Icon: ![]()
Function: writeColumnarGel
Property window:
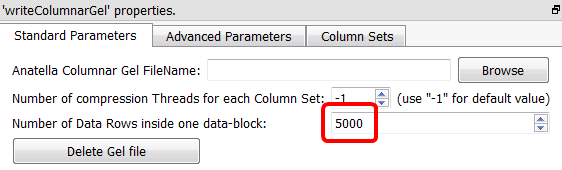
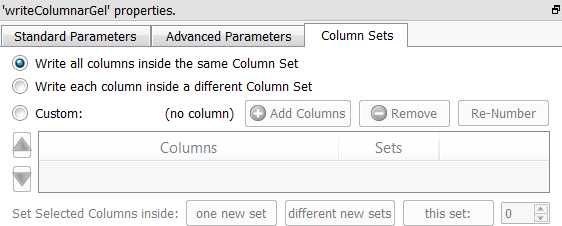
Short description:
Write a table to a columnar “.cgel_anatella” file.
Long Description:
Write a table to a columnar “.cgel_anatella” file (and to the associated “column set” data files “*.NNN.cs_anatella”). Please refer to section 5.1.1 to have more information on how to specify the filename of the .cgel_anatella file (i.e. You can use relative path and Javascript to specify your filename).
The ![]() writeColumnarGel Action has all the nice functionalities from the simpler
writeColumnarGel Action has all the nice functionalities from the simpler ![]() WriteGel Action: In particular:
WriteGel Action: In particular:
•Inside the ![]() writeColumnarGel Action, all the I/O routines are also non-blocking: See the previous section (i.e. the comments at the end of the previous section 5.27.2.) about “blocking and non-blocking I/O algorithms”.
writeColumnarGel Action, all the I/O routines are also non-blocking: See the previous section (i.e. the comments at the end of the previous section 5.27.2.) about “blocking and non-blocking I/O algorithms”.
•If the compression algorithm used to create the “.cgel_anatella” becomes the bottleneck inside the data-transformation-graph, you can decide to use more threads (and thus more computing power) to compress faster the data, to remove any bottleneck.
The Columnar file format is optimized to reduce to the minimum the quantity of bytes extracted from the Hard Drive when reading a subset of the columns and a subset of the rows from the columnar file (i.e. this is the main objective of the “columnar” format!).
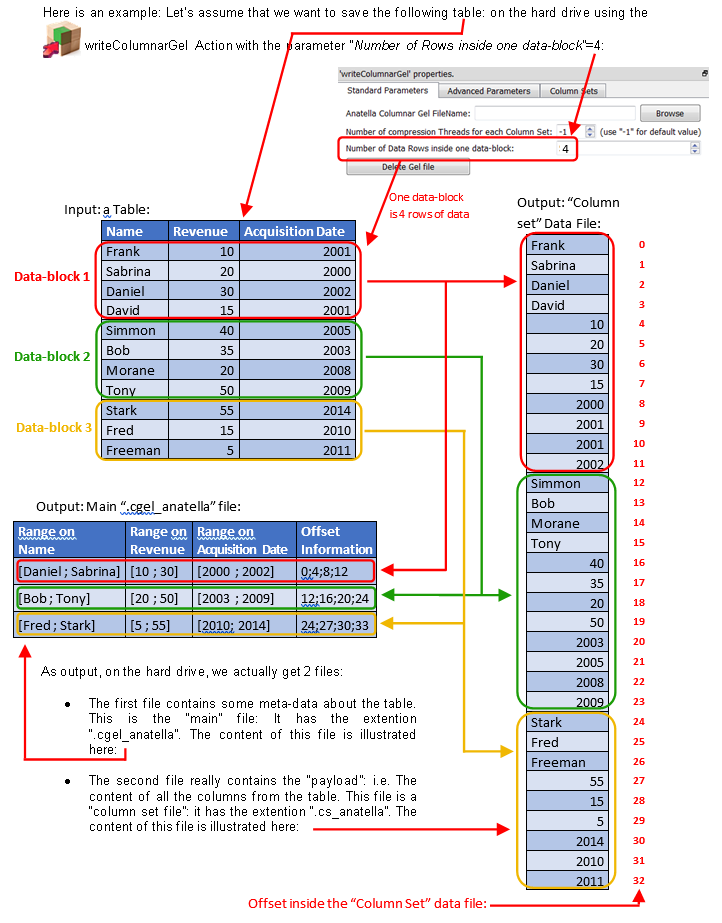
Just as a comparison, the row-based “.gel_anatella” file format is illustrated this way:
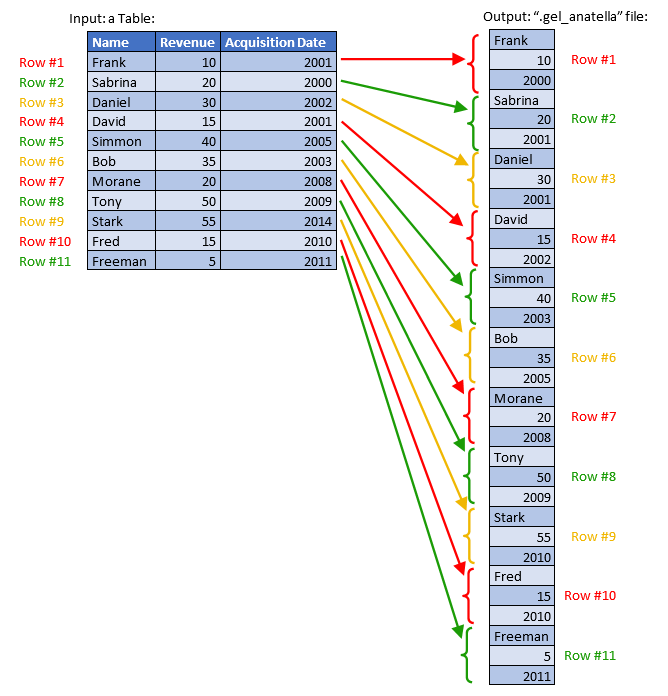
Let’s now assume that we want to read the above table using the columnar files illustrated inside the above drawing (i.e. using the “.cgel_anatella” file and the “.cs_anatella” file). More precisely, we want to:
•Read the column “Name”
Looking inside the main “.cgel_anatella” file (more precisely, looking at the field “Offset Information”), we see that the content of the “name” column is stored inside the “column set” file at some precise locations (i.e. at the offsets ((0 to 4), (12 to 15), (24 to 27)) inside the “column set” file). Thus, we’ll only extract out of the Hard Drive, from the “column set” file, these precise locations (in reality, in addition to extracting data from the hard drive, we also need to decompress the data, because all the columnar files are compressed) and we get our result: The complete “name” column.
Please note that we did NOT read the complete “column set” file to get the “name” column (i.e. we skipped extracting the data at the offsets ((4 to 12) and (15 to 24)). This is where the real “speed gain” comes from, when using the columnar file: You don’t have to read the whole file to get one column.
Unfortunately, the story does not ends here. Although you specifically asked to the Microsoft Windows Operating System to skip reading the bytes located at the offsets ((4 to 12) and (15 to 24)), the Hard Drive is still reading these bytes!!? How is that possible? This odd behavior originates from an “optimization” performed at the OS-level.
Let’s step back a little and ask ourselves the following question:
“Let’s assume that we just read 2GB out of a 10GB file.
What are now the chances that we’ll read one more megabyte?”.
These chances are pretty high: I would say that there is 99% chance that we’ll continue reading the file. Based on this simple principle, Microsoft decided to modify the “internal routine that reads the files from the hard drive” to read “in advance” the next bytes of the file (although you didn’t specifically asked for these bytes *yet*). In this way, when your program finally asks for these bytes, there are already available in RAM, ready to be used. This is a nice simple “trick” to increase disk access speed.
![]()
Actually, this “trick” to increase the hard drive efficiency is used by both Microsoft Windows and by some Manufacturers of Hard Drive (inside their Low-Level Hardware Drivers). No all manufacturers use it (because it’s not trivial to code because it implies some intricate knowledge of the NTFS disk structure), but still…
Because of this “trick”, it’s actually the same time to read the whole data file from start to finish than to read the file “skipping” some bytes from time-to-time: This “trick” means that the columnar-speed-gain is basically lost! (…at least under Windows: Linux does not have this very nice trick, up to now).
To really benefit from the columnar-speed-gain, we need to place the content of each column inside different (“Column Set”) data file, like this:

This second solution is faster (and thus better). It has 4 files (instead of 2):
oThere is always the main “.cgel_anatella” file, just as before.
oThere are three “Column set” data files (one file for each different column).
Now, when we want to read the “Name” column, we’ll only extract from the Hard Drive the bytes from the “Column set File 0” (and also the bytes from the main “.cgel_anatella” file, but this is negligible). When using this second solution, the “trick” performed by the Microsoft Windows Operating Systems plays in our advantage and really increase the reading speed (because it reads “in advance” the bytes that we really need). Everything now *seems* ok, but the story is not yet finished.
•Read the “Name” column and the “Revenue” column.
Let’s assume again that each column is stored inside its own “column set” file. Thus, we again have:

To extract from the Hard Drive the content of the “Name” column and of the “Revenue” column, we must read 2 different files. This means that the “Heads of the Hard Drive” will have to physically “jump” from one file to the other and this is typically a very slow operation that might producing, at the end, a slower overall reading speed.
![]()
Here is a photograpy of one of the heads (There are usually many heads inside a hard drive) that read the data out of the hard drive disk (platters):

Thus, we can’t have too many different “column sets” data file opened at the same time (because “jumping” from one file to the other is actually slowing us down). Thus, we need to find a good compromise:
oToo many data files (e.g. Each different column is inside a different “column set” data file) slows us down (because the “hard drive heads” are “jumping around”).
oToo few data files (e.g. All the columns are inside one “column set” data file) is bad because we’ll involuntary extract from the hard drive many bytes that we don’t need.
You can easily test different “compromises” using the Anatella interface (to find the one that leads to the best performances). This interface allows you to quickly & easily, in a few mouse-clicks, select which columns are placed inside which “column set” data file. For example:
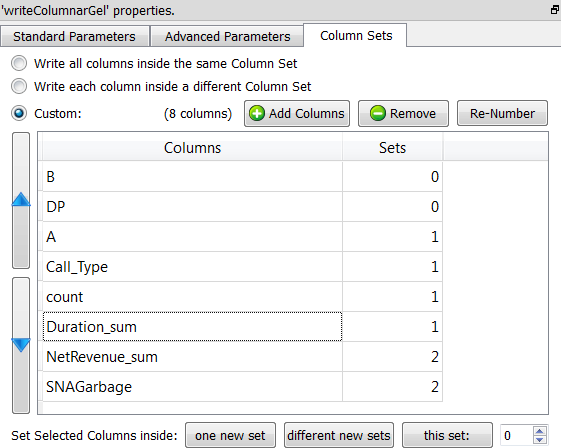
… The above screenshot will produce 3 “column set” data files. The first “column set” data file (with index 0) contains only the columns named “B” and “DP”.
As a general “rule-of-thumb”, you can follow these advices:
oGroup together inside the same “column set” the columns that are used very often together inside your aggregations&data-transformations.
oPut aside in a separate “column set” the columns that seldom used (to avoid losing time reading them involuntarily because of the Microsoft Windows “Read Ahead Trick”). For example, the column named “comments” is typically not very often used inside large queries/data-transformations and should be “set aside” inside its own column set.
oIf you are using SSD drives, you are lucky: SSD drives do not have any “hard drive heads” to move and so there is practically no penality when reading simultaneously from many different files. When using SSD drives, the best option is nearly always: “Write each column is inside a different “column set” data file”. This is easy! J
oIf you are using “Old”, classical Magnetic Drives, try to reduce to the minimum the number of “column sets” data files.
•Read the rows for which “Acquisition Date>=2011”
To accomplish that without the old “.gel_anatella” row-base gel file, you’ll typically do the following:
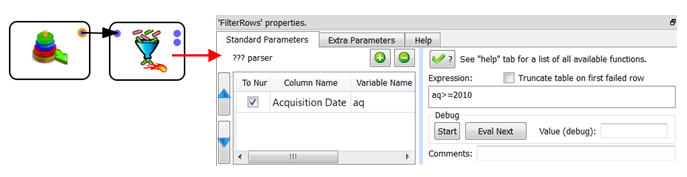
This means that you’ll read the whole table out of the hard drive and, therafter, “filter out” the rows that do not verify your condition (i.e. you’ll remove the rows that have “Acquisition Date”<2011).
With the new Columnar Gel File, we’ll have:
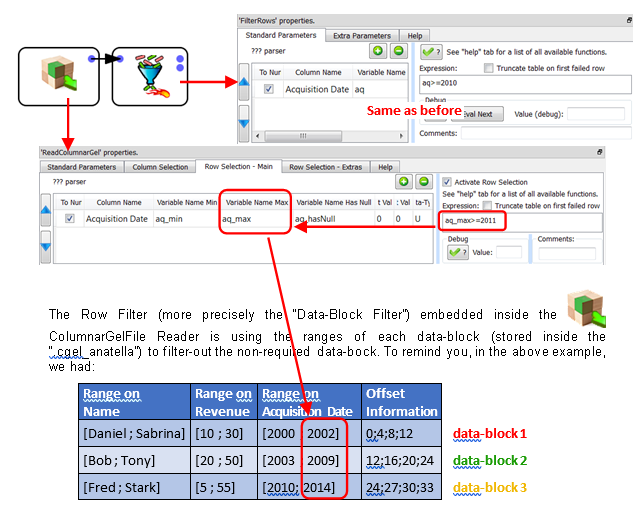
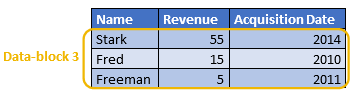
The only data-block that passes successfully the test is the “data-block 3” (because, for the other data blocks, we have “2002>=2011 is false” and “2009>=2011 is false”): This is the only data-block that is actually extracted from the Hard Drive.
The content of the “data-block 3” is:
The ![]() FilterRows Action following the
FilterRows Action following the ![]() ColumnarGelFile Reader is still required to remove the row containing “Fred”. We obtain as final output:
ColumnarGelFile Reader is still required to remove the row containing “Fred”. We obtain as final output:

The “Data-Block Filter” embedded inside the ![]() ColumnarGelFile Reader allows you to avoid extracting from the Hard Drive all the non-required data-blocks, to reduce to the minimum the I/O performed by Anatella, still increasing speed.
ColumnarGelFile Reader allows you to avoid extracting from the Hard Drive all the non-required data-blocks, to reduce to the minimum the I/O performed by Anatella, still increasing speed.
And finally, a small note about the parameter “Number of Rows inside one data-block”:
The optimal value of this parameter is again a compromise:
•A large value means a large RAM memory consumption (both at the time of saving the file on the Hard Drive and at the time of reading the file from the Hard Drive).
(The large RAM consumption originates from the fact that the ![]() writeColumnarGel Action must use large data-blocks in RAM memory before “flushing” them column-by-column on the hard drive.)
writeColumnarGel Action must use large data-blocks in RAM memory before “flushing” them column-by-column on the hard drive.)
•A small value means that the “Data-Block Filter” embedded inside the ![]() ColumnarGelFile Reader won’t be very efficient: One test of the data-block-filter will only allow to “skip” the extraction of a small number of rows (and thus a large number of tests will be required to find the exact rows to extract).
ColumnarGelFile Reader won’t be very efficient: One test of the data-block-filter will only allow to “skip” the extraction of a small number of rows (and thus a large number of tests will be required to find the exact rows to extract).