Let’s now consider the following, erroneous, data-transformation-graph:
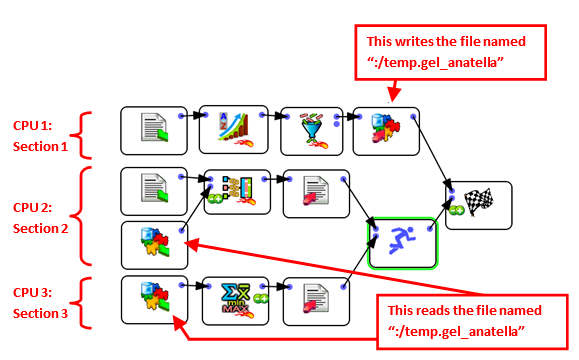
The above data-transformation-graph won’t run properly. Here is why: When we start the execution of the graph, the Sections 1, 2 & 3 will all start together, at the same time. In particular, the two ![]() ReadGel Actions (that are inside Section 2 and section 3) will directly fail because the file “:/temp.gel_anatella” has not been computed yet.
ReadGel Actions (that are inside Section 2 and section 3) will directly fail because the file “:/temp.gel_anatella” has not been computed yet.
For the above graph to run properly, we should wait for complete creation of the “:/temp.gel_anatella” file (this is done in Section 1) and, then (and only then), we can start reading the file (in Sections 2 & 3). In other word, we need to wait for the end of the execution of Section 1 before reading the “:/temp.gel_anatella” file. This is accomplished in the following way:
This will work properly:
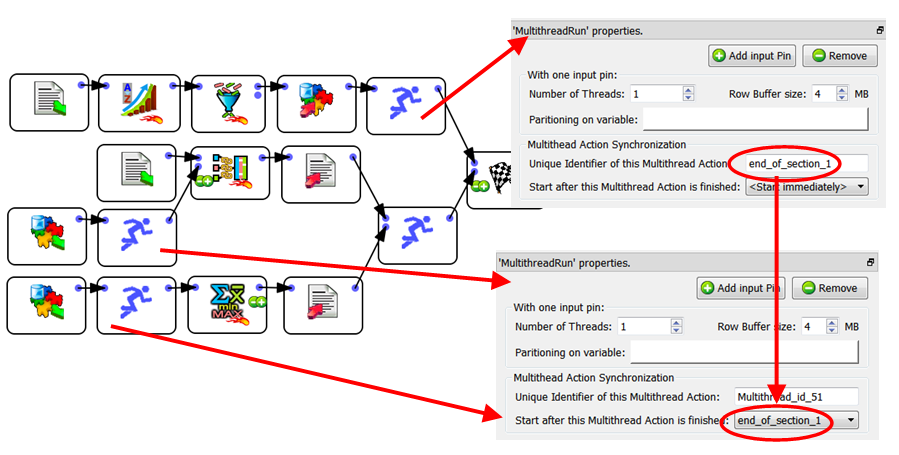
Another solution (to ensure that the file “:/temp.gel_anatella” is created before any “read” occurs) is the following:
1.Copy the section 1 into a file named “section1.anatella”.
2.Copy the sections 2 and 3 into a file named “section2and3.anatella”.
3.Use the ![]() Parallel Run action to run the two Anatella graphs “section1.anatella” and “section2and3.anatella” sequentially (and not in parallel!).
Parallel Run action to run the two Anatella graphs “section1.anatella” and “section2and3.anatella” sequentially (and not in parallel!).
Please note that, although there are three Multithreaded Sections in the above graph, it only uses a maximum of 2 CPU’s at the same time (because Section 2 and 3 do not run at the same time as Section 1). This is a common phenomenon. For example:

The above graph will NOT use 10+10=20 CPUs. Indeed, Section 2 will run only after the Section 1 is finished (this is because of the ![]() Sort Action that waits until it received all “input” rows before emitting the first “output” row). The above graph will thus use a maximum of 12 CPUs.
Sort Action that waits until it received all “input” rows before emitting the first “output” row). The above graph will thus use a maximum of 12 CPUs.
From the above graph, you can see that it’s not possible to run the ![]() Sort Action inside a N-Way section. Does-it mean that all “sorts” are performed using only one CPU? No! The following graph computes the 2 “sorts” in parallel and outputs a globally sorted “.gel_anatella” file that contains all the data from the 2 input “.gel_anatella” files:
Sort Action inside a N-Way section. Does-it mean that all “sorts” are performed using only one CPU? No! The following graph computes the 2 “sorts” in parallel and outputs a globally sorted “.gel_anatella” file that contains all the data from the 2 input “.gel_anatella” files:
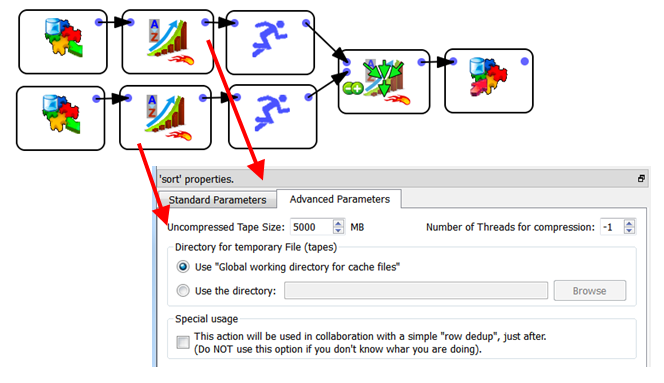
Please note that we used the ![]() MergeSort Action in order to produce a sorted output (The
MergeSort Action in order to produce a sorted output (The ![]() MergeSort Action is the equivalent of the
MergeSort Action is the equivalent of the ![]() Append Action with the slight difference that it produces a sorted output). Using the above technique, it’s possible to use many CPU’s to perform a sort.
Append Action with the slight difference that it produces a sorted output). Using the above technique, it’s possible to use many CPU’s to perform a sort.