Icon: ![]()
Function: readSQLite
Property window:
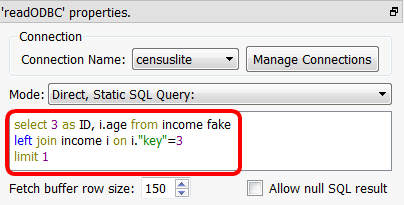
Short description:
Launch the execution of SQLite SQL statement(s) based on (several) SQLite database(s).
Long Description:
SQLite files are self-contained, serverless, zero-configuration, transactional SQL databases.
SQLite is the most widely deployed SQL database engine in the world.
SQLite is an embedded SQL database engine. Unlike most other SQL databases, SQLite does not have a separate server process. The SQLite engine runs directly inside the Anatella process.
The SQLite engine reads and writes directly to ordinary disk files. A complete SQL database with multiple tables, indices, triggers, and views, is contained in a single disk file. The database file format is 100% cross-platform. Inside SQLite, All transactions are ACID (Atomicity, Consistency, Isolation, Durability) even if interrupted by system crashes or power failures. This make SQLite databases particularly resilient and reliable. These features make SQLite a popular choice as a convenient file format to exchange data between different applications.
Although the SQLite engine is one of the fastest database engine available, you should NOT use it to perform “heavy” data transformations on Big Data. If you need to perform large and complex data transformations, avoid using the SQLite engine because it’s a lot slower (and less scalable) than the standard Anatella data transformations (i.e. the Anatella Actions). The SQLite engine has been included inside Anatella mainly for the purpose of “easy data exchange” between applications (and not to perform heavy-duty data transformations using SQL).
![]()
If you need to perfom large data transformations, you should always use the Anatella Engine rather than the SQLite Engine. There exists however one data-transformation-operation where the SQLite engine *might* be faster than the standard Anatella engine: It’s the ![]() rowFilter Action. Inside Anatella, the
rowFilter Action. Inside Anatella, the ![]() rowFilter Action always performs a “full table scan”: It reads all the rows of the input table and outputs only the desired rows (This is because the .gel_anatella file do not contain any INDEXING structure of any kind). If you need to output a very small number of rows, it might be faster to create an INDEX on the table to “filter” and use this INDEX to find the desired rows to output (This avoids reading the whole table because you only need to read the INDEX data and the selected rows). With the SQLite engine, you can create INDEXES on tables and use these INDEXES (inside a SQL statement) as a substitute to the
rowFilter Action always performs a “full table scan”: It reads all the rows of the input table and outputs only the desired rows (This is because the .gel_anatella file do not contain any INDEXING structure of any kind). If you need to output a very small number of rows, it might be faster to create an INDEX on the table to “filter” and use this INDEX to find the desired rows to output (This avoids reading the whole table because you only need to read the INDEX data and the selected rows). With the SQLite engine, you can create INDEXES on tables and use these INDEXES (inside a SQL statement) as a substitute to the ![]() rowFilter Action. Of course, if the
rowFilter Action. Of course, if the ![]() rowFilter Action outputs anyway 95% of the rows of the input table, this substitution makes no sense (because, in such a case, a “full table scan” approach is more efficient than an INDEX-based approach). One last alternative is to use a columnar “.cgel_anatella” file. Columnar files are also able to filter rows very efficiently: See the example named “Read the rows for which ‘Acquisition Date>=2011’” inside section 5.26.3. for more information about this subject.
rowFilter Action outputs anyway 95% of the rows of the input table, this substitution makes no sense (because, in such a case, a “full table scan” approach is more efficient than an INDEX-based approach). One last alternative is to use a columnar “.cgel_anatella” file. Columnar files are also able to filter rows very efficiently: See the example named “Read the rows for which ‘Acquisition Date>=2011’” inside section 5.26.3. for more information about this subject.
SQLite databases are limited in size to 140 terabytes.
![]()
An SQLite database is not intended to be an enterprise database engine. It is not designed to compete with Oracle, Teradata or PostgreSQL. Use SQLite in situations where simplicity of administration, implementation, and maintenance are more important than the countless complex features that enterprise database engines provide. SQlite is a “small” engine (with a limited set of features) that is easy to administrate.
