Using the ![]() Multithread Action, you can cut your data-transformation graph in different sections, each section is running on a different CPU. For example, this Anatella-Graph runs on 3(+1) CPU’s:
Multithread Action, you can cut your data-transformation graph in different sections, each section is running on a different CPU. For example, this Anatella-Graph runs on 3(+1) CPU’s:
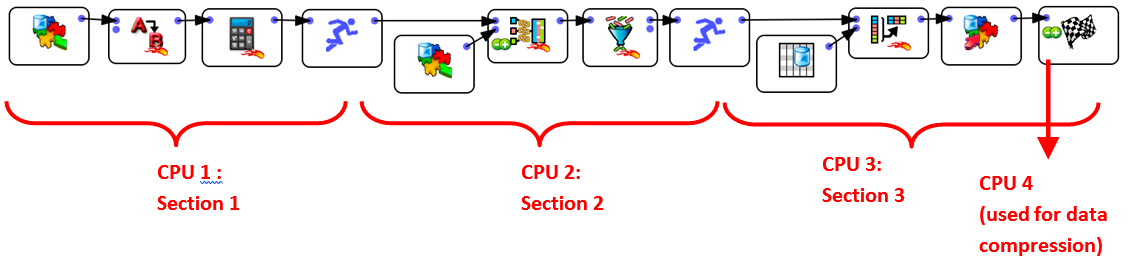
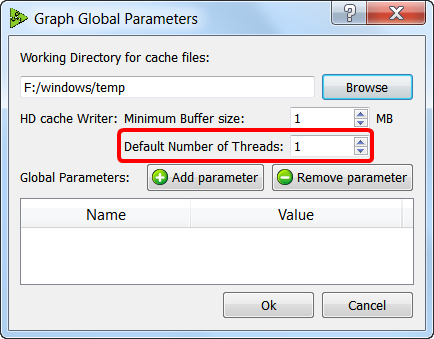
The ![]() GelWriter Action always use one or more CPU “on its own” to compress the data before writing it on the hard drive. You can change the number of CPU’s used for compression, in the “Graph Global Parameter” window:
GelWriter Action always use one or more CPU “on its own” to compress the data before writing it on the hard drive. You can change the number of CPU’s used for compression, in the “Graph Global Parameter” window:
Inside Anatella, the data is processed row-by-row. In the above graph, the ![]() Multithread Actions have 2 purposes:
Multithread Actions have 2 purposes:
1.They are defining the different “Multithreaded Sections”.
2.They are passing-by the rows from one section to another.
Typically, the different sections are processing the flow of rows at different non-constant speed. To be able to handle the small variations of data flow speed in each section, each ![]() Multithread Actions is equipped internally with a FIFO-row-buffer (“FIFO” is a technical terms meaning “First In, First Out”). Schematically, we can represent this FIFO-row-buffer in the following way:
Multithread Actions is equipped internally with a FIFO-row-buffer (“FIFO” is a technical terms meaning “First In, First Out”). Schematically, we can represent this FIFO-row-buffer in the following way:
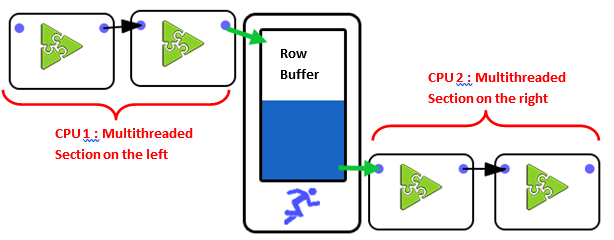
You can think of the FIFO-row-buffer as a water-tank, except that, rather than filling it with water, you fill-it with rows.
If the section on the left of the FIFO-row-buffer is processing the rows at a very high rate (higher than the section on the right), then the FIFO-row-buffer will eventually reach “full capacity”. In such situation, Anatella stops the execution of the left section for a little amount of time, so that the FIFO-row-buffer “empties out” a little.
If the section on the right of the FIFO-row-buffer is processing the rows at a very high rate (higher than the section on the left), then the FIFO-row-buffer will eventually be completely emptied out (no rows anymore). In such situation, Anatella stops the execution of the right section for a little amount of time, so that the FIFO-row-buffer “fills in” a little. This phenomenon is named “starvation”: The CPU assigned to the right section is “starving” (it does not have enough rows coming in to fulfill its big “appetite”).
To avoid stopping (temporarily) the execution of one of the section of the graph, all sections should process the rows at approximately the same speed. If all the sections have more or less the same row-flow-speed the CPU assigned to each section never stops (i.e. there is no “starvation”) and we can reach maximum efficiency: The data-transformation-graph is running at maximum speed.
In general, the speed of the data-transformation graph is determined by the speed of the slowest multithreaded section (this is the “bottleneck” of the data transformation graph).
To avoid starvation (and thus reach maximum processing speed), you must correctly “balance” the workload of each segment.