|
<< Click to Display Table of Contents >> Navigation: 5. Detailed description of the Actions > 5.16. TA - Operational Research > 5.16.2. Dataset Reduction (High-Speed
|
Icon: ![]()
Function: DatasetReduction
Property window:
Short description:
TODO.
Long Description:
Reduce the dataset by applying a KNN segmentation.
When dealing with transactional data, sampling (even stratified sampling) will force us to lose precious information when we create predictive models. One way to avoid this problem (while keeping the dataset reasonable) is to regroup transactions of customers that look very similar in terms of purchase behaviour.
The stratified sampling is appropriate when we want to keep representativity of a sample for inferrence purpose, but there is absolutely nothing that suggest that two people of the same age, region and ehtnic origin have the same tastes or purchase behavior. On the other hand, it doesn’t make a large difference that on Fridays, Daniel buys 6 beer, 2 Camembert and 1 bread, while Frank buys 2 beers, 2 Brie and 1 bread. They essentially have the same purchase behaviour.
This technique will reduce the dataset by identifying transactions that are seemingly the same.
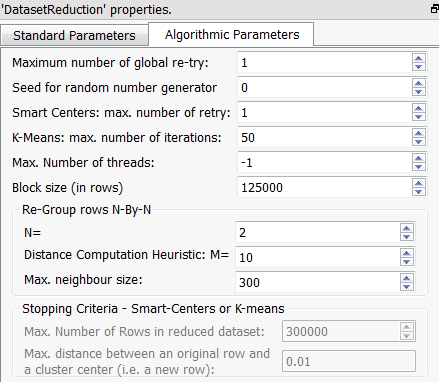
Parameters:
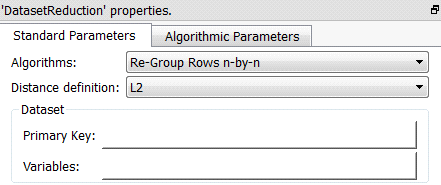
Algorithms:
•Re-group rows n by n
•Smart Centers only
•K-Means only
•Smart Centers + K-Means
Distance Definition:
•L2
•L1
•0.9* L_Infinity + 0.1 * L1
•0.95 * L_Infinity + 0.05 * L1
Primary key: unique transaction identifier
Variables: set of columns that are relevant to define the distances between rows.