The major limitation of SQLite is the relatively smaller number of simultaneous users able to write inside a SQLite database. SQLite supports an unlimited number of simultaneous readers, but it will only allow one writer at any instant in time. This is usually not a problem because each application write its “changes” into the database quickly and then moves on, and no lock lasts for more than a few dozen milliseconds. But there are some applications that require more concurrency, and those applications may need to seek a different solution.
This makes SQLite databases particularly well suited for enterprise datawarehouse that are populated using batch processing with Anatella. Such datawarehouses are infrequently changed (and only in “batch”: thus there usually exists only one writer: Anatella) but, on the other hand, these datawarehouses are typically accessed daily by hundreds of users (there are thus many readers) to:
• Create reports and plot charts (using OLAP reporting tools such as
Tableau, Quickview, Mondrian, Business Objectics, etc.)
• analyse website logs,
• analyse sports statistics,
• compile programming metrics,
• analyse experimental results.
• Etc.
Since SQLite supports an unlimited number of simultaneous readers, it’s particularly well-suited for such use-cases.
According to the developpers, the three main advantages of SQLite over other solutions are: “SQLite is Small, Fast & Reliable”.
![]()
You can drag&drop a .SQLite file or a .db3_file from a MS-File-Explorer-Window into an Anatella-Graph-Window: This will directly create the corresponding ![]() SQLReader Action inside the Anatella graph.
SQLReader Action inside the Anatella graph.
There are 4 operating modes for the ![]() SQLiteReader Action:
SQLiteReader Action:
1.Direct, Static SQL Query
2.SQL Queries computed using JavaScript code
3.SQL Queries from Input Pin
4.SQL Queries from Input Pin + Input Pin Data
These are the same 4 operating modes that have been described inside the section 5.2.3. about the ![]() OleDB Reader. You can select the operating mode here:
OleDB Reader. You can select the operating mode here:
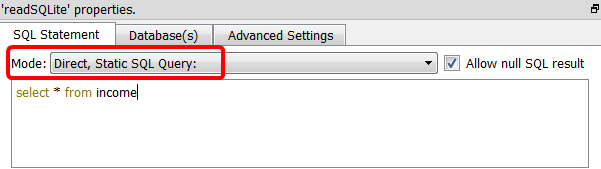
The SQLite database engine is able to compute the results of SQL queries that ares mixing different tables from different databases (i.e. from different files). This is very handy because it allows you to gain some precious computing- time because you don’t need to merge all the required tables inside one unique database file before using them: You can directly work on the “source” database files without doing any data “copy”. Click the “Add Database” button ![]() to add the different databases (i.e. the different files) that are required to write the required SQL statements.
to add the different databases (i.e. the different files) that are required to write the required SQL statements.
Inside the “Database(s)” tab, you can also select which mode is used to open a connection to a SQLite database:![]()
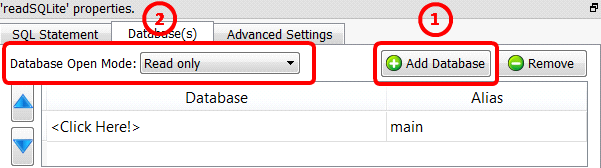
The “Database Open Modes” are:
1.“Read Only” Mode: If the database does not already exist, an error is returned.
2.“Read & Write” Mode: The database is opened for reading and writing if possible, or reading only if the file is write protected by the operating system. In either case the database must already exist, otherwise an error is returned.
3.“Read & Write – Create if not Exists” Mode: The database is opened for reading and writing, and it is created if it does not already exist.
When opening SQLite databases, you should always favour the “Read Only” mode since the SQLite database engine allows an unlimited number of “readers” but only one writer at any instant in time. When a database is opened in “Read & Write” Mode, all readers must wait until the “write” operations are complete (unless you are using the “WAL” locking mode. A writer that uses the “WAL” mode does not block the readers but it slows them down radically).
The SQLite engine runs directly inside the Anatella process (it’s an “embedded” SQL database engine). Some complex SQL queries might consume a large amount of RAM memory. To prevent the SQLite engine to use all the memory available for the Anatella process (i.e. 2GB RAM if running inside 32 bit Windows), you can set an upper bound on the memory used by the SQLite engine (see the parameter “Max Memory” inside the “Advanced Settings” tab).
