Icon: 
Function: readColumnarGel
Property window:
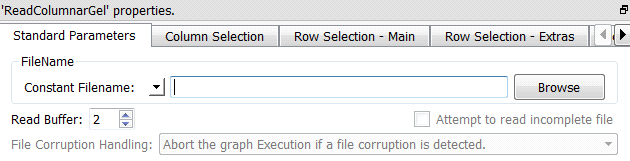
Short description:
Reads a table from a “.cgel_anatella” file.
Long Description:
Reads a table from a “.cgel_anatella” file (and from the associated “column set” data files “*.NNN.cs_anatella”). See section 5.1.1. to have more information on how to specify the filename of the “.cgel_anatella” file (i.e. You can use relative path, wildcards, and Javascript to specify your filename). You can connect to the input pin of the ![]() ColumnarGelFile Reader a table containing (many) filenames.
ColumnarGelFile Reader a table containing (many) filenames.
![]()
You can drag&drop a “.cgel_anatella” file from a MS-File-Explorer-Window into an Anatella-Graph-Window: This will directly create the corresponding ![]() ReadGel Action inside the Anatella graph.
ReadGel Action inside the Anatella graph.
Anatella possesses two highly-efficient proprietary file formats that allows you to handle with ease any “Big Data” problem. These two files formats are:
•“.gel_anatella” files: Optimized for speed and for low RAM consumption. Ideal when processing all the columns and all the rows inside a table. Since the “.gel_anatella” files have relatively low RAM consumption, this means that you can simultaneously open thousands of them (for example, when using the ![]() mergeSortInput Action: see section 5.2.15.).
mergeSortInput Action: see section 5.2.15.).
•“.cgel_anatella” files: Optimized to have the best speed and the mimimum quantity of I/O transfer. To minimize the quantity of bytes extracted from the Hard drive, you can parameter the ![]() ColumnarGelFile Reader to read a (small) subset of the columns and a (small) subset of the rows: i.e. The smaller the subset, the higher the processing speed.
ColumnarGelFile Reader to read a (small) subset of the columns and a (small) subset of the rows: i.e. The smaller the subset, the higher the processing speed.
The Columnar Gel files have the same set of great features as the simpler “.gel_anatella” files: More precisely:
•The Columnar Gel files contain the same meta-datas as inside a simple “.gel_anatella” file (i.e. To remind you, these meta-data are: the column’s names, column’s type: Key, Float or Unknown/String, the sorting flags, the “complete” flag), plus some more meta-data that allows to only extract out of the hard drive a subset of the columns and a subset of the rows (to reduce the required I/O and gain speed).
•All the data inside the files are compressed. In opposition to the simpler “.gel_anatella” file (that uses only one generic data compression algorithm), inside the “cgel_anatella” columnar gel file, we use different compression algorithms for the different data types, achieving a (slightly) better compression.
•All I/O algorithms are asynchronous (i.e. non-bloking) I/O algorithm:
oInside the ![]() ColumnarGelWriter Action, we have an asynchronous (i.e. non-bloking) I/O algorithm to create the “.cgel_anatella” files and the “.cs_anatella” files. Furthermore, we can decide to use many threads/CPU’s to create our files, to still increase writing speed.
ColumnarGelWriter Action, we have an asynchronous (i.e. non-bloking) I/O algorithm to create the “.cgel_anatella” files and the “.cs_anatella” files. Furthermore, we can decide to use many threads/CPU’s to create our files, to still increase writing speed.
oInside the ![]() ColumnarGelFile Reader, we have an asynchronous (i.e. non-bloking) I/O algorithm to read the “.cgel_anatella” files and the “.cs_anatella” files (
ColumnarGelFile Reader, we have an asynchronous (i.e. non-bloking) I/O algorithm to read the “.cgel_anatella” files and the “.cs_anatella” files (
See the section 5.2.6.2. about asynchronous (and synchronous) I/O algorithms.
Asynchronous I/O algorithms allows very fast reading speed.
•It’s possible to read “incomplete” columnar gel files: See section 5.2.6.1. for more information about this subject.
•It’s possible to read “corrupted” columnar gel files: See section 5.2.6.3. for more information about this subject.
As you can see the “.cgel_anatella” Columnar Gel files seems to improve on all aspects compared to the simpler “.gel_anatella” files. The “.gel_anatella” files have still the “upper hand” in the following situations:
•When the number of columns is large (>300), the RAM consumption required to read&write columnar gel files might be prohibitive. This means that, for most predictive datamining tasks (that requires a large number of columns), you’ll still use the simpler, row-based “.gel_anatella” files. For classical Business-Intelligence tasks, we are usually using a small quantity of columns (out of many) and thus the “.cgel_anatella” Columnar Gel files are usually better.
•When you need to read many data tables simultaneously (i.e. when the number of simultaneously opened data-file is above 40: For example, when using the ![]() mergeSortInput Action), it’s better to use the simple “.gel_anatella” files (rather than the “.cgel_anatella” columnar gel files) because the simple “.gel_anatella” files require a lot less RAM to operate.
mergeSortInput Action), it’s better to use the simple “.gel_anatella” files (rather than the “.cgel_anatella” columnar gel files) because the simple “.gel_anatella” files require a lot less RAM to operate.
A complete explanation on the proper usage of all the parameters of the ![]() ColumnarGelFile Reader is given the section 5.26.3. about the
ColumnarGelFile Reader is given the section 5.26.3. about the ![]() ColumnarGelWriter Action.
ColumnarGelWriter Action.