|
<< Click to Display Table of Contents >> Navigation: 5. Detailed description of the Actions > 5.12. TA - R Predictive > 5.12.7. XGBoost (
|
Icon: ![]()
Function: XGBoost
Property window:
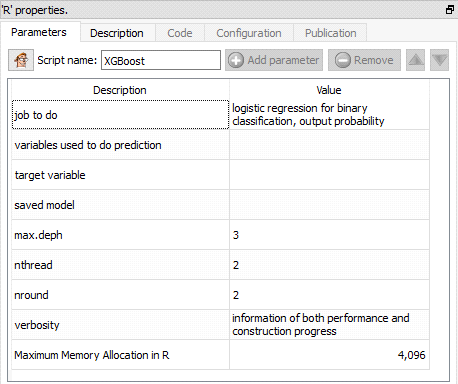
Short description:
Use the XGBoost Library.
Long Description:
Gradiant Boosting is probably the most popular algorithm in this second decade of the 21st century. The main reason is that it performed extraordinarily well in most data mining competitions. It usually ensures one of the highest accuracy in situations where the learning and test datasets are from the same time frame.
In practice, we’ve seen those models degrade very quickly over time (in a banking setting, for example, the accuracy dropped 10 points below LASSO in just two months), so we tend not to use it.
The general idea of gradient boosting is to make ensemble modeling on steroid. By putting together hundreds or thousands of weak models we can obain a fairly good classifier. This is done at the cost of interpetability.
Fit a gradient Boosting model. The different operating modes are:
•linear regression
•logistic regression
•logistic regression for binary classification, output probability
•Multiple classification
•Multiple probabilities
Note about eta: xgboost automatically does the hyperparameters optimization, but you are free to set the ETA to a lower value. ETA is the step size shrinkage (a bit similar to LASSO) used in update to prevents overfitting. After each boosting step, we can directly get the weights of new features, and it shrinks the feature weights to make the boosting process more conservative. The default value is 0.3. Lower values will take longer to compute and yield potentially overfitting models. A Value of 1 will use a “naïve gradient boosting” algorithm.