Icon: 
Function: upsertOleDB
Property window:
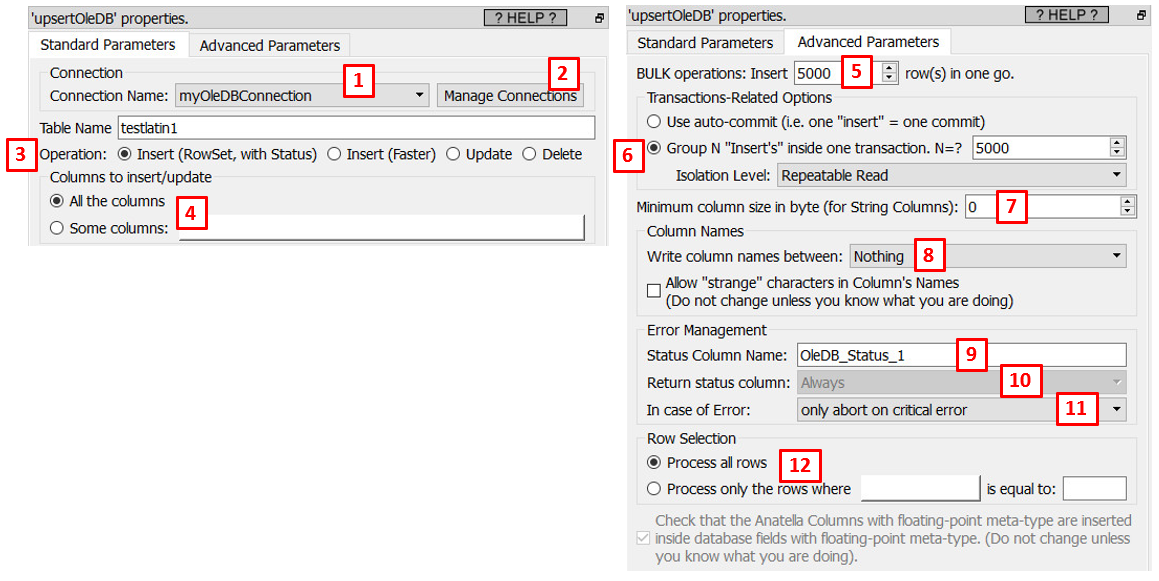
Short description:
Insert/update/Delete some rows inside a relational database using the OleDB driver.
Long Description:
Please refer to the section 5.1.7. for more informations about the usage of the OleDB protocol to connect Anatella to databases.
For this action to work, you need first to setup an oleDB connection string: use P1 and P2 to do so.
Use the parameter P3 to choose the operating mode: these modes are self-explanatory. All these operating modes (with the exception of the first one that is named “Insert(Row, with Status)”) are actually executing many “batch” of insert/update/delete SQL commands (the size of these “batch” is defined using parameter P5). When the “batch” size is P5=“1” (i.e. when we execute all the SQL commands one-by-one), the OleDB drivers always gives us the final status after the execution of the SQL command: i.e. we know if the insert/upate/delete operation succeeded. There are many reasons why a SQL command can fail: The most common causes of failure are:
•You try to INSERT a row inside a table that contains a primary key column that has a unicity constraint. This means that the newly inserted row cannot have a primary key whose value is already present inside the table. If that’s the case, the INSERT operation will fail.
•You try to write a very long string (e.g. with a length of 20) inside a column that only accepts short strings (e.g. declared as “nvarchar(10)”).
When the “batch” size is larger than one, the OleDB driver will return the final status, after the execution of the SQL command, only if the OleDB parameter named "DBPROP_IMultipleResults" parameter is TRUE. You can change this OleDB parameter using P10:
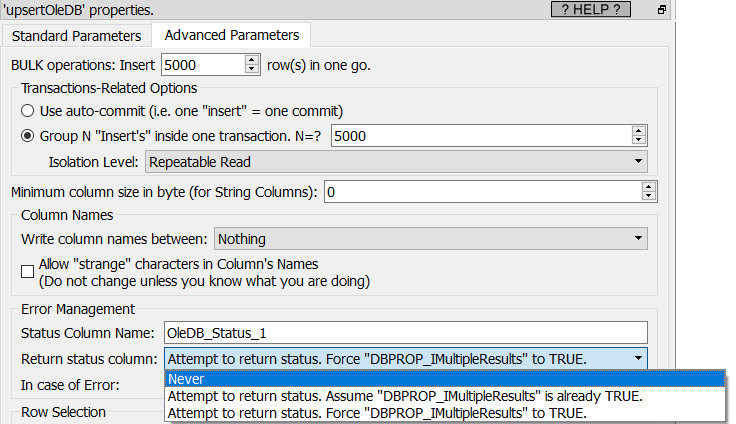
Unfortunately, as of February 2021, all the OleDB drivers that we tested (MS-SQLServer and Oracle) only accept P10=“Never”: see the sections 5.1.7.1. and 5.1.7.2. for more details on this subject.