The default value for the parameter “Max number of Columns in query” is 2000. You can change this value to a higher number. However, a larger number might slow down radically the time required to prepare the SQL statements (Because there are places in the SQLite code generator that are using algorithms that are O(N²) where N is the number of columns.).
When a SQLite database is opened in “Read & Write” mode, you can run SQL commands to change the content of the database. All these SQL commands are included inside one unique transaction (unless you manually add some “COMMIT; BEGIN TRANSACTION;” in the middle of your SQL code). There are basically 3 different ways used by the SQLite engine to handle transactions:
1.All rollback mechanisms are disabled (i.e. “JOURNAL_MODE=OFF"). This is very insecure but it’s also the fastest mode.
2.Standard rollback mode (i.e. “JOURNAL_MODE=DELETE”): We create a JOURNAL file that contains all the required information to undo the changes made to the database, if a rollback is required.
3.New Write-Ahead-Logging (ie. “JOURNAL_MODE=WAL”): During a transaction, we write all required changes inside a separate WAL file without modifying the database (Multiple transactions can be appended to the end of a single WAL file). At one point in time, we move all the transactions back into the database (This is called a "checkpoint").
For most operations, “Write-Ahead-Logging” (i.e. “WAL” mode) is usually a lot faster than the old Standard Rollback Mode (i.e. the “JOURNAL_MODE=DELETE”). You’ll find more information about this subject here: http://www.sqlite.org/draft/wal.html
Using the “Locking Mode” parameter inside the “Advanced Settings” tab, you can select which mechanism (i.e. JOURNAL_MODE=OFF, DELETE or WAL) is used to handle your transactions.
If your SQL statement is not returning any rows (i.e. it’s not a “SELECT” statement but it’s rather a “TRUNCATE”, “CREATE INDEX”, etc. statement), you need to check the “Allow NULL SQL result” checkbox otherwise Anatella will abort with an error message.
All normal SQL database engines use static, rigid typing. With static typing, the datatype of a value is determined by the column in which the value is stored. Static typing is also used inside Anatella.
In opposition, in SQLite, all cells inside a table can, potentially, have a different datatype (In this regard, SQLite is very similar to MS-Excel). This means that you can have a column that is filled with floating point values (i.e. the “Guessed Datatype” of the column is “REAL”) and suddenly, in the middle of the column, you find a String! Aaargh! There can be several solutions to this annoying situation:
•You declare inside Anatella that the whole column contains Strings:
![]()
In which case, you also need to specify how to convert you numbers into strings using the following formatting parameter:
![]()
Please refer to section 5.5.1.3. for more information about this formatting parameter.
•You try to cast (i.e. convert) the String to a floating point value.
In which case, you need to specify how to react if the conversion fails:

In the above example, Anatella guessed that the column datatype is “floating point” (i.e. “Double”).
How is Anatella guessing the datatype of each column?
The result of the guess can either be: TEXT, INTEGER or REAL.
Anatella analyses how the columns were declared inside the “CREATE TABLE” statement:
1.If there are no declared type for that column, we look at the first row of data:
1.1.If the cell data type is INTEGER the Guessed Type is INTEGER
1.2.If the cell data type is REAL the Guessed Type is REAL
1.3.Otherwise the Guessed Type is TEXT
2.If the declared type contains the string "INT" then:
1.4.If the declared type contains the string "POINT" then the Guessed Type is REAL
1.5.Otherwise the Guessed Type is INT
3.If the declared type contains the string "CHAR", “CLOB”, “TEXT”, “STRING” then the Guessed Type is TEXT
4.If the declared type contains the string "REAL", “FLOA”, “DOUB” then the Guessed Type is REAL
5.If the declared type contains the string "BOOL” then the Guessed Type is INT
6.Otherwise, the Guessed Type is TEXT
Anatella attempts to guess the type of each of the column. The result of the guess can be:
•A column seem to be filled with TEXT
You can control the data-type conversion of this column using this parameter:
![]()
•A column seem to be filled with INTEGER numbers:
You can control the data-type conversion of this column using this parameter:

•A column seem to be filled with REAL (floating point numbers)
You can control the data-type conversion of this column using this parameter: