In the above example, we assumed that the text file that is used as source data for the Anatella graph is sorted on the column A. If that’s not the case, we can use the following procedure:
•Read the source text file and write it back inside many different .gel_anatella files using the “split variable” option of the ![]() writeGel Action. For example, this Anatella graph splits the data in different .gel_anatella file, one file per each different day:
writeGel Action. For example, this Anatella graph splits the data in different .gel_anatella file, one file per each different day:
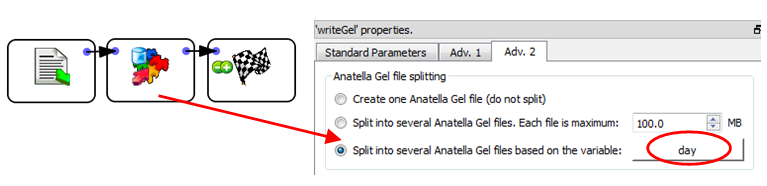
•Sort all the different .gel_anatella files that were produced at the precedent step. This sort can easily be run in parallel (one CPU for each different day/file).
I suggest you to use the “ProcessRunner” JavaScript class to run on parallel on several CPUs an Anatella graph that sorts (using a simple ![]() Sort Action) one particular day that is specified as command-line parameter to the graph (i.e. as “Graph Global Parameter”, see section 5.2.5.2.).
Sort Action) one particular day that is specified as command-line parameter to the graph (i.e. as “Graph Global Parameter”, see section 5.2.5.2.).
Although we are using the simple ![]() Sort Action, we still get high speed because:
Sort Action, we still get high speed because:
oWe are able to run the sort on many CPUs (one CPU per each different day/file).
oThe volume of data to sort is limited (it’s only one day) and it can happen that the ![]() Sort Action is able to perform the sort entirely in RAM-memory (without using any tape files). When this happens, the sort is a lot faster.
Sort Action is able to perform the sort entirely in RAM-memory (without using any tape files). When this happens, the sort is a lot faster.
oIf the data arrives on a daily basis, we can avoid re-computing all the sorts for all the previous days (by keeping on the hard drive the sorted .gel_anatella files that were previously computed) and we only sort the “last” file/day that we just received. This leads to a somewhat “incremental” sorting algorithm that only needs to sort a very small quantity of data before being able to compute very efficiently large aggregates.
•Use the ![]() MergeSortInput Action (or the
MergeSortInput Action (or the ![]() MergeSort Action) to obtain, from the different “locally sorted” .gel_anatella files, one “globally sorted” table. We’ll have:
MergeSort Action) to obtain, from the different “locally sorted” .gel_anatella files, one “globally sorted” table. We’ll have:
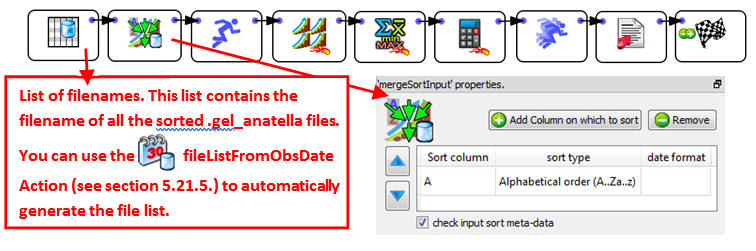
This last data-transformation-graph is even more efficient than the previous one because:
a)it starts from a set of “locally sorted” file (i.e. we used the term “locally” because we sorted “locally” each day/file on the column A and we managed to avoid sorting “globally” ALL the data from ALL the days).
b)Each day/file is only “partially” sorted (i.e. each day is sorted on the column A only).
c)It allows you to use an “incremental” sorting algorithm that reduces the computing time by several orders of magnitude. We used the term “incremental” because we only need to sort the small quantity of new days of data that we just received (and not all the days).
d)It manages to keep the 5 advantages that were explained for the previous Anatella graph:
oIt computes aggregations using many CPUs (still reducing computing time).
oYou can have output tables of unlimited size.
oIt’s not using any ![]() Sort Actions (that are slow and memory hungry).
Sort Actions (that are slow and memory hungry).
oThe little amount of sorting is performed on many CPUs (still reducing computing time).
oIt’s using a very small amount of RAM memory.