Icon: ![]()
Function: BulkUpload
Property window:
Short description:
Upload a table to RedShift.
Long Description:
With the standard redshift ODBC driver, it’s not possible to insert rows into RedShift. If you want to insert rows into a table inside Redshift, you need to use the current ![]() Action. This action proceeds in 5 steps:
Action. This action proceeds in 5 steps:
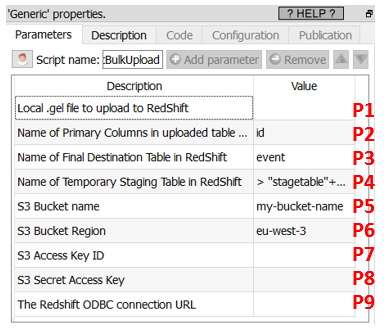
1.Using the user-provided .gel file (parameter P1), it creates on the local hard drive a temporary csv file with all the data to copy into RedShift.
2.It copies the temporary csv file from the local hard drive into a S3 bucket.
3.It copies the temporary csv file from the S3 bucket to a Staging Table (parameter P4) into RedShift.
4.It copies the content of the Staging Table to the Final Table (parameter P3) into RedShift. Before the copy starts, to avoid to get any Primary Keys “in double” inside the Final Table, it removes from the Final table all the rows that have the same Primary Keys as the Primary Keys inside the Staging table. The name(s) of the Primary key column(s) is(are) given in parameter P2.
5.Cleaning: It deletes the staging table, the csv file inside the S3 bucket and inside the local hard drive.
To be able to connect to your S3 bucket storage, you need to get from Amazon these 4 parameters:
1.Parameter P5: your “Bucket Name”
2.Parameter P6: your “Region”
3.Parameter P7: your “Access Key ID”
4.Parameter P8: your “Secret Access Key”
Please refer to the section 5.23.6. for the procedure to get these 4 parameters.
To be able to connect to your RedShift database (to run the SQL command to import the data from the S3 bucket), you need to:
1.Download & install the ODBC drivers for RedShift: see section 5.1.6.11. for more details about this step.
2.Get the ODBC connection URL to connect to your Redshift database: Enter this URL as the Anatella parameter P9. The procedure to get this ODBC connection URL is given here:
https://docs.aws.amazon.com/redshift/latest/mgmt/configure-odbc-connection.html#obtain-odbc-url
Typically, this ODBC connection URL looks like this:
Driver={Amazon Redshift (x64)}; Server=redshift-cluster-1.chhydacago64.eu-west-3.redshift.amazonaws.com; Database=dev; UID=<my_user>; PWD=<my_password>