|
<< Click to Display Table of Contents >> Navigation: 5. Detailed description of the Actions > 5.6. Cleaning > 5.6.1. Naïve Deduplicate (High-Speed
|
Icon: ![]()
Function: NaiveDeduplicate
Property window:
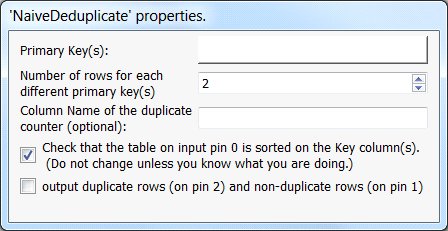
Short description:
Remove Duplicate rows.
Long Description:
This action remove duplicates rows.
Two rows are considered as "duplicate" when all their primary key(s) match.
The input table of this action must be sorted on its primary key(s).
Only the primary key(s) are checked to search for duplicates, it means that two rows that have :
•different values on NON-primary columns.
•the same primary key(s).
… will still be “de-duplicated” (to only keep one row).
![]()
Pre-requisite
The input table of this action must be sorted on its primary key(s).
The ![]() NaïveDeDuplicate Action is very often combined with the
NaïveDeDuplicate Action is very often combined with the ![]() Flatten Action. For example, let’s say that we want to know the 2 most purchased products in each department of the store. We’ll have:
Flatten Action. For example, let’s say that we want to know the 2 most purchased products in each department of the store. We’ll have:
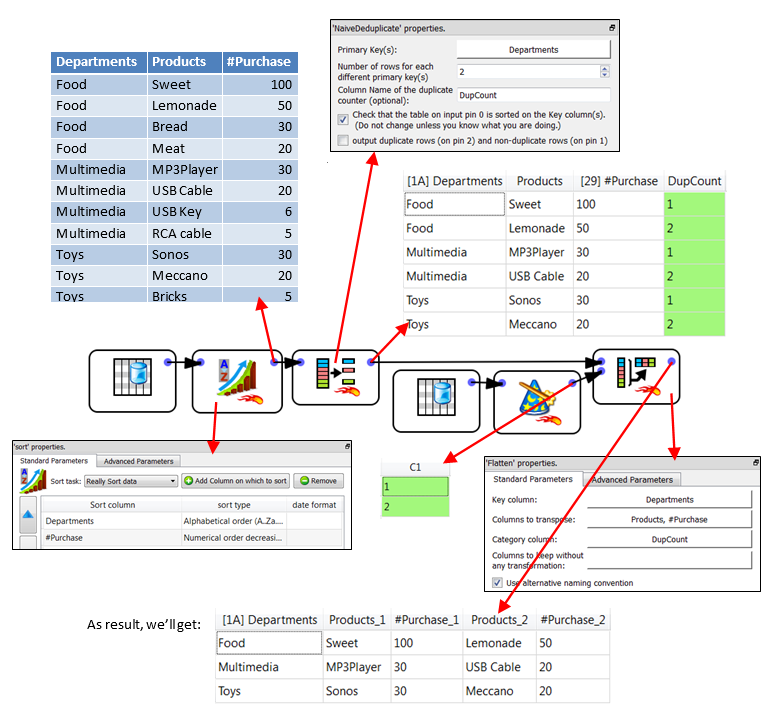
E.g. For the “Food” department, the two most purchased products are “Sweets” (with 100 sales) and “Lemonade“ (with 50 sales).
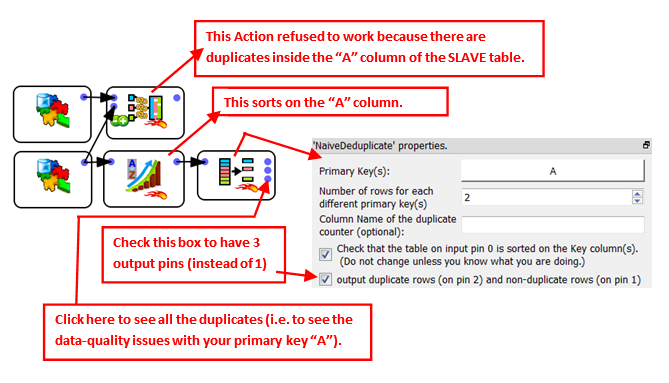
The ![]() NaïveDeDuplicate Action is also very often used to investigate data quality issues initially detected with the
NaïveDeDuplicate Action is also very often used to investigate data quality issues initially detected with the ![]() MultiJoin Action or the
MultiJoin Action or the ![]() FilterOnKey Action. These 2 actions requires no duplicates values inside the “key” column of the SLAVE tables. When a key-duplication is detected, you can see the duplicates in the following way:
FilterOnKey Action. These 2 actions requires no duplicates values inside the “key” column of the SLAVE tables. When a key-duplication is detected, you can see the duplicates in the following way: