Icon: ![]()
Function: readCSV
Property window:
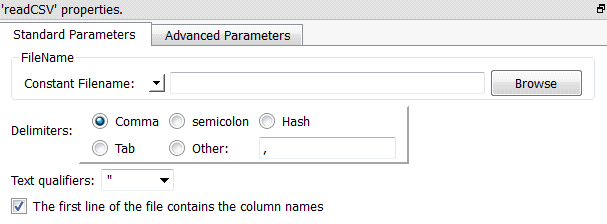
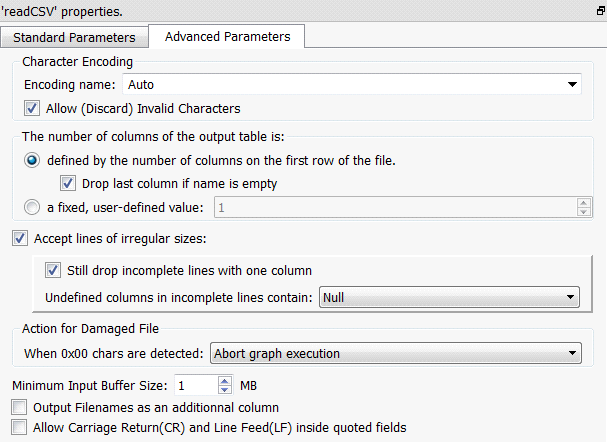
Short description:
Reads a Text/CSV file.
Long Description:
See section 5.1.1 to have more information on how to specify the filename of the Text/CSV file (i.e. you can use relative path, wildcards, and Javascript to specify your filename).
When reading a Text/CSV file, the first operation that Anatella does is to decode the characters contained inside your Text/CSV file to obtain Unicode characters. Anatella supports many different character encodings. To decode characters, Anatella uses the most extensive library about character encodings currently available (i.e. it uses the “iconv” library).
![]()
The supported character encodings are (this is a non-limitative list):
UTF16, UTF16LE, UTF16BE, UTF8, CP1252, CP819 (aka ISO-8859-1 or LATIN1), SHIFT-JIS, BIG5, GBK, CP1251 (Cyrillic), JAVA, etc.
Anatella currently supports nearly all known encodings (even the most exotic ones found inside very old servers).
If the Text/CSV file contains a BOM (Byte-Order-Mark), then Anatella will always use the character encoding that is specified inside the BOM (this takes precedence over any other user’s settings, including the “Auto” character encoding setting).
When the “Auto” character encoding is selected (i.e. this is the default choice), Anatella uses the “Local” character encoding that is defined inside the MSWindows operating system. Under MSWindows, the local/currently active “Character Encoding” is named the “Code Page” (the “Code page” is a common synonym for “Character Encoding”): More information about this subject here:
http://en.wikipedia.org/wiki/Windows_code_page
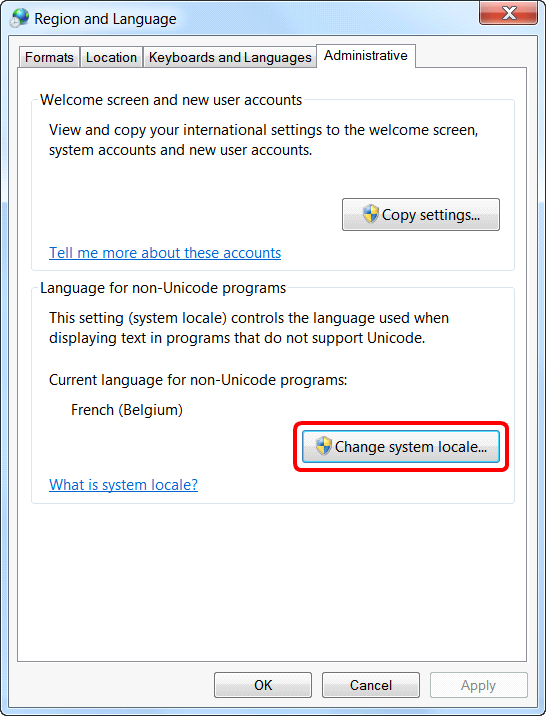
To change the active “Code Page” under MSWindows: Open the “Region and Language” settings inside the “Control Panel”, go to the “Administrative” panel and click on the “Change system locale” button: Here is a screenshot:
In opposition to many other ETL tools, all the strings inside Anatella are handled in “true” UTF-16 format. This “true” UTF-16 support guarantees you complete conformance to the universal standard in string manipulations routines (for case insensitive sort, for example).
If the extension of the Text/CSV file is RAR, ZIP, GZ or LZO then Anatella will transparently decompress the file in memory. Anatella chooses the (de)compression technique to use based on the filename extension. When Anatella uses compressed file formats, it does NOT decompress the files on the Hard Drive: Anatella decompresses the data “on-the-fly” in central core RAM memory, thus reducing:
•the load on the hard drive
•the hard-drive consumption required to do the analysis.
Usually, for classical “real world” databases, the compression/ratio of CSV file is around 90-95%. For example, the “classical Census-Income database” is originally 100MB and after compression (using WinRar) it’s only 4MB.
The ability to natively read compressed files is important when you are working on a distributed file system, with a central network drive shared by all the Anatella users. For example, when Anatella reads the “classical Census-Income database”, there will be only 4MB of data that goes “through the network cables”, instead of 100MB for another ETL that is not able to work on compressed files. Thus, Anatella is the only ETL tool that reduces substantially the load on your computer network.
Using a central repository on one shared drive is a good idea to prevent duplication of the data (to have only one version of the “truth”). You should avoid data-duplication because, if the same (supposedly) data is present on different location, there will always be a moment where all the different duplicated copies will be “out of synchronization” (i.e. different). If several analysts are working on different “out of synch.” Data (i.e. different version of the “truth”), then they might arrive to different opposing conclusions, giving you (in the worst case) contradictory advices about your business.
To summarize:
1.Anatella is one of the few ETL that *fully* supports standard Unicode characters.
2.Keeping only one central data repository ensures consistency between the different analyzes made by your team.
3.The unique compression technology of Anatella allows you to substantially reduce the load on your computer network and thus, to easily work with one central data repository.