition to the “in-memory mode”).
When using the “out-of-memory” mode, the ![]() Aggregate Action can be included inside a “N-Way Multithread Section” (see section 5.3.2.5. to know more about this subject), provided that the input table is still correctly sorted on the “Group by” variables.
Aggregate Action can be included inside a “N-Way Multithread Section” (see section 5.3.2.5. to know more about this subject), provided that the input table is still correctly sorted on the “Group by” variables.