The ![]() ReadCSV Action is “injecting” new rows (that are read from the Hard Drive) into the graph. Each time Anatella calls the ReadCSV Action, it does the following:
ReadCSV Action is “injecting” new rows (that are read from the Hard Drive) into the graph. Each time Anatella calls the ReadCSV Action, it does the following:
1.Look at the internal Row-Buffer of the Action:
a.If the Row-buffer is empty:
i.Read a bunch of data (typically 1 MB) from the Hard Drive and copy into the Row-Buffer (And, optionally, de-compress the binary data into usable data).
ii.Select the first row in the buffer.
b.If the Row-Buffer is not empty:
Select the next row in the buffer
2.“Inject” the selected row into the Anatella graph and remove it from the Row-Buffer.
The ![]() ReadCSV Actions is using a synchronous (i.e. blocking) I/O algorithm (See the section 5.2.6.2. about asynchronous I/O algorithms). This means that, while Anatella is occupied reading some data from the Hard Drive (when it copies 1MB of data from Hard Drive to main RAM memory), it “freezes” the whole Multithreaded Section that contains the
ReadCSV Actions is using a synchronous (i.e. blocking) I/O algorithm (See the section 5.2.6.2. about asynchronous I/O algorithms). This means that, while Anatella is occupied reading some data from the Hard Drive (when it copies 1MB of data from Hard Drive to main RAM memory), it “freezes” the whole Multithreaded Section that contains the ![]() ReadCSV Actions. To avoid freezing the whole data-transformation-graph, it’s a good idea to isolate the
ReadCSV Actions. To avoid freezing the whole data-transformation-graph, it’s a good idea to isolate the ![]() ReadCSV Action in a separate Section (thus using a
ReadCSV Action in a separate Section (thus using a ![]() Multithread Action).
Multithread Action).
The same remark applies to all the other “Input Action” that are based on a simple synchronous (i.e. blocking) I/O algorithm: the ![]() SASReader Action, the
SASReader Action, the ![]() ODBCReader Action, etc. For example, you’ll often have:
ODBCReader Action, etc. For example, you’ll often have:

![]()
You should not use the above combination to increase the running speed of the Action that have asynchronous (i.e. non-blocking) I/O algorithms (See the section 5.2.6.2. about asynchronous I/O algorithms): these Actions include: the ![]() GelReader Action, the
GelReader Action, the ![]() ColumnarGelFileReader Action, the
ColumnarGelFileReader Action, the ![]() readStat Action and the
readStat Action and the ![]() TcpIPReceiveTable Action.
TcpIPReceiveTable Action.
Conceptually, the logic is the same with both solution: Use an additional thread to allow the rest of the data-transformation-graph to run while the data are extracted from the Hard Drive. The difference comes from FIFO buffer located inside the ![]() multithread Action. This FIFO buffer implies a (slow) deep-copy of all the rows that are going through the
multithread Action. This FIFO buffer implies a (slow) deep-copy of all the rows that are going through the ![]() multithread Action. When using an asynchronous I/O algorithm, you don’t have to perform this deep copy at all and this is thus more efficient.
multithread Action. When using an asynchronous I/O algorithm, you don’t have to perform this deep copy at all and this is thus more efficient.
In this way, when the ![]() ReadCSV Action “freezes” (because it’s waiting for the Hard Drive), it only blocks its own Multithreaded-Section but the rest of the transformation graph (i.e. the other Sections) can still continue to run (without any interruption), using the rows that are inside the FIFO-row-buffer of the
ReadCSV Action “freezes” (because it’s waiting for the Hard Drive), it only blocks its own Multithreaded-Section but the rest of the transformation graph (i.e. the other Sections) can still continue to run (without any interruption), using the rows that are inside the FIFO-row-buffer of the ![]() Multithread Action, just next to it. Of course, if it freezes for too long (i.e. if the Hard Drive or the database is very slow), then the the FIFO-row-buffer of the
Multithread Action, just next to it. Of course, if it freezes for too long (i.e. if the Hard Drive or the database is very slow), then the the FIFO-row-buffer of the ![]() Multithread Action empties out and, once again, the whole data-processing stops (this is sometime referred, in technical terms, as a “Pipeline Stall”). This happens very often with the
Multithread Action empties out and, once again, the whole data-processing stops (this is sometime referred, in technical terms, as a “Pipeline Stall”). This happens very often with the ![]() ODBCReader Action because the databases systems are usually very slow compared to Anatella Graphs: More precisely: Databases have usually some difficulties to “deliver” the rows at the high-speed required by Anatella for optimal execution speed. In such common situation, one way to reach high-processing speed is to run “in parallel” different SQL extractions, in different Multithreaded Sections.
