Icon: ![]()
Function: LoopJenkins
Property window:
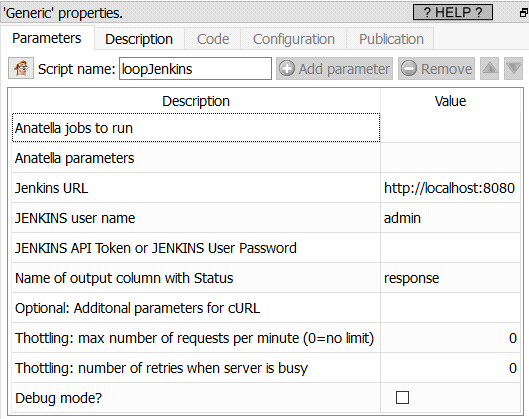
Short description:
Distributed Run of several Anatella graphs.
Long Description:
The ![]() “Loop Jenkins” action runs several Anatella Graphs using Jenkins. The principle is very similar to the
“Loop Jenkins” action runs several Anatella Graphs using Jenkins. The principle is very similar to the ![]() loopAnatellaGraphAdv action (see the section 5.21.6. to know more about this action): i.e. We also have the same “2-graphs-structure”:
loopAnatellaGraphAdv action (see the section 5.21.6. to know more about this action): i.e. We also have the same “2-graphs-structure”:
1.The first graph is the “control” graph: This graph is supervising the “loop” and decide how much iterations will be performed. This is inside the “control” graph that you’ll typically find the ![]() “Loop Jenkins” action.
“Loop Jenkins” action.
2.The second graph is the “inner part” of the loop. At each iteration of the loop, the “inner” graph is executed with a different set of values inside its “graph global parameters”: See the sections 4.7.1. and 5.1.5 to know more about “graph global parameters”.
Let’s start with a small example: These 2 “control” graphs are performing, basically, the same thing:
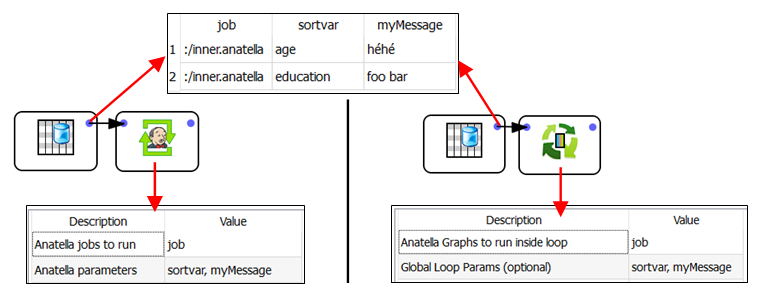
More precisely: These 2 “control” graphs are running two times (i.e. during the 2 iterations of the “loop”) the Anatella graph named “:/inner.anatella”.
For the first run, the 2 global parameters named “sortvar” and “myMessage” are initialized to, respectively, “age” and “héhé”.
For the second run, the 2 global parameters named “sortvar” and “myMessage” are initialized to, respectively, “education” and “foo bar”.
The main difference between the above two “control” graphs is the Acion that controls each iteration of the loop:
•When using the ![]() loopAnatellaGraphAdv action, the process that controls each iteration of the loop is directly the current Anatella process.
loopAnatellaGraphAdv action, the process that controls each iteration of the loop is directly the current Anatella process.
•When using the ![]() “Loop Jenkins” action, the process that controls each iteration of the loop is an exterior, third party process: it’s the Jenkins Service. This has one big advantage: When Jenkins needs to run an Anatella graph, it can freely decide to run the Anatella graph on the local PC or on any other server where Jenkins is installed&running (this is named “distributed” computations).
“Loop Jenkins” action, the process that controls each iteration of the loop is an exterior, third party process: it’s the Jenkins Service. This has one big advantage: When Jenkins needs to run an Anatella graph, it can freely decide to run the Anatella graph on the local PC or on any other server where Jenkins is installed&running (this is named “distributed” computations).
In technical terms, a server where Jenkins is installed&running (and that is thus able to execute an Anatella graph) is called a “node”.
This means that, if there are 10 nodes available, the ![]() “Loop Jenkins” action will run all the different Anatella graphs (that are given on the input pin) using all the 10 nodes (by default), dividing roughly the computing time by a factor of 10. That’s great! �
“Loop Jenkins” action will run all the different Anatella graphs (that are given on the input pin) using all the 10 nodes (by default), dividing roughly the computing time by a factor of 10. That’s great! �
In other words, the ![]() “Loop Jenkins” action allows you to run your Anatella graphs using what is called “distributed computations on several nodes”.
“Loop Jenkins” action allows you to run your Anatella graphs using what is called “distributed computations on several nodes”.
Here are some interesting facts about the ![]() “Loop Jenkins” action:
“Loop Jenkins” action:
•Before using the ![]() “Loop Jenkins” action, you must perform a very special configuration of Jenkins: See the next section (section 5.22.1.1) to know more about this subject.
“Loop Jenkins” action, you must perform a very special configuration of Jenkins: See the next section (section 5.22.1.1) to know more about this subject.
•This action does not, by default, transfer files. This means that, typically, you should save your files (i.e. your .anatella files and your .gel_anatella files) inside a “network drive” (a windows shared drive and/or a HDFS drive) that is accessible from all the nodes.
•This action “adds” the Anatella graphs to execute (obtained from the input pin) to an “Execution Queue” inside Jenkins. Thereafter, Jenkins will immediately start running all the graphs inside the “Execution Queue” using all the computing power available inside all the available nodes.
•This Action does not wait for the completion of the execution of the graphs “added” inside Jenkins. This is a completely different behavior than the ![]() loopAnatellaGraphAdv action (see section 5.21.6.), the
loopAnatellaGraphAdv action (see section 5.21.6.), the ![]() loopAnatellaGraph (see section 5.21.5) action or the
loopAnatellaGraph (see section 5.21.5) action or the ![]() ParallelRun Action (see section 5.3.3.) that are waiting for the executed (sub-) graphs to terminate before proceeding any further. You can use the
ParallelRun Action (see section 5.3.3.) that are waiting for the executed (sub-) graphs to terminate before proceeding any further. You can use the ![]() waitJenkins action (see the section 5.22.2. for more details about this action) to wait for the completion of the graphs “added” inside Jenkins.
waitJenkins action (see the section 5.22.2. for more details about this action) to wait for the completion of the graphs “added” inside Jenkins.
•You can query at any time the status of the graphs inside the “Execution Queue” inside Jenkins using the ![]() queryJenkins action (see section 5.22.3. for more details about this Action).
queryJenkins action (see section 5.22.3. for more details about this Action).