The operating mode (selected using P3) that is named “Insert(RowSet, with Status)” is not executing any SQL commands: it’s working in a totally different way: The way that it’s working is the following: The upsertOleDB action reads rows from the input pin and stores them inside a small “internal” table (named a “RowsSet”) that is located in the RAM of the Anatella server (to do so, it’s using the IRowSetUpdate::InsertRow() instruction). When this small “internal” table reaches a total of P5 rows, Anatella sends in “one go” the whole “internal” table to be INSERTED inside the database (using the IRowetUpdate::Update() instruction). This operating mode has the potential to be extremely fast since it does not have to parse any complex SQL query: it’s just a copy/paste of some rows from Anatella to the database (it still fully supports “Transactions”). Unfortunately, the implementation of this operating mode inside the MS-SQLServer oleDB driver and inside the Oracle oleDB driver is of very poor quality and this mode is actually much slower than the “normal” INSERT mode that is based on a batch of SQL commands. So, this mode is finally quite a disappointment. The only reason to use this mode is that it always provides a “status” column, so that we can easily check which INSERT statement failed or succeeded (this “status” column is typically missing when executing some “batchs” of INSERT SQL statement).
The output table of the upsertOleDB action is an exact copy of the input table with the small exception that a “Status” column is added (more precisely, the presence of this “status” column depends on the parameter P10). This “Status” column contains the following value:
•OK: The insert/update/delete operation succeeded.
•ERROR: The operation failed.
•SKIPPED: The row was skipped because of the parameter P12.
•TOO_LONG: One of the columns to send to the database is too long to be inserted inside a “too small” column from the database. Sometime, this error can be solved very easily: i.e. Just enter a very large number inside the parameter P7.
•NO_STATUS: You selected P10=“Attempt to return status…” but the OleDB driver did not return any status. If you see NO_STATUS inside one cell of the status column, this means that the whole content of the status column is erroneous.
When Anatella opens a connection to a database it attempts to guess the size of all the columns to insert/update inside the database. Unfortunately, this “guess” is impossible for some columns (e.g. the guess fails for all the columns declared as “nvarchar(max)”). In such situation, Anatella assumes that the “unguessable” columns have a maximum length of 5,000 unicode characters (or 10,000 bytes). When this assumption is erroneous, the graph execution stops. You can use the parameter P7 to correct this assumption. Just increase the parameter P7 up to the point you don’t get any error or abort during the execution of the graph.
The parameter P11 has 3 possible values:
•“Always abort”
As soon as one insert/update/delete fails, then the whole Anatella graphs stops.
•“Only abort on critical errors”
The whole Anatella graphs stops when there is an irrecuperable errors that prevents any connection to the database to work anymore. In particular, the graph execution won’t stop when Anatella receives such errors:
oDB_E_CANTCONVERTVALUE
The data value for one or more columns couldn't be converted for reasons other than sign mismatch or data overflow.
oDB_E_DATAOVERFLOW
Conversion failed because the data value for one or more columns overflowed the type used by the database. This typically happens when we try to write a “large” string in a “small” database column.
oDB_E_INTEGRITYVIOLATION
The data violated the integrity constraints for one or more columns of the rowset. This typically happens when we try to write a value inside a primary key column that is already present inside another row of the same table.
For uncritical errors, the graph execution won’t stop but:
oThe status column will contain “ERROR” or “TOO_LONG”.
oThe Anatella log window will contain a small text that explains the nature of the error. This text is generated by the OleDB driver and it’s usually not very understandable. To get a better explanation of the error, you should set P5=1 because, in this case, the OleDB driver usually returns more comprehensible error messages.
•“Never Abort”
This is self-explanatory.
The parameter P6 allows to use “Transactions” to insert/update/delete rows inside your database. Usually, it’s better to avoid to use any Transactions at all: i.e. On most databases, using the “auto-commit” option (i.e. no Transaction at all) is the fastest option because it means that the database does not have to manage all the ACID properties related to the processing of TRANSACTIONS. This is not always true: See the section 5.27.4. for a more detailed discussion on this subject. When the Transactional system is enabled, you can choose between different isolation levels:
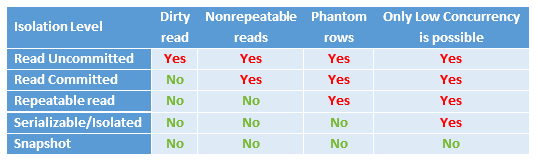
In the table above, the title of the columns represents the common problems that can (unfortunately) occur during the handling of a transaction. These problems are:
•Dirty Read
A transaction that exhibits this phenomenon has very minimal isolation from concurrent transactions. In fact, it can see changes that are made by those concurrent transactions even before they commit.
For example, suppose that transaction T1 performs an update on a row, transaction T2 then retrieves that row, and transaction T1 then terminates with rollback. Transaction T2 has then seen a row that no longer exists.
•Nonrepeatable reads
If a transaction exhibits this phenomenon, it might read a row once. Then, if the same transaction attempts to read that row again, the row might have been changed or even deleted by another concurrent transaction. Therefore, the Read is not (necessarily) repeatable.
For example, suppose that transaction T1 retrieves a row, transaction T2 then updates that row, and transaction T1 then retrieves the same row again. Transaction T1 has now retrieved the same row twice but has seen two different values for it.
•Phantom rows
When a transaction exhibits this phenomenon, a set of rows that it reads once might be a different set of rows if the transaction attempts to read them again.
For example, suppose that transaction T1 retrieves the set of all rows that satisfy some condition. Suppose that transaction T2 then inserts a new row that satisfies that same condition. If transaction T1 now repeats its retrieval request, it sees a row that did not previously exist, a phantom.
•Only Low Concurrency is possible
The “snapshot” isolation level avoids almost all locking inside the database by using a technique named “row versioning”. When there are no “locks” used, the database is able to process more operations simultaneously, providing better performances under heavy, concurrent load.
The sections 5.27.4.1. and 10.10 contains more interesting and relevant insights that are related to the management of databases with Anatella.