ODBCReader Action because the databases systems are usually very slow compared to Anatella Graphs: More precisely: Databases have usually some difficulties to “deliver” the rows at the high-speed required by Anatella for optimal execution speed. In such common situation, one way to reach high-processing speed is to run “in parallel” different SQL extractions, in different Multithreaded Sections.
For example, this is not very efficient (despite the fact that it includes several ![]() Multithread Actions):
Multithread Actions):
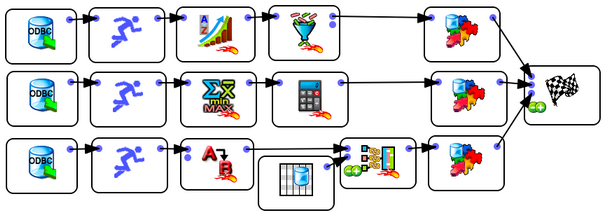
The above graph will run the 3 database extractions one after the other and the processing speed will most likely be quite slow because of “Pipeline Stalls”. The following graph (that runs the 3 database extractions “in parallel”) is a better solution:
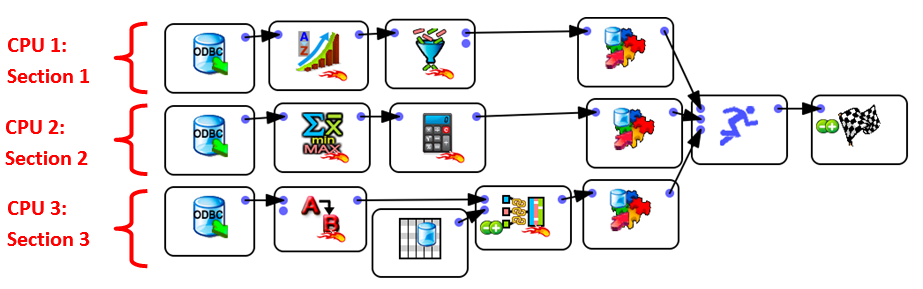
You can think of the ![]() Multithread Action with several input pins as the “multithreaded” equivalent of the standard
Multithread Action with several input pins as the “multithreaded” equivalent of the standard ![]() GlobalRunFlag. The
GlobalRunFlag. The ![]() GlobalRunFlag executes the graph sequentially:
GlobalRunFlag executes the graph sequentially:
First, the ![]() GlobalRunFlag runs all the Actions connected to the pin 0.
GlobalRunFlag runs all the Actions connected to the pin 0.
Once it’s finished, the ![]() GlobalRunFlag runs all the Actions connected to the pin 1,
GlobalRunFlag runs all the Actions connected to the pin 1,
Once it’s finished, the ![]() GlobalRunFlag runs all the Actions connected to the pin 2,
GlobalRunFlag runs all the Actions connected to the pin 2,
Once it’s finished, the ![]() GlobalRunFlag runs all the Actions connected to the pin 3, etc.
GlobalRunFlag runs all the Actions connected to the pin 3, etc.
In opposition, the ![]() Multithread Action executes the graph in parallel. As soon as you run the Graph (e.g. as soon as you pressed F5), all the Action connected to the
Multithread Action executes the graph in parallel. As soon as you run the Graph (e.g. as soon as you pressed F5), all the Action connected to the ![]() Multithread Action start running at the same time.
Multithread Action start running at the same time.
You can still have some control on the order in which the Actions are executed using the “Synchronization” option of the ![]() Multithread Action.
Multithread